조영호님의 도메인 주도 설계의 사실과 오해 2일차를 수강하고 개인적으로 정리한 글입니다.
1일차에서는 에릭 에반스의 도메인 주도 설계라는 책을 기반으로 DDD의 본질과 구성 요소들에 대해 살펴보았다. 2일차에서는 DDD를 실제 코드로 녹여내기 위해 알아야 할 추가적인 개념과, 이를 통해 어떻게 구현해야 하는지 가이드를 제시한다.
참고로, 조영호님께서는 가이드가 정답은 아니며 수많은 구현 방식 중 하나일 뿐이므로, 너무 맹신하지는 말라고 하셨다.
1. 도메인 빌딩 블록
1일차에서, DDD의 핵심은 "동작하는 도메인 모델 만들기"라고 했었다. 이것은 곧 도메인 모델이란 설계이자 코드이며, 도메인이 변경된다는 것은 설계가 변경되는 것이고 코드 또한 변경된다는 의미이다. 궁극적으로는 코드를 읽기 쉽고 변경하기 쉽게 만들어 유지보수성을 높이는데 중요한 목적이 있다.
이에 따라, 우리는 아래 두 가지를 고민해야한다.
1. 요구사항에 적합한 모습으로 도메인을 어떻게 모델링 할 것인가? (도메인 표현)
2. 도메인을 반영할 코드를 어떻게 개발할 것인가? (생명주기 관리)
두 가지에 대한 답을 찾기 위해 도메인 주도 설계에서는 빌딩 블록이라는 개념을 제시한다.
빌딩 블록은 구현에 대한 가이드를 제공해서 전체적인 복잡도를 낮추는데 그 목적이 있다.
| 분류 | 목적 | 예시 블록 |
|---|---|---|
| 도메인 표현 | 개념·규칙을 객체로 드러내기 | Association, Value Object, Entity, Service, Module |
| 생명주기 관리 | 일관성과 트랜잭션 경계 유지 | Aggregate, Repository, Factory |
이제 빌딩 블록 각각에 대해 알아보면서 도메인 주도 설계를 어떻게 실제로 구현할 수 있는지 살펴보자.
2. 엔티티와 값 객체
엔티티와 값 객체 모두 특정 도메인 개념을 객체로 모델링하기 위한 빌딩 블록이다. 이 중 어떤 블록으로 모델링 할지는 도메인의 제약 조건과 개발 편의에 따라 선택할 수 있다. 어떤 기준으로 선택할 수 있는지 각각에 대해 알아보자.
2-1. 엔티티(Entity)
엔티티는 속성 보다는 연속성과 식별성이 중요한 도메인 개념을 표현하기 위해 사용된다.
연속성(Continuity): 객체가 계속 이동하거나 전송되어도 동일한 객체를 보장받는 특성을 의미한다. 예를 들어, 10년 만에 만난 친구의 얼굴과 나이가 바뀌어도 그가 10년 전의 그 친구임을 기억해야 한다면 이는 엔티티로 볼 수 있다.식별성(Identity): 식별자가 같아야 동일한 객체로 판단한다. 즉, 동일성(Equality)이 중요하며, 이는 equals()와 hashCode() 메서드를 통해 판단한다.
엔티티는 기본적으로 상태가 계속 변할 수 있는 객체이다. 우리가 코드를 통해 도메인 개념을 분석하고 옮길 때, "이 객체는 항상 그 객체여야 해"라는 개념이 중요한 경우에는 엔티티를 선택해야 한다.
예를 들어, "상점"이라는 도메인 개념에 대해 상호(name)를 자유롭게 변경할 수 있다는 요구사항이 있다면 아래와 같이 엔티티로 구성할 수 있다.
import java.util.Objects;
public class Shop {
private ShopId id; // 식별자
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Shop)) return false;
Shop other = (Shop) o;
return Objects.equals(id, other.id); // 식별자 기반 비교
}
@Override
public int hashCode() {
return Objects.hash(id); // 식별자 기반 해시
}
}상점은 상호(name)를 변경해도 여전히 동일한 상점이므로 별도의 식별자(id)를 두어 구별해야 한다.
따라서, equals()와 hashCode()를 식별자(id) 기반으로 재정의하여 Shop 엔티티가 연속성과 식별성을 만족하도록 하였다.
참고로,
DDD의 엔티티는 JPA 엔티티와는 다른 개념이다. JPA 엔티티는 데이터베이스 테이블과 객체 간의 데이터 매핑 관점이지만, DDD의 엔티티는 비즈니스 로직에 따른 상태 변경 관점에서 정의된다.하지만, DDD 엔티티의 비즈니스 로직을 JPA 엔티티 내부에 함께 구현할 수도 있다.즉, JPA 엔티티에 비즈니스 룰에 따른 상태 변경 로직을 넣음으로써 DDD 엔티티를 구현하는 방식이다. 개발 초기부터 불필요하게 두 객체를 나누는 것보다는, DDD 엔티티와 JPA 엔티티를 동일하게 가져가는 방식이 나을 수 있다.
2-2. 값 객체(Value Object, VO)
값 객체는 식별성이 없는 객체로, 사물의 어떤 특성이나 속성 자체를 표현하는데 중점을 두기 위해 사용된다.
동등성(Equivalence): 속성값이 같으면 동등한 객체로 판단한다. 예를 들어, 만 원짜리 지폐를 빌려주고 카카오페이로 만 원을 돌려받았을 때, 지폐의 고유 번호가 아닌 '만 원'이라는 금액 자체가 중요하다면 이는 값 객체로 볼 수 있다.불변성(Immutability): 값 객체는 상태가 변하지 않도록 만드는 것이 좋다. 각 속성은 재할당을 금지하는 final 키워드로 선언하고, 상태의 변경이 필요하다면 변경된 모습의 새로운 객체를 생성하여 반환한다.
값 객체는 엔티티의 속성을 표현하는 용도로 사용된다. 예를 들어, 상점에 "최소 주문 금액"이라는 새로운 속성이 생겼다고 가정해보자. 이를 단순히 기본 자료형인 long으로 표현할 수도 있지만, "금액"이라는 값 객체를 이용해 표현하면 의미가 더 명확해지고 "금액"과 관련된 로직을 객체지향적으로 구현할 수 있다.
public class Shop {
private ShopId id; // 식별자
private String name;
private Money minOrderPrice; // 값 객체를 이용한 금액 표현
}그리고 Money는 아래와 같이 선언할 수 있다. 예외 처리와 같은 부분은 생략하였다.
public class Money {
private final long amount; // 불변
public Money(long amount) {
this.amount = amount;
}
public Money plus(Money other) {
return new Money(amount + other.amount); // 더한 금액을 새로운 객체로 반환
}
public Money minus(Money other) {
return new Money(amount - other.amount); // 뺀 금액을 새로운 객체로 반환
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Money)) return false;
Money other = (Money) o;
return amount == other.amount; // 속성값 기반 비교
}
@Override
public int hashCode() {
return Long.hashCode(amount); // 속성값 기반 해시
}
}상점은 엔티티이므로 식별자를 제외한 속성값이 다르더라도 식별자만 같으면 동일한 객체로 취급한다. 하지만, 금액은 값 객체이므로 모든 속성값이 같아야만 동등한 객체로 취급한다. 따라서, 별도의 식별자가 존재하지 않으며 속성값들을 기준으로 equals()와 hashCode()를 재정의한다.
값 객체의 속성들은 웬만하면 불변(final)으로 설정하는 것이 구현과 유지보수 관점에서 편리하다. 한번 값 객체가 생성된 후에는 상태가 변하지 않는다는 보장이 있으므로 코드의 복잡성이 줄어들고 예측 가능성이 높아진다. 즉, 특정 값 객체가 어디에서 어떻게 변경되었는지 추적할 필요가 없다는 의미이다. 따라서, 위의 plus와 minus 메서드 같이 속성값을 변경하는 행위가 필요한 경우에는 변경된 값으로 새로운 객체를 생성하여 반환하는 방식으로 구현한다.
2-3. 실무 팁
실무에서는 애그리거트의 루트만 엔티티로 지정하고, 나머지 객체들은 값 객체로 지정하는 경우가 많다고 한다.
엔티티는 식별자를 이용해서 속성값을 변경해야 하지만, 값 객체는 그냥 다 지우고 새로 만들면 되므로 관리하기 편하기 때문이다.
따라서, 실제로는 엔티티에 조금 더 가까운 개념이라 하더라도 관리의 편의성을 위해 값 객체로 만드는 경우도 있다. 이는 어디까지나 합의의 영역이기 때문에, 어떤 도메인 개념을 엔티티로 모델링할지 값 객체로 모델링할지는 도메인 제약 조건과 개발 편의에 따라 잘 고민해야 하는 부분인 것 같다.
3. 애그리거트(Aggregate)
애그리거트는 엔티티와 값 객체들을 하나의 논리적인 덩어리로 묶어, 복잡성을 관리하고 불변식(Invariant)을 일관되게 유지하기 위한 단위를 말한다.
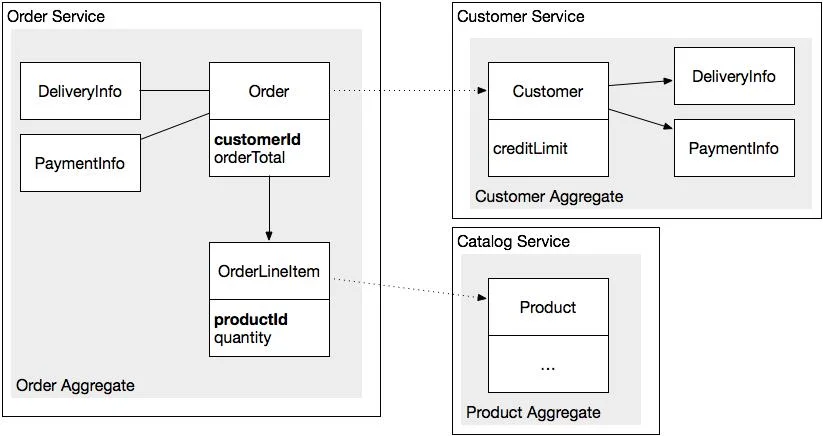
이미지 출처 : https://www.infoq.com/articles/microservices-aggregates-events-cqrs-part-1-richardson/
불변식(Invariant): 트랜잭션 일관성(Transactional Consistency)과 관련된 비즈니스 규칙을 의미하며, 애그리거트 내의 모든 객체는 이 불변식을 항상 만족해야 한다.애그리거트 루트(Aggregate Root): 단 하나만 존재하는 애그리거트의 대표 엔티티로서, 애그리거트 내부의 모든 변경은 루트 엔티티를 통해서만 이루어진다.애그리거트 경계(Aggregate Boundary): 애그리거트에 무엇이 포함되고 포함되지 않는지에 관한 범위이다. 경계 바깥의 객체들은 해당 애그리거트의 루트만 참조 가능하다.식별성 관리: 애그리거트 루트는 전역 식별성(Global Identity)을 가지고 경계 외부에서 식별된다. 반면 경계 내부의 엔티티들은 루트를 통해서만 접근되므로 지역 식별성(Local Identity)을 가진다.
불변식과 트랜잭션 일관성을 만족하기 위해서는, 하나의 애그리거트 내부에서 발생하는 모든 상태 변경은 하나의 트랜잭션 안에서 처리되어야 한다. 이때 애그리거트 내부의 상태 변경은 반드시 루트 엔티티를 통해서만 이루어져야 한다.
그러다보면, 자연스럽게 루트 엔티티에서 불변식을 만족하기 위한 로직이 비대해지고 복잡해질 수 밖에 없다. 하지만 이는 객체 하나의 응집도는 떨어뜨리더라도, 애그리거트 관점에서의 응집도를 높이는 전략이라고 볼 수 있다.
4. 리포지토리(Repository)
리포지토리는 애그리거트의 생명주기(저장, 조회, 삭제)를 관리하며, 특히 애그리거트 사이의 결합도를 낮추는 중요한 역할을 한다.
역할: 애그리거트 루트 단위로 저장, 조회, 삭제와 같은 작업을 수행한다.애그리거트 외부 참조: 다른 애그리거트를 직접 참조(=객체 참조)하는 대신, 해당 애그리거트의 식별자(id)를 통해 참조한다. 이는 불필요한 결합도를 줄이고, 각 애그리거트가 자신의 불변식과 트랜잭션 일관성을 독립적으로 유지할 수 있게 하기 위함이다.내부 참조: 애그리거트 내부에서는 객체 참조를 통해 결합도가 높아져도 괜찮다. 어차피 같은 불변식을 보장하고 함께 변경되기 때문이다.
JpaRepository와 같은 특정 기술을 직접 사용하는 방법이 있고, 도메인 레이어에서 순수한 리포지토리 인터페이스를 정의하고 이를 구현하는 방식이 있다. 참고로 Spring Data Jdbc라고 애그리거트 단위로 데이터를 처리하는 프레임워크에 대한 소개도 해주셨다.
5. 팩토리와 서비스
5-1. 팩토리(Factory)
팩토리는 객체나 애그리거트 전체를 생성하는 과정이 복잡하거나, 내부 구조를 클라이언트에게 너무 많이 노출하는 경우 이를 캡슐화 하는 역할을 한다.
목적: 복잡한 생성 과정을 추상화하고, 특히 생성 시점에 애그리거트의 불변식을 강제하는데 중점을 둔다.위치: 생성에 필요한 데이터를 모두 가지고 있는 객체에 팩토리 책임을 할당한다. 예를 들어, Order를 생성하기 위해 필요한 모든 정보가 Cart에 있으면 Cart에서 Order를 생성하는게 편하다. 두 애그리거트 간의 결합도를 낮추고 싶을 때는 아예 OrderFactory와 같이 별도의 팩토리로 만들 수도 있다.
보통 팩토리하면 팩토리 패턴과 같은 특정 디자인 패턴을 떠올리는 경우가 많다. 여기서 말하는 팩토리는 특정 방법론이나 디자인 패턴이라기 보다는 사고방식에 가깝기 때문에, 방식은 어떠하든 상관없다.
5-2. 서비스(Service)
서비스는 도메인 개념과 관련이 있지만, 특정 엔티티나 값 객체의 고유한 책임으로 보기 어려운 연산을 수행할 때 사용한다. 서비스는 어떠한 상태(속성)도 갖지 않으며, 엔티티나 값 객체의 일부를 구성하지도 않는다.
애플리케이션 서비스(Application Service): 유스케이스나 워크플로우를 처리하는 로직을 담는다. 트랜잭션 경계를 설정하는 등 주로 기술적인 흐름을 관리한다.도메인 서비스(Domain Service): 도메인 로직 중 엔티티나 값 객체에 할당하기 애매한 비즈니스 로직을 담는다.- 두 개 이상의 도메인 객체 간의 상호작용 하는 경우 (ex. 계좌 이체 등)
- 엔티티 외부의 정보를 활용하여 비즈니스 규칙을 검증하는 경우
- 애플리케이션 서비스로 새어나가는 도메인 로직을 도메인 계층에 머물게 하는 경우
- 위와 같은 경우에서 도메인 서비스를 사용할 수 있다. 근데 조영호님께서도 도메인 서비스는 정확히 언제 사용해야할지 아직도 애매하다고 하셨다.
6. 느낀점
2일차에는 도메인 주도 설계의 전술적 패턴과 이를 달성하기 위한 빌딩 블록들에 대해 살펴보았다. 사실, 예전에 다른 DDD 관련 책을 보면서 위의 개념들을 미리 접한 적이 있었는데 그때는 진짜 무슨 말인지 하나도 모르겠다는 느낌을 받았었다.
그런데, 1일차에서 도메인 주도 설계의 배경과 큰 그림을 한 번 듣고나니 각 빌딩 블록들의 역할과 쓰임새에 대해서 더 잘 이해되는 느낌을 받았다. 조영호님께서 요즘 나오는 DDD 책들은 본질은 잘 알려주지 않고 기술적인 것들만 다룬다고 하셨는데, 내가 딱 그렇게 DDD를 먼저 접했기 때문에 이해가 안되었던 건 아닐까라는 생각이 들었다.
나도 강의를 가끔 하는 입장이지만, 이번에 조영호님 강의를 들으면서 이런 짜임새있는 구성을 위해 얼마나 노력하셨을지가 느껴졌다. 더불어 수많은 PDF 장표를 만드는게 얼마나 지루하고 힘든지 알기에 그 정성이 느껴졌던 것 같다.
2일차에는 내가 사수 없는 환경에서 주니어로서 가지고 있던 고민에 대한 질문에도 답변해주셨다. 결국 어떤 환경이든 꾸준히 그리고 열심히 하는 사람은 방향이 달라도 결국 "실력이 뛰어난 개발자"라는 한 점에서 만난다는 말씀이셨는데, 들으면서 위로도 되고 많은 생각이 들기도 했다.
18만원이나 하는 강의가 처음에는 부담됐지만 결론적으로는 참 좋은 결정이었다고 생각한다. 강의 내용과 영호님의 수많은 경험을 통해 내 시간을 많이 아낄 수 있었으니 어떻게 보면 저렴한 걸지도 모르겠다. 다음에는 기회가 된다면 "JPA의 사실과 오해" 강의도 수강해 볼 예정이다.
나도 학생들에게 항상 "학습이란 결국 '학'과 '습'이라서, 배우는 것에서 멈추는게 아니라 익혀야 비로소 내 것이 된다."라고 강조하곤 한다. 이번에 배운 DDD를 회사 프로젝트에 직접 적용해 볼 수 있는지부터 어떻게 적용할건지 생각하고, 실제로 구현까지 해보는 시간을 가져야겠다. 아직 막막하긴 한데, 수많은 시행착오를 겪으면서 성장하는 재미가 기대된다.
