1. 개요
해당 프로젝트는 Java 17과 SpringBoot 3.1을 기반으로 한다.
데브코스 2차 프로젝트에서 인터파크 티켓 서비스를 클론코딩 하면서 “랭킹” 기능을 개발하게 되었다.
랭킹 기능은 아래와 같이, 현재 예매율을 기반으로 가장 잘 팔리는 공연들을 1위부터 50위까지 보여주는 것이다.

출처: 인터파크 티켓 홈페이지
인터파크 티켓에서 랭킹을 산정하는 기준은 꽤나 복잡해서, 클론코딩에서는 아래와 같이 간단하게 정했다.
[랭킹 산정 기준]
- 장르별이 아닌 전체 공연에 대해, 예매율 기준으로 상위 50개 공연을 정렬
예매율=(예매 수 / 좌석 수) * 100(%)- 예매율이 같으면 같은 순위로 표시하고, 겹치는 순위 개수만큼 다음 순위를 뛰어넘기
(예를 들어,1위 2위 2위 4위처럼 예매율이 같은 2위 공연이 2개라면, 다음 순위는 3위가 아니라 4위가 됨)
공연예술통합전산망 Open API를 이용해 삽입한 20만 개의 예매 데이터를 기반으로 진행한다.
API 엔드포인트는 GET /api/ranking 이며, 조회 결과는 아래와 같다.
{
"localDateTime": "2023-09-21T07:48:23",
"path": "/api/ranking",
"data": [
{
"performanceId": 322,
"title": "김유나 단독 팬콘서트: Yuna's invitation",
"posterUrl": "http://www.kopis.or.kr/upload/pfmPoster/PF_PF225042_230901_115633.jfif",
"startDate": "2023-09-17",
"endDate": "2023-09-17",
"hallName": "G스페이스홀(지스페이스홀)",
"reservationRate": 70.0,
"ranking": 1
},
{
"performanceId": 170,
"title": "판 페스티벌, 아름다움과 함께 걷기를...",
"posterUrl": "http://www.kopis.or.kr/upload/pfmPoster/PF_PF225403_230907_110108.gif",
"startDate": "2023-09-30",
"endDate": "2023-09-30",
"hallName": "산울림소극장",
"reservationRate": 68.0,
"ranking": 2
},
...(생략)
],
"message": null
}reservationRate가 예매율(%)을 나타내고,ranking이 순위를 나타낸다.
2. 캐시를 적용하지 않은 경우의 문제점
처음에는 단순히 랭킹 조회 기능만 완성하고 끝났다고 생각했었다.
이후 실제로 API를 요청해보면서 아래와 같은 두 가지의 문제점을 발견하였다.
2.1. 조회 시간이 오래 걸리는 문제
Apache JMeter를 통해 동시에 1000명의 사용자가 랭킹을 조회하는 상황을 테스트했다.

- 일단 평균 시간 자체가 굉장히 오래 걸리는 것을 확인할 수 있다.
- 오류 비율이 57%에 해당하는데, 서버 로그를 보면 DB 커넥션을 얻을 수 없어서 에러가 발생했다고 나온다.
HikariPool-1 - Connection is not available, request timed out after 30005ms.❓ 왜 DB 커넥션을 얻지 못할까?
DB 커넥션을 생성하는데에는 비용이 크기 때문에, 보통 커넥션 풀을 이용해 먼저 일정량의 DB 커넥션을 만들어 풀에 보관한다. HikariCP는 기본적으로 10개의 커넥션을 풀에 넣고 시작한다.하지만 JMeter를 이용해 1000개의 요청을 동시에 보냈으므로, 10개를 제외한 나머지 990개의
요청은 앞의 10개의 요청이 DB 커넥션을 반환할 때까지 일단 기다려야한다.하지만 현재 랭킹 조회 쿼리 자체가 오래 걸리므로, HikariCP의 기본 대기 시간인 30000ms를
넘어버리는 현상이 생긴다. 따라서 몇몇 요청은 커넥션을 얻지 못하고 에러를 발생시키는 것이다.
그럼 일단 현재 랭킹 조회가 왜 오래 걸리는지 알아보자.
랭킹 조회 기능의 SQL 문 중 일부 서브 쿼리를 보면 아래와 같다.
(참고로 MySQL 8.0 기반이며, JPA가 아닌 MyBatis 3.0을 사용하였다.)
SELECT
s.performance_id,
COUNT(s.schedule_id) schedules_count,
SUM(r.reservations_count) total_reservations_count
FROM schedule s
JOIN (
SELECT
schedule_id,
COUNT(reservation_id) reservations_count
FROM reservation
WHERE status = 'COMPLETED'
GROUP BY schedule_id
) r
ON s.schedule_id = r.schedule_id
GROUP BY s.performance_id- 먼저 공연의 회차(ex. 1회차, 2회차…)를 기준으로 예매 수를 센다. (
COUNT(reservation_id)부분) - 이후 특정 공연에 속한 모든 회차들의 각 예매 수를 더한다. (
SUM(r.reservations_count)부분) - 따라서 현재 랭킹 조회 기능은
20만 개의 예매 데이터가 있는 reservation 테이블을 일일히 조회한다.
실제로 티켓팅 서비스에서 예매라는 행위는 굉장히 자주 일어난다.
따라서 예매 데이터는 20만 개에서 그치지 않고 앞으로도 기하급수적으로 늘어날 것이고, 그에 따라 조회 시간은 더욱 오래 걸릴 것이다.
이를 어떻게 해결할 수 있을까? 떠오르는 해결책으로는 두 가지 정도가 있다.
- 쿼리를 효율적으로 개선해서 쿼리 자체에 대한 시간을 줄인다.
- 쿼리 결과를
캐시에 저장하여, 매 요청마다 쿼리를 실행하지 않고 캐시 데이터를 조회한다.
1번 방식 대신 2번 방식을 선택했다. 1번도 물론 꼭 필요한 개선점이긴 하지만 2번을 선택한 이유가 하나 더 있다.
2.2. 매 요청마다 랭킹이 달라지는 문제
현재 구조에서는 조회 시간이 오래 걸린다는 점 말고도, 또 다른 문제가 존재한다.
바로 각 사용자는 각각 다른 랭킹 데이터를 보게 된다는 점이다. 이게 무슨 말일까?
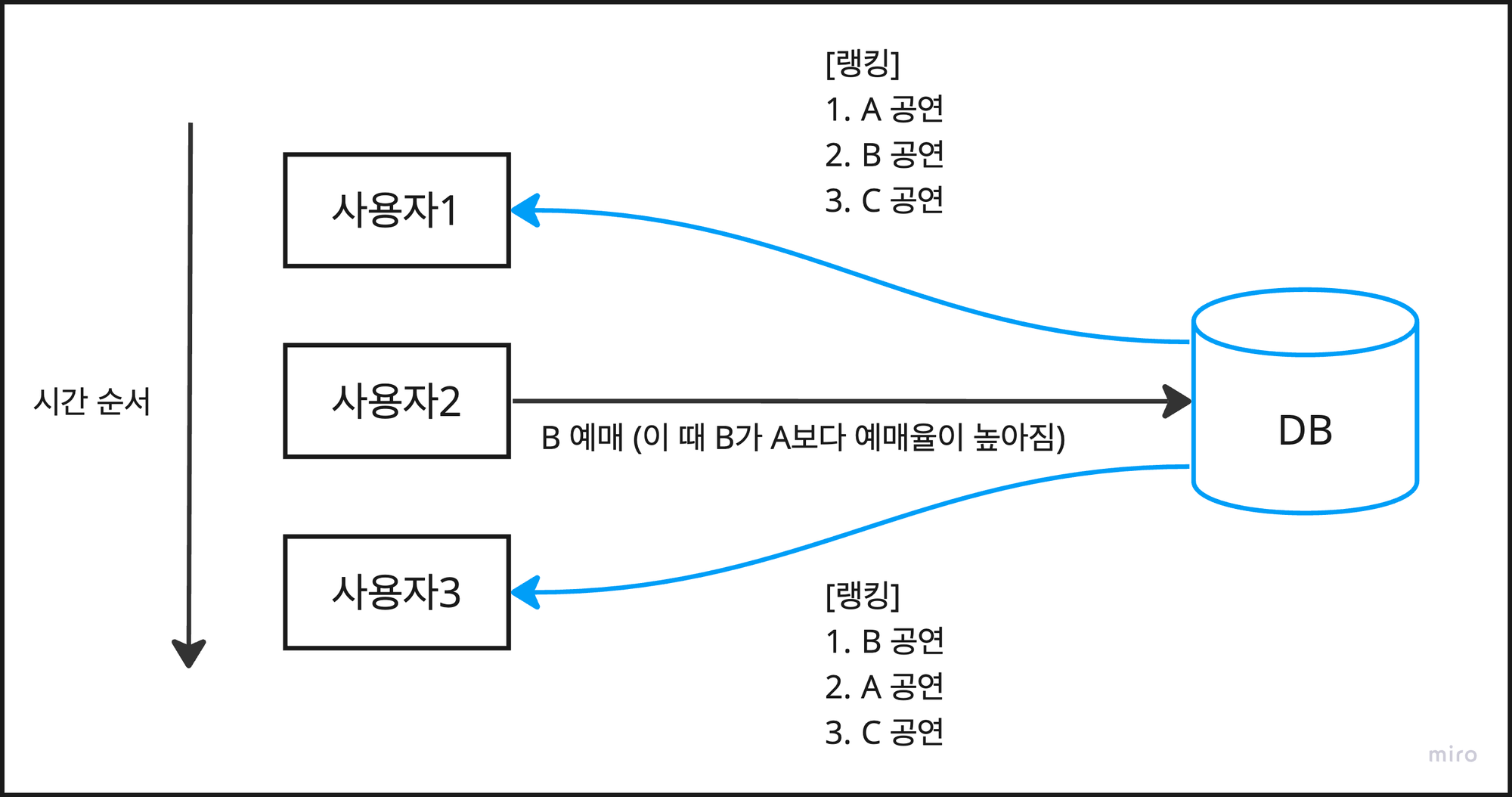
사용자1:GET /api/ranking을 통해 랭킹을 조회한다.사용자2: B 공연을 예매한다. 이때 B 공연의 예매율이 A 공연의 예매율 보다 높아진다.사용자3:GET /api/ranking을 통해 랭킹을 조회하면사용자1과는 다른 순위를 보게된다.
이는 아래와 같은 문제점을 발생 시킬 수 있다.
- 사용자는 새로고침 할 때마다 랭킹 데이터가 계속 달라진다. 이는 혼동을 가져온다.
- 여러 명의 사용자가 동시에 요청을 보내도 서로 다른 내용의 랭킹 데이터를 볼 수 있다. 역시 혼동을 가져온다.
쿼리 자체를 개선하여 응답 시간을 빠르게 만들더라도, 위의 문제는 해결하기 어렵다.
따라서 캐시를 이용해, 속도 문제와 실시간으로 데이터가 달라지는 문제를 모두 해결하고자 한다.
앞으로는 사용자가 요청을 보낼 때마다 DB를 일일히 조회하지 않고, 캐시에 있는 데이터를 응답하게 된다.
3. 로컬 캐시의 적용과 한계
3.1. 캐시를 이용한 문제 해결
앞서 매번 쿼리를 실행함으로 인해 속도 문제와, 실시간으로 데이터가 달라지는 문제를 확인했다.
캐시를 이용해 아래와 같이 해결할 수 있다.
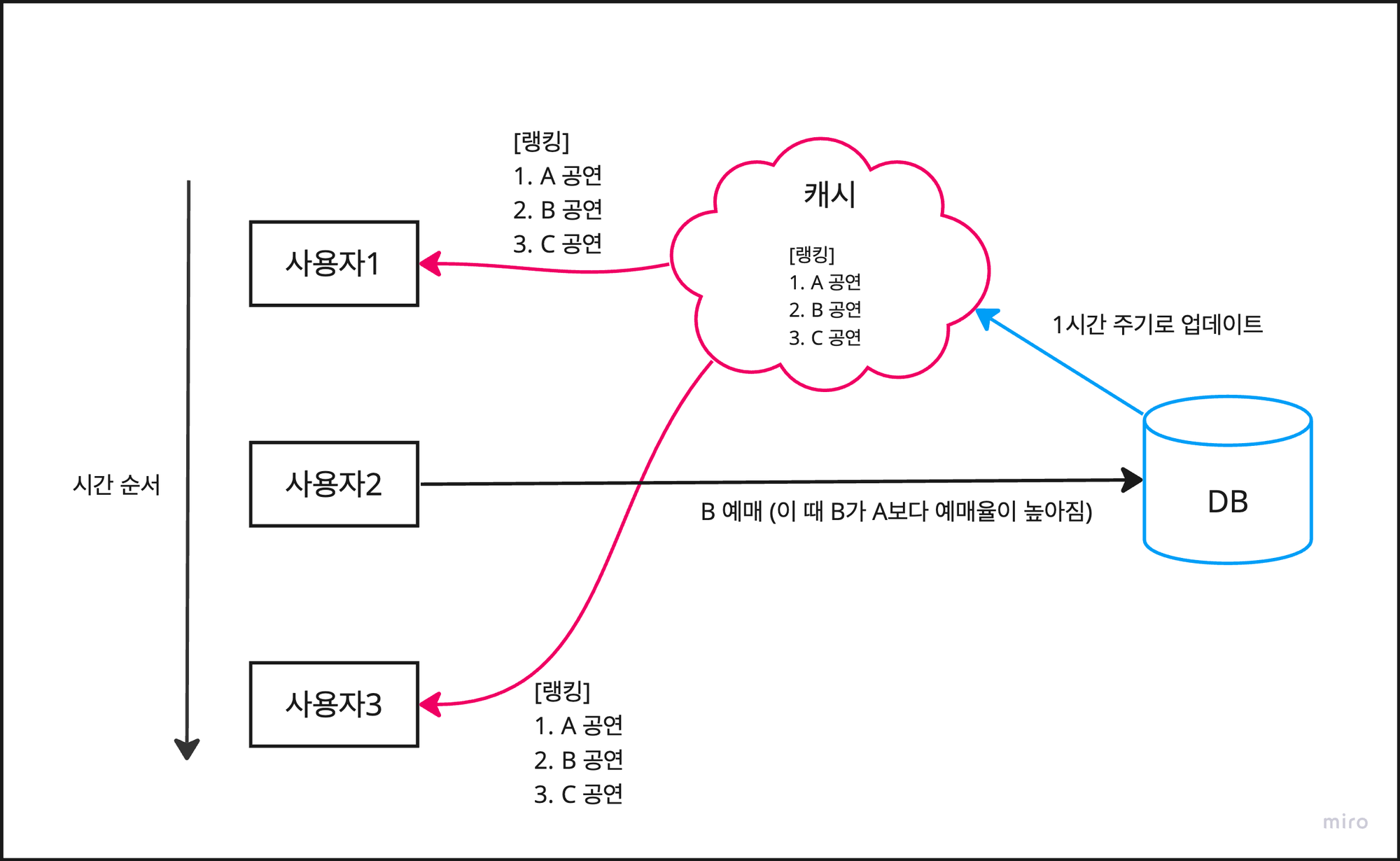
사용자1:GET /api/ranking을 통해 랭킹을 조회한다. (단, 이 때는 캐시 데이터가 반환된다.)사용자2: B 공연을 예매한다. 이때 B 공연의 예매율이 A 공연의 예매율 보다 높아진다.- 하지만 캐시에 업데이트 하지 않았으므로, 사용자들은 아직 갱신되지 않은 이전 랭킹 정보를 보게된다.
사용자3:GET /api/ranking을 통해 랭킹을 조회하면사용자1과 같은 순위를 보게된다.
캐시는 DB와 달리 인메모리 방식으로 동작하기 때문에 데이터를 읽어오는 속도가 굉장히 빠르다.
따라서 매 요청마다 DB에 쿼리를 보내는 기존 방식에 비해 속도가 많이 향상된다.
또한 사용자가 랭킹을 조회할 때 항상 캐시에 있는 데이터를 반환하기 때문에,
중간에 사용자 2의 예매와 같이 랭킹이 달라지는 경우가 있더라도, 동일한 응답 데이터를 보장한다.
“랭킹이 바뀌었는데도 예전 데이터를 계속 보여주면 안되는거 아니냐.” 고 의문을 품을 수 있다.
하지만 공연 랭킹 도메인이 주식이나 경매처럼 엄청난 실시간 업데이트를 요구한다고 보기는 어렵다.
단순히 최근 판매 추이만 잘 나타낼 수 있다면, 어느정도 텀을 두고 반영해도 괜찮다고 생각한다.
따라서 1시간 주기로 DB에 쿼리를 보내 최신 랭킹 데이터를 캐시에 업데이트 하는 방식을 택했다.
📌 [참고] 실제로 인터파크 티켓에서도 랭킹 정보를 1시간 단위로 업데이트한다.
출처: 인터파크 티켓 홈페이지

3.2. 로컬 캐시 적용하기
SpringBoot에서 기본적으로 제공하는 애너테이션을 통해 편하게 캐시를 사용할 수 있다.
일단 캐시를 적용하기 전의 Service 코드는 아래와 같다.
@Service
@RequiredArgsConstructor
public class NoCacheRankingService implements RankingService {
private final RankingRepository rankingRepository;
@Override
public List<RankingResponse> findTopRankingPerformances() {
return rankingRepository.findTopRankingPerformances();
}
}- repository에서 조회한 랭킹 데이터를 그대로 반환하므로, 매 요청마다 쿼리문이 실행된다.
캐시를 적용한 후의 Service 코드는 아래와 같다.
@Slf4j
@Service
@RequiredArgsConstructor
@CacheConfig(cacheNames = "topRankings")
public class LocalCacheRankingService implements RankingService {
private final RankingRepository rankingRepository;
@Override
@Cacheable(key = "'performances'")
public List<RankingResponse> findTopRankingPerformances() {
return putRankingCache();
}
@Override
@CachePut(key = "'performances'")
public List<RankingResponse> putRankingCache() {
List<RankingResponse> ranking = rankingRepository.findTopRankingPerformances();
log.info("[LOCAL] {}개의 실시간 랭킹 정보 갱신", ranking.size());
return ranking;
}
}@Cacheable은 캐시가 있다면 해당 캐시를 반환하고, 없다면 DB에서 조회한 데이터를 캐시에 저장한다.@CachePut은 캐시가 있든 없든, 무조건 DB에서 조회한 데이터를 캐시에 업데이트 한다.
사용자의 요청으로 인해 실행되는 메서드는 @Cacheable이 붙은 findTopRankingPerformances()이다.
따라서 이 때 캐시가 존재하면, 해당 랭킹 데이터를 반환하고, 캐시가 존재하지 않으면 putRankingCache()을 실행해 캐시를 업데이트한다.
이후 Apache JMeter를 통해 동시에 1000명의 사용자가 랭킹을 조회하는 상황을 다시 테스트했다.

- 평균 시간이 캐시가 적용되지 않았을 때와 비교하여 엄청나게 줄어들었다.
- 또한 초당 처리량도 많이 차이나는 것을 확인할 수 있다.
- 이전에는 1000개의 요청에 대해 1000번의 쿼리를 보냈다고 하면, 이제는 쿼리를 보내지 않는다.
(물론 캐시에 데이터가 없다면 캐시를 저장하기 위해 최초 1회 쿼리를 보낼 수는 있다.)
JMeter의 플러그인에서 제공하는 Response Times Percentiles 그래프를 봐도 많은 차이가 난다.
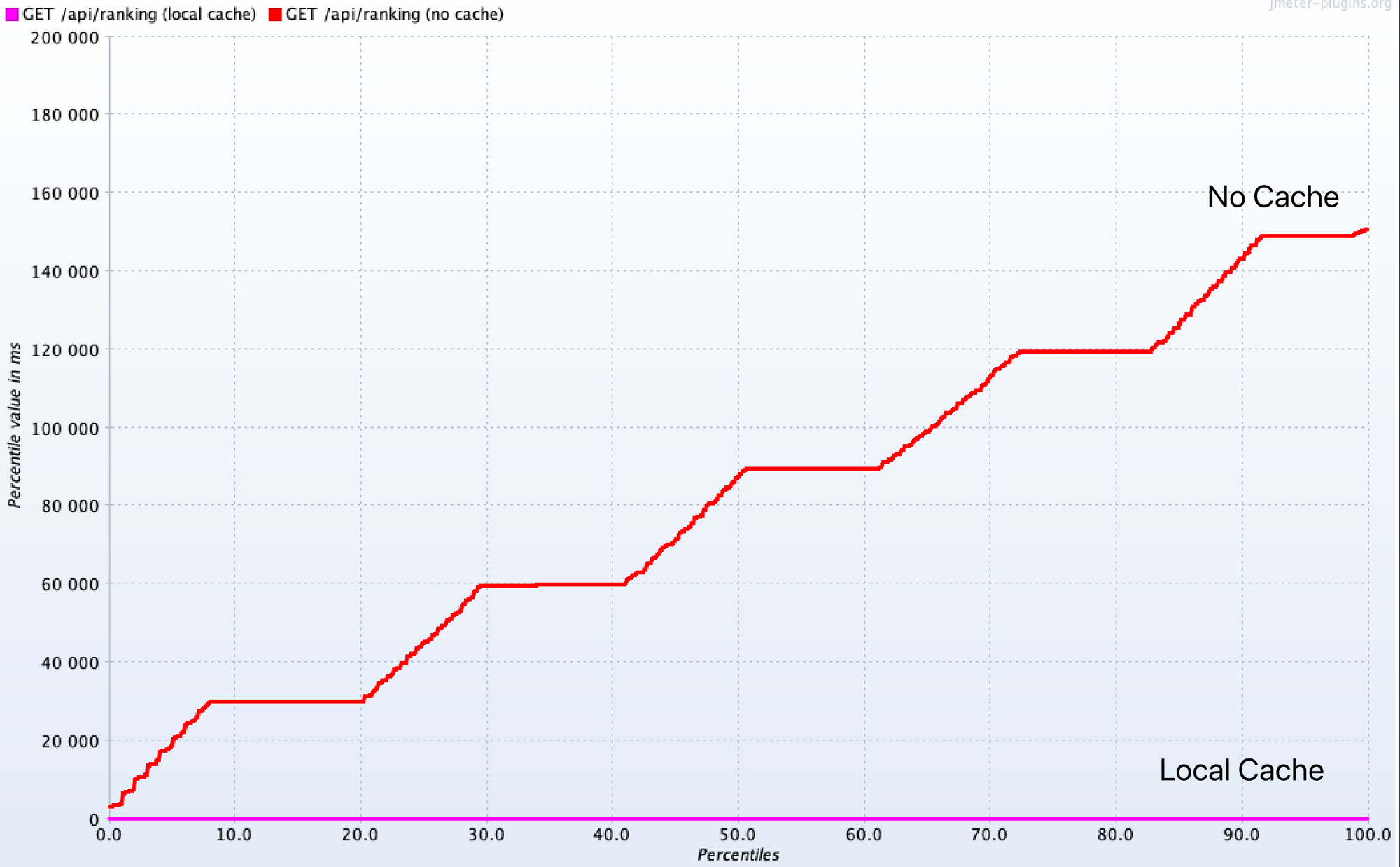
- 세로축이
모든 요청에 대해 응답할 때까지 걸린 시간이라고 보면 되는데, 로컬 캐시의 성능은 정말 대단하다!
📌 [참고] SpringBoot에서 기본적으로 제공하는 로컬 캐시는 ConcurrentHashMap이다.
ConcurrentHashMap은 말 그대로 동시성 문제를 고려한 자바의 해시맵 자료구조이다.
따라서 멀티 스레드 환경에서 안전하여, 여러 요청을 동시에 받는 상황에서 캐시로 사용될 수 있다.SpringBoot에서는 별다른 설정을 하지 않으면 기본 캐시 매니저로
ConcurrentMapCacheManager가 등록된다. 그런데 해당 캐시 매니저 클래스 파일에 가보면, 아래와 같은 주의사항이 적혀있다.”This is by no means a sophisticated CacheManager; it comes with no cache configuration options. However, it may be useful for testing or simple caching scenarios. For advanced local caching needs, consider JCacheCacheManager or CaffeineCacheManager.”
즉, 기본적으로 제공되는
ConcurrentMapCacheManager의 경우, 테스팅 용으로는 적합하지만
실무에서 사용은 어렵다는 의미이다. 그래서 로컬 캐시를 실제로 사용할 때는 주로EhCache나Caffeine Cache를 많이 사용한다고 한다. 특히나Caffeine Cache의 경우, 벤치마크 테스트에서 뛰어난 성능을 보여주고 있다.우리 프로젝트에서는 결국에는 Redis를 이용할 예정이기도 하고, 고도화 된 기능보다는 캐시 기능 자체를 사용 해보는 것에 의의를 두고 있으므로 기본적으로 제공되는 캐시 매니저를 사용하였다.
3.3. 스케줄링을 통한 캐시 자동 업데이트
캐시를 적용한 랭킹 조회 기능은 아직 반쪽 짜리 기능이다. 최신 랭킹 데이터를 업데이트하지 못하기 때문이다.
이를 위해 SpringBoot에서 제공하는 스케줄링 기능을 통해 1시간 마다 캐시에 데이터를 업데이트한다.
RankingScheduler라는 별도의 스케줄링 클래스를 만들어서 아래와 같이 작성하였다.
@Component
@RequiredArgsConstructor
public class RankingScheduler {
private final RankingService rankingService;
@Scheduled(cron = "0 0 0/1 * * *")
public void refreshRankingCache() {
rankingService.putRankingCache();
}
}@CachePut이 붙은 RankingService의putRankingCache()메서드를1시간에 한 번씩호출한다.- 업데이트 주기는 Cron(크론) 표현식을 이용해 지정하였다.
따라서 매 정각이 되면 putRankingCache() 가 실행되면서 아래와 같은 로그를 남기며 캐시를 업데이트한다.

📌 [참고]
fixedDelayvscron@Scheduled 애너테이션에 주기를 설정하는 옵션으로 fixedDelay와 cron이 있다.
처음에는 1시간 마다 실행되어야 하기 때문에
fixedDelay를 이용해 1시간 주기로 맞춰주었다.
하지만 이는 마지막 작업 종료 후 1시간을 더해 다음 작업을 실행하는 형식이므로,
서버가 여러 개일 때 문제가 될 수 있다.예를 들어 애플리케이션 서버가 1, 2로 두 개가 있다고 가정해보자.
서버 1과 서버 2를 모두2023년 09월 20일 13:00에 구동했다고 했을 때,
우리는 서버 1과 서버 2 모두14:00, 15:00, 16:00 …일 때 동시에 스케줄러가 동작하길 바란다.하지만 어떤 상황에 의해 서버 2의 스케줄러가 14:10에 늦게 동작하여 캐시를 업데이트 했다면,
앞으로 서버 2는15:10, 16:10 …에 맞추어 동작하려고 할 것이다.
즉, 서버 1과의 캐시 업데이트 타이밍이 어긋나게 된다. 이는 데이터 정합성에 큰 문제를 야기할 수 있다.
cron옵션은 시작 시간과 상관 없이, 정해진 시각에 동작하도록 지정할 수 있다.
따라서 서버 1, 2 중 하나가 돌발 상황으로 인해 이전 작업이 늦어졌어도, 다음 작업 스케줄은 여전히
동일한 시간에 동작 될 것이다. 그래서 cron 옵션으로 변경했다!
3.4. 로컬 캐시의 한계
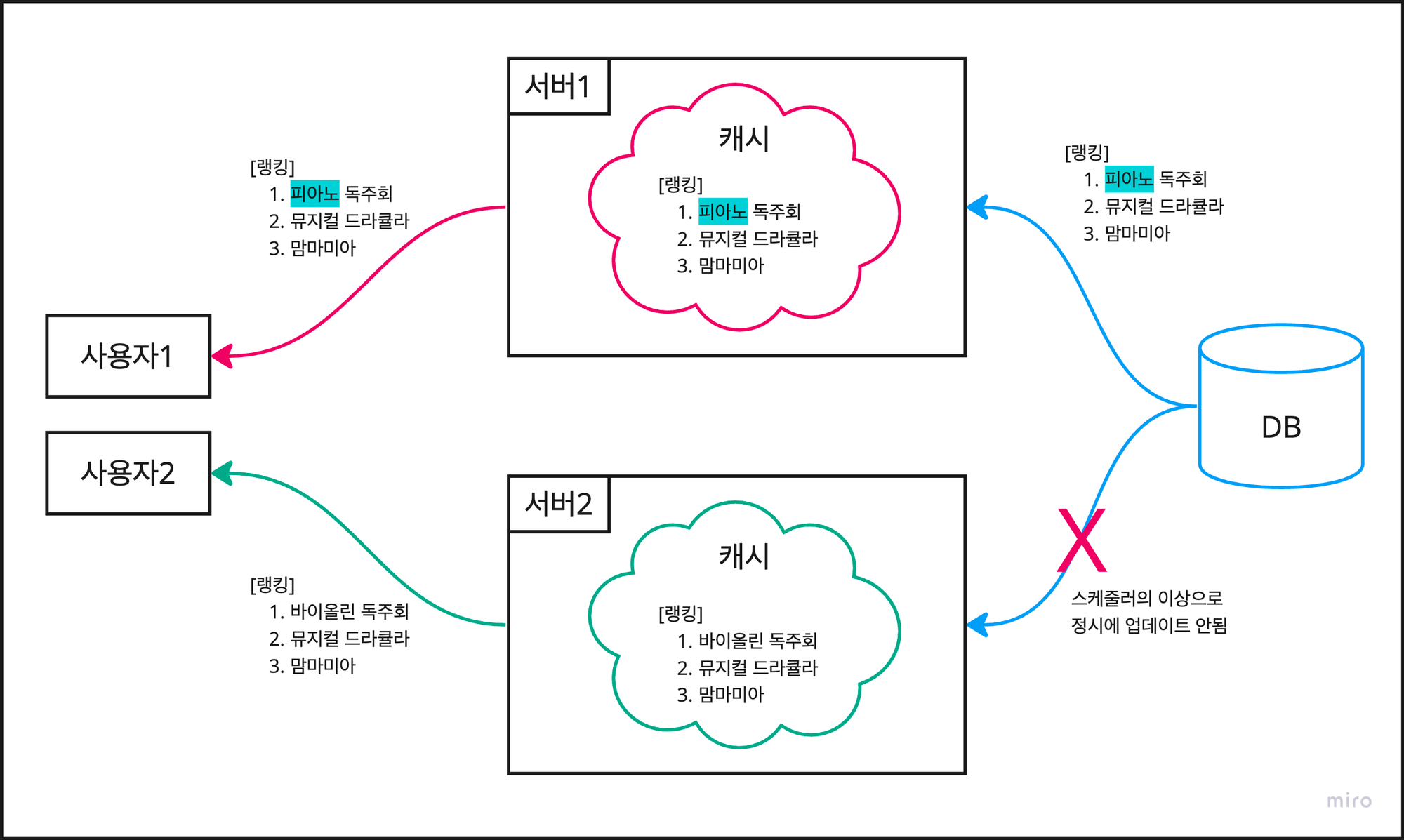
로컬 캐시는 말 그대로 “로컬”에 캐시가 존재한다. 즉 애플리케이션 서버 내의 메모리에 존재한다는 것이다.
따라서 단일 서버가 아닌, 여러 개의 서버를 구동하는 환경에서는 데이터 정합성 문제가 발생한다.
먼저, 같은 DB를 공유하는 두 개의 애플리케이션 서버가 있다고 가정해보자.
현재 두 서버의 로컬 캐시에는 같은 랭킹 데이터가 잘 캐싱되어 있어서 각 사용자에게 동일한 데이터를 응답한다.
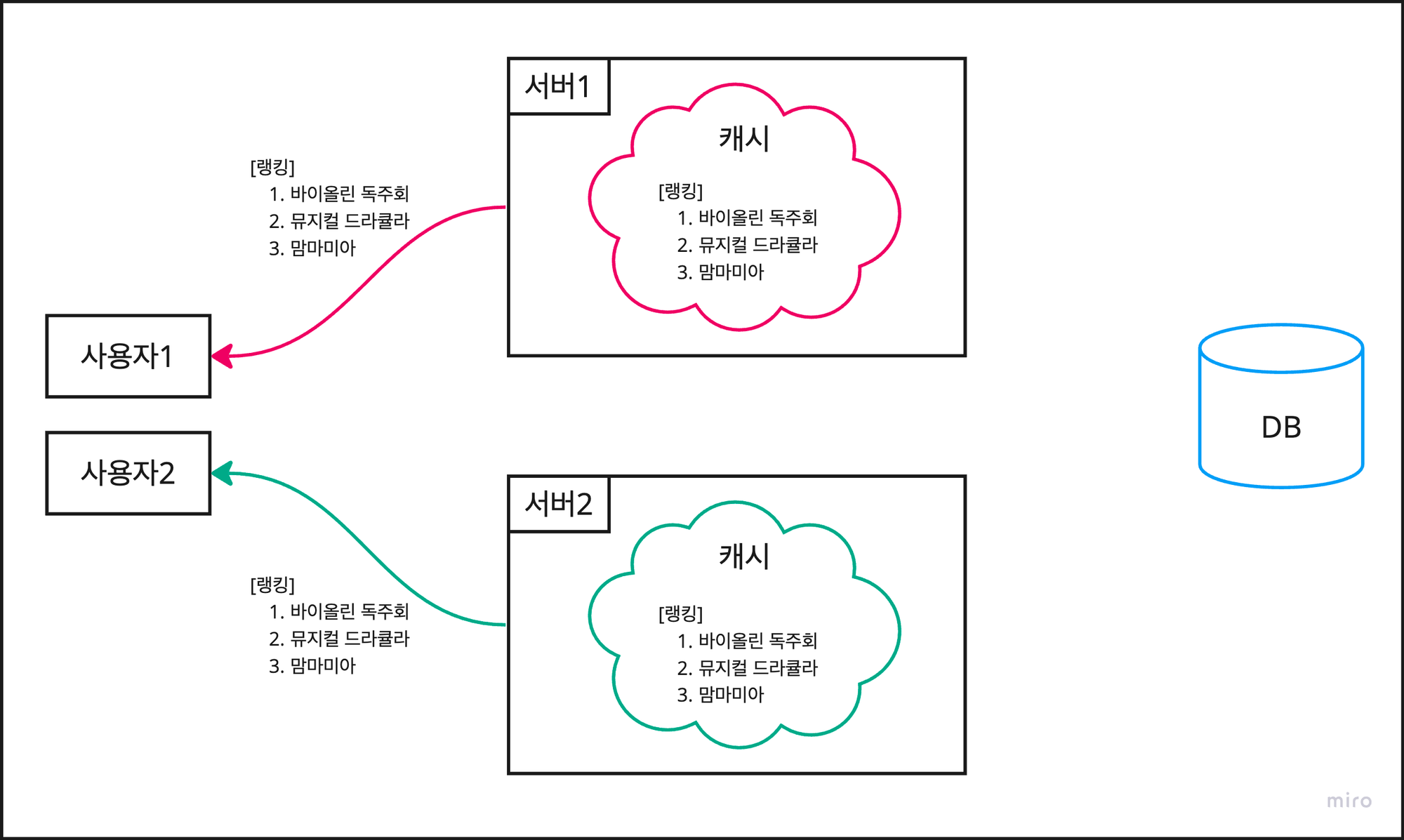
스케줄러가 캐시 업데이트를 동작 시키기 전에, DB에서 공연 데이터의 이름이 변경되었다고 가정해보자.
(사실 랭킹이 변하든 다른게 변하는 결국 원리는 같다. 이후 실습 과정을 쉽게 하기 위해 이름을 변경하는 것이다.)
1시간이 지나 스케줄러가 동작을 하는데 서버 1만 잘 동작하고 서버 2는 잘 동작하지 않으면 문제가 발생한다.
사용자 1은 업데이트 된 최신 랭킹 데이터를 조회 하지만, 사용자 2는 이전 데이터를 조회하게 된다.
이를 데이터의 정합성이 맞지 않는다고 표현하며, 각 서버에 종속되는 로컬 캐시 특성 상 어쩔 수 없는 한계점이다.
실제로 인텔리제이에서 8080, 8081 두 개의 포트로 각각 로컬 서버를 띄우고 실습을 해보았다.
8080과 8081의 두 서버에서 아래의 캐시 데이터를 동일하게 가지고 있다.
{
"performanceId": 1,
"title": "이채영 바이올린 독주회",
"posterUrl": "http://www.kopis.or.kr/upload/pfmPoster/PF_PF225990_230915_151513.gif",
"startDate": "2023-09-23",
"endDate": "2023-09-23",
"hallName": "비오케이아트센터(BOK아트센터)",
"reservationRate": 72.3,
"ranking": 2
}DB에 네이티브 쿼리를 보내서, title을 바이올린 → 피아노로 직접 변경한다.
UPDATE performance
SET title = '이채영 피아노 독주회'
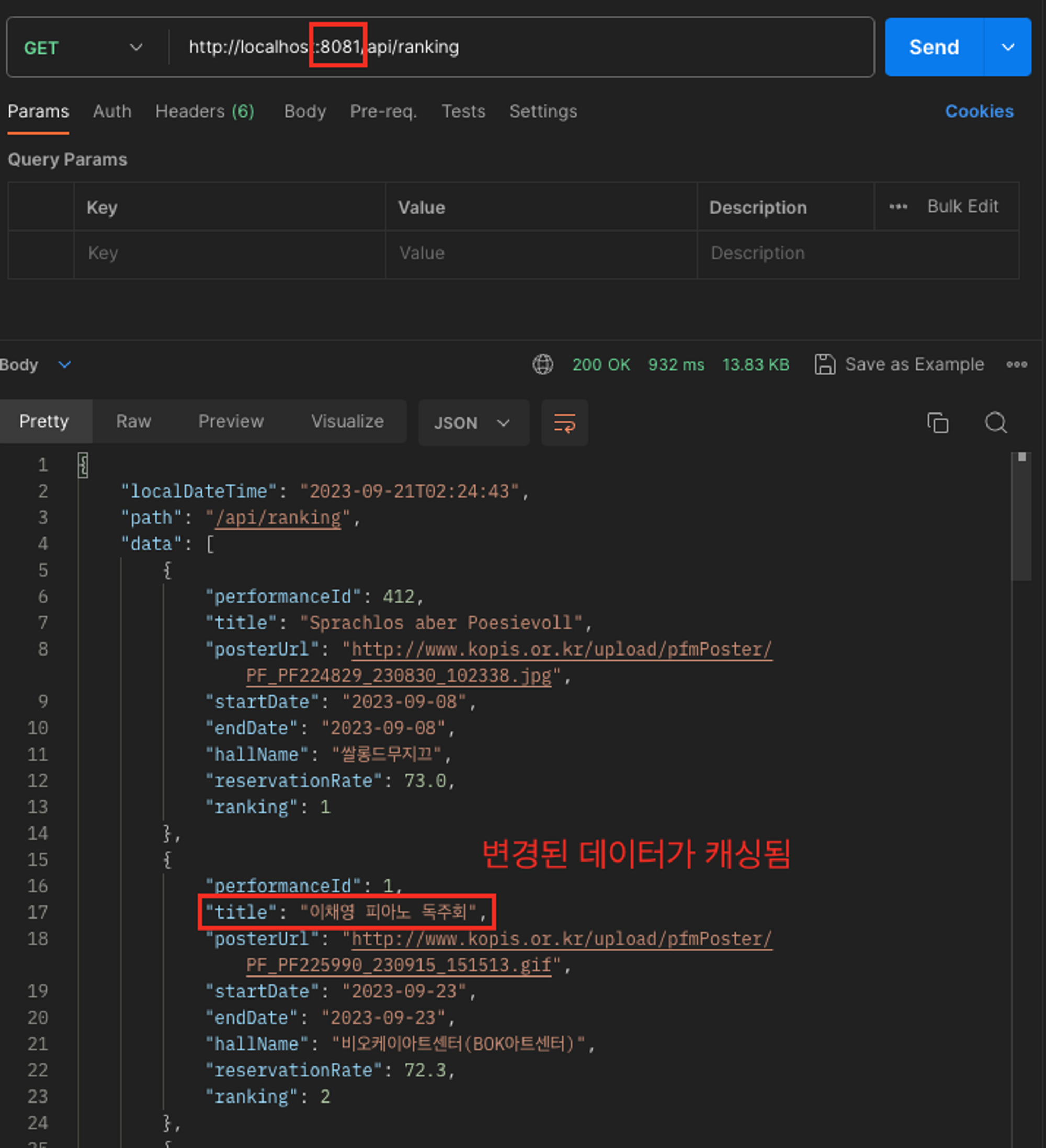
WHERE performance_id = 1;이후 8080은 스케줄러가 동작하지 않고, 8081만 제대로 스케줄러가 동작하면 아래와 같은 현상이 나타난다.
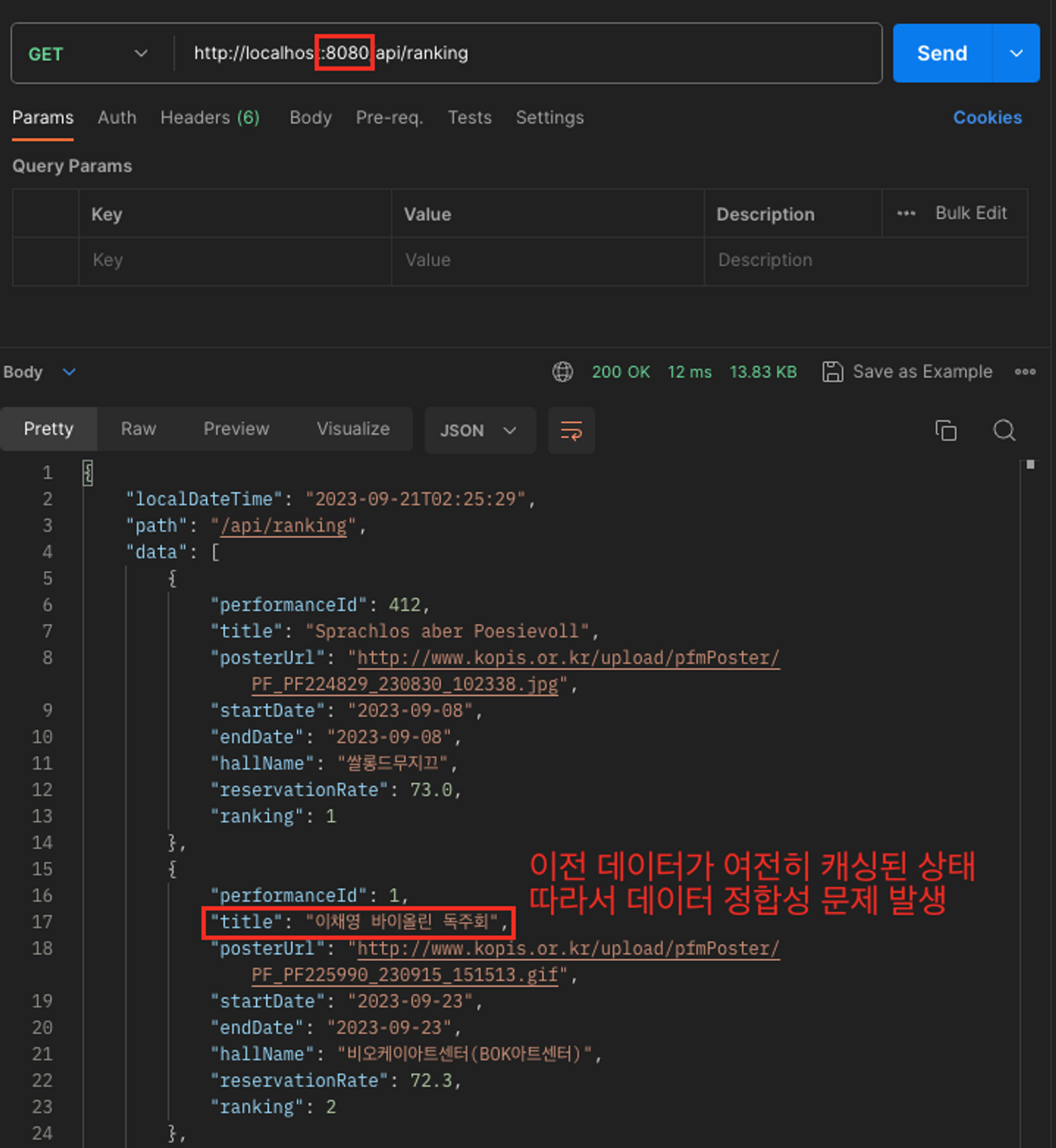
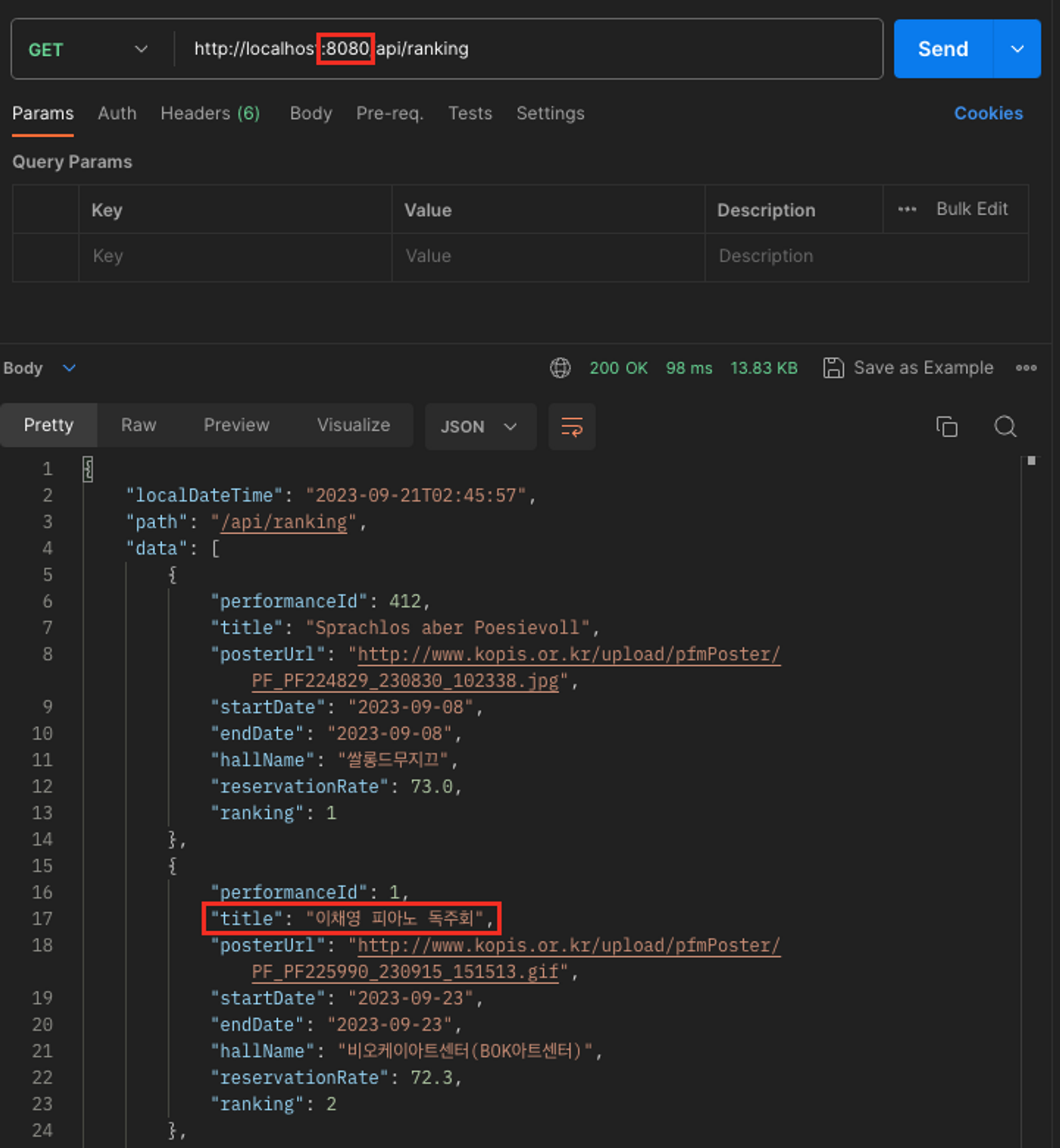
8080은 스케줄러가 동작하지 않아, 캐시가 업데이트 되지 않았다. 그래서 여전히 “바이올린”을 응답한다.
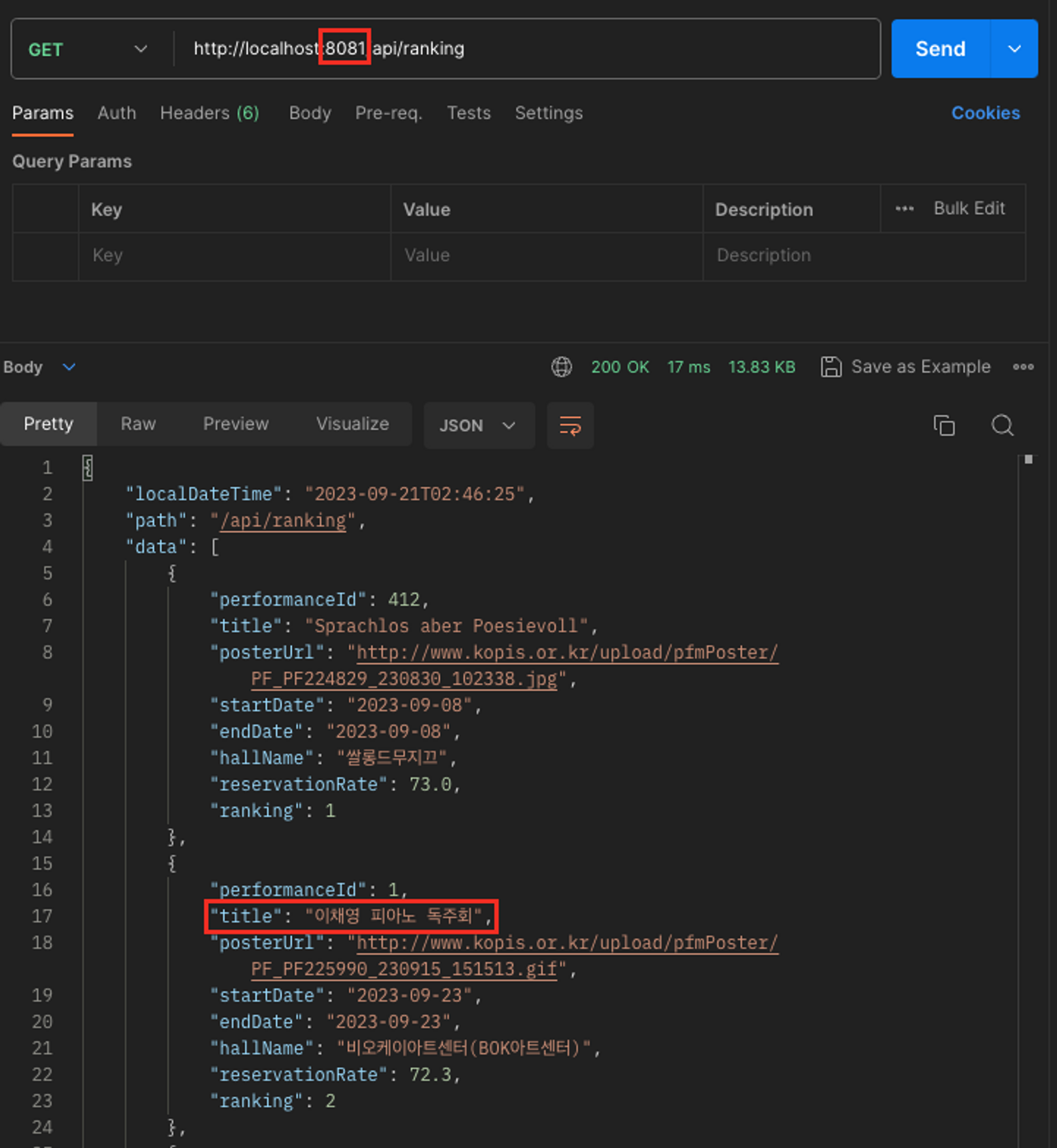
8081은 스케줄러가 동작하여 캐시가 정상적으로 업데이트 되었다. 그래서 “피아노”를 응답한다.
이렇게 여러 개의 서버 상황에서는 로컬 캐시의 데이터 정합성 문제가 발생함을 확인하였다.
4. Redis를 적용하여 데이터 정합성 문제 해결
현재까지의 내용을 정리하면 아래와 같다.
1. 캐시 없이 매 요청마다 쿼리 발생 → 느린 속도로 인한 커넥션 에러, 각 요청마다 랭킹 결과가 다름
2. 로컬 캐시 적용하여 속도와 결과 통일 → 다중 서버의 경우 데이터 정합성 훼손됨
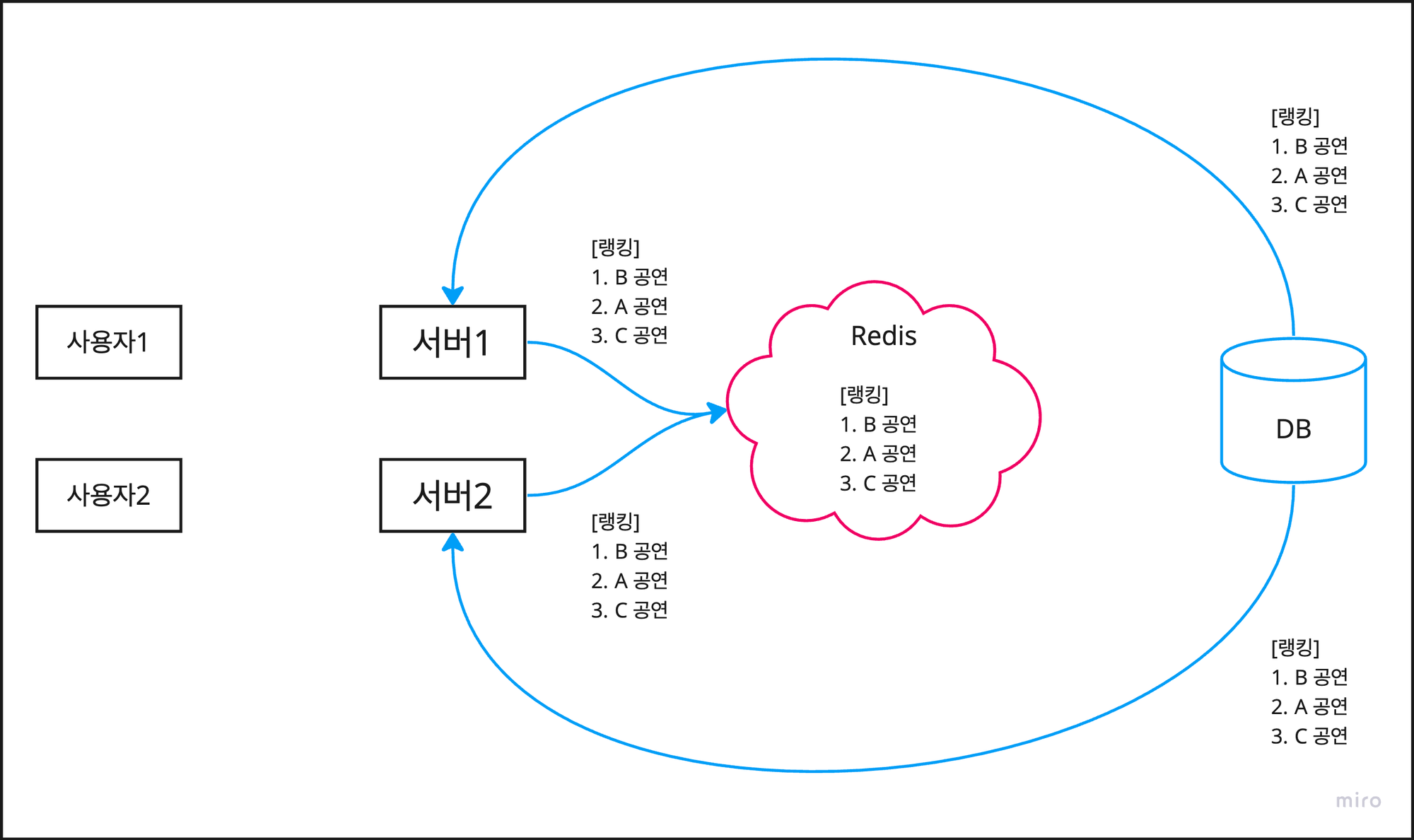
이제 Redis라는 별도의 캐시 저장소를 이용해 다중 서버의 경우에도 데이터 정합성을 만족하도록 해보자.
Redis(Remote Dictionary Server)란 인메모리 방식으로 동작하는 key, value 형식의 저장소를 말한다.
만료 시간 지정이 가능하고, 여러 자료구조를 지원하며, pub sub과 같은 다양한 기능도 있다는 장점이 있지만,
여기에서는 데이터 정합성을 해결하는 것을 중심으로 단순하게 사용 해 볼 예정이다.
로컬 캐시와 달리 캐시 저장소를 서버의 외부에 두는 글로벌 캐시를 이용하면 정합성 문제를 해결할 수 있다.
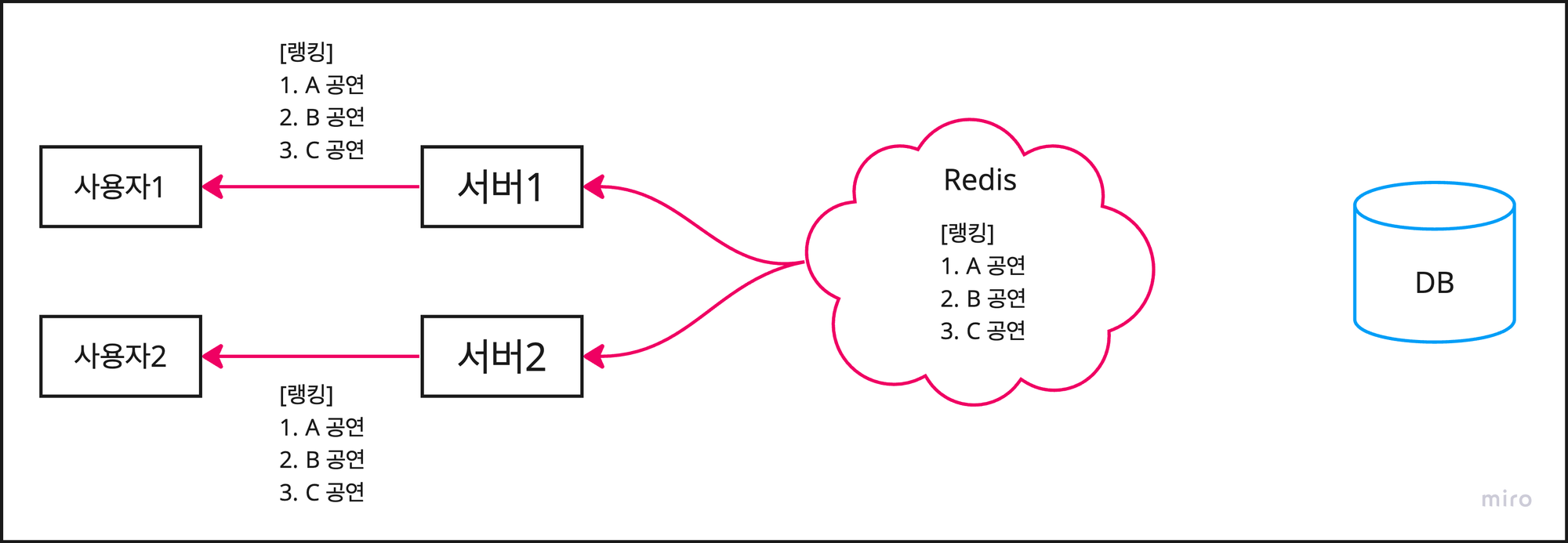
사용자1:GET /api/ranking을 통해 랭킹을 조회한다.사용자2:GET /api/ranking을 통해 랭킹을 조회한다.- 그리고 사용자1과 사용자2는 공동의 저장소에서 캐시를 조회하므로 매번 동일한 데이터를 조회한다.
📌 [참고] 로컬 캐시와 글로벌 캐시
로컬 캐시 : 서버마다 각 캐시 저장소를 내부에 두는 방식
- 주로 로컬 서버의 메모리나 디스크를 이용해 캐시를 저장한다.
- 서버 간 동기화가 이루어지지 않으면 데이터 정합성이 훼손될 수 있다.
- 예) ConcurrentHashMap, JCache, EhCache, Caffeine Cache 등
글로벌 캐시 : 서버의 외부에 캐시 저장소를 따로 두고 공동으로 사용하는 방식
- 별도의 캐시 서버를 두고 공동으로 사용하므로 데이터 정합성을 쉽게 만족시킬 수 있다.
- 서버 외부에 있으므로 네트워크 통신이 이루어지므로 로컬 캐시보다는 느리다.
- 예) Redis, Memcached 등
따라서 각 서버 스케줄러의 작동 여부와 상관없이, 사용자들은 항상 같은 캐시 데이터를 조회할 수 밖에 없다.
서버 2의 스케줄러가 작동하지 않아도, 서버 1의 스케줄러가 작동하면 Redis가 업데이트 되기 때문이다.
심지어 서버 1, 2의 스케줄러 모두가 작동하지 않더라도, 이전 데이터는 유지되므로 데이터 정합성 또한 유지된다.
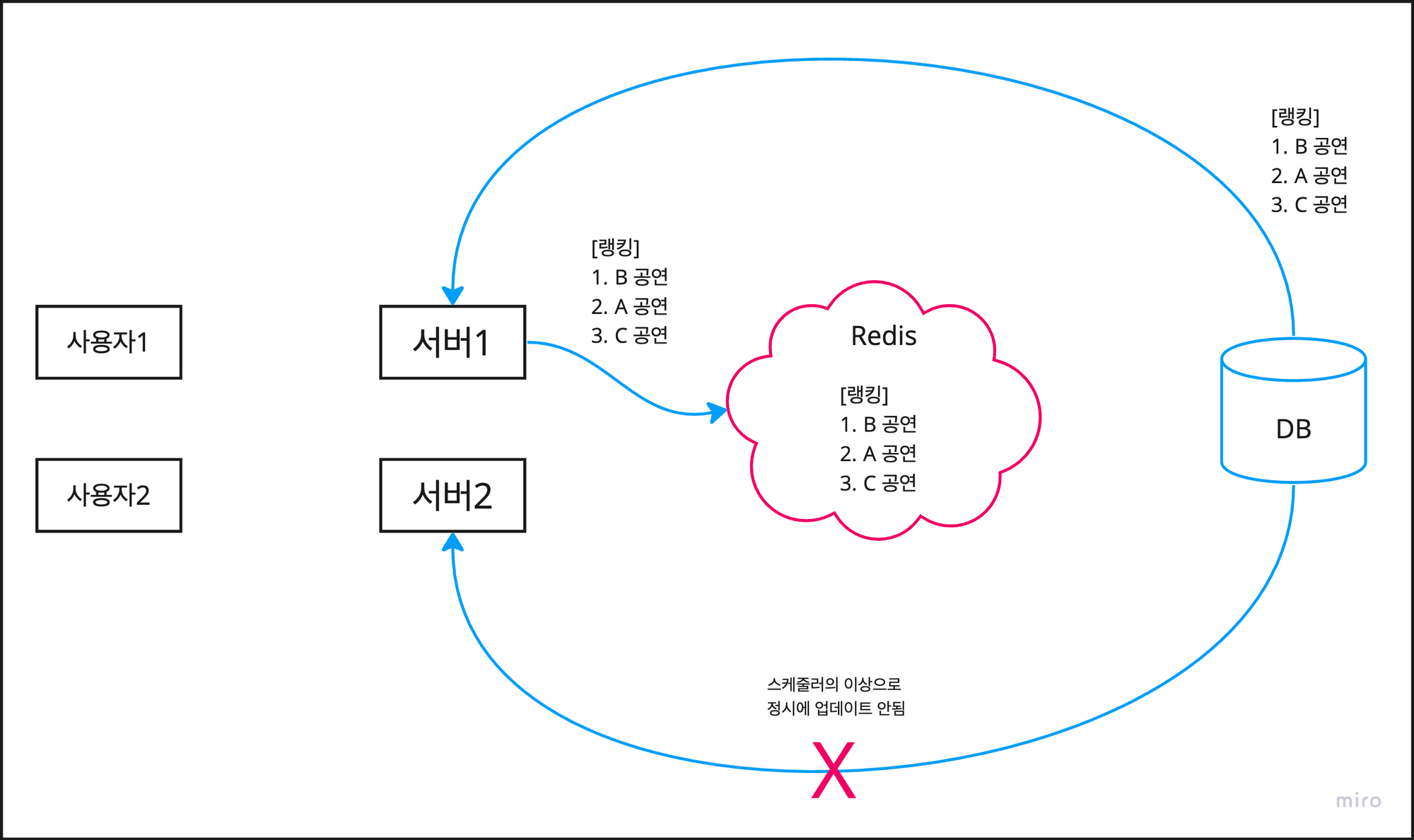
로컬 캐시 때와 마찬가지로 인텔리제이에서 8080과 8081 포트로 두 서버를 띄우고 실습을 진행해보았다.
아까와 마찬가지로 DB에 네이티브 쿼리를 보내서, title을 바이올린 → 피아노로 직접 변경한다.
UPDATE performance
SET title = '이채영 피아노 독주회'
WHERE performance_id = 1;한 쪽 스케줄러가 정상적으로 동작하지 않더라도, 8080과 8081 모두 변경된 데이터를 동일하게 조회한다.
성능적인 측면은 어떨까?
Apache JMeter를 통해 동시에 1000명의 사용자가 랭킹을 조회하는 상황을 다시 테스트했다.

- 당연히 Redis가 서버 외부에 있으므로 네트워크 통신을 하기 때문에 로컬 캐시보다는 느리다.
- 하지만 캐시를 적용하지 않을 때 보다 평균 시간과 처리량 측면에서 굉장히 많은 차이가 난다.
- 데이터 정합성도 만족하면서 성능도 로컬 캐시에 버금갈 정도이므로 여러모로 효율이 좋다.
Response Times Percentiles 그래프를 통해 로컬 캐시와 Redis 캐시를 비교하면 아주 조금 차이가 나긴 한다.
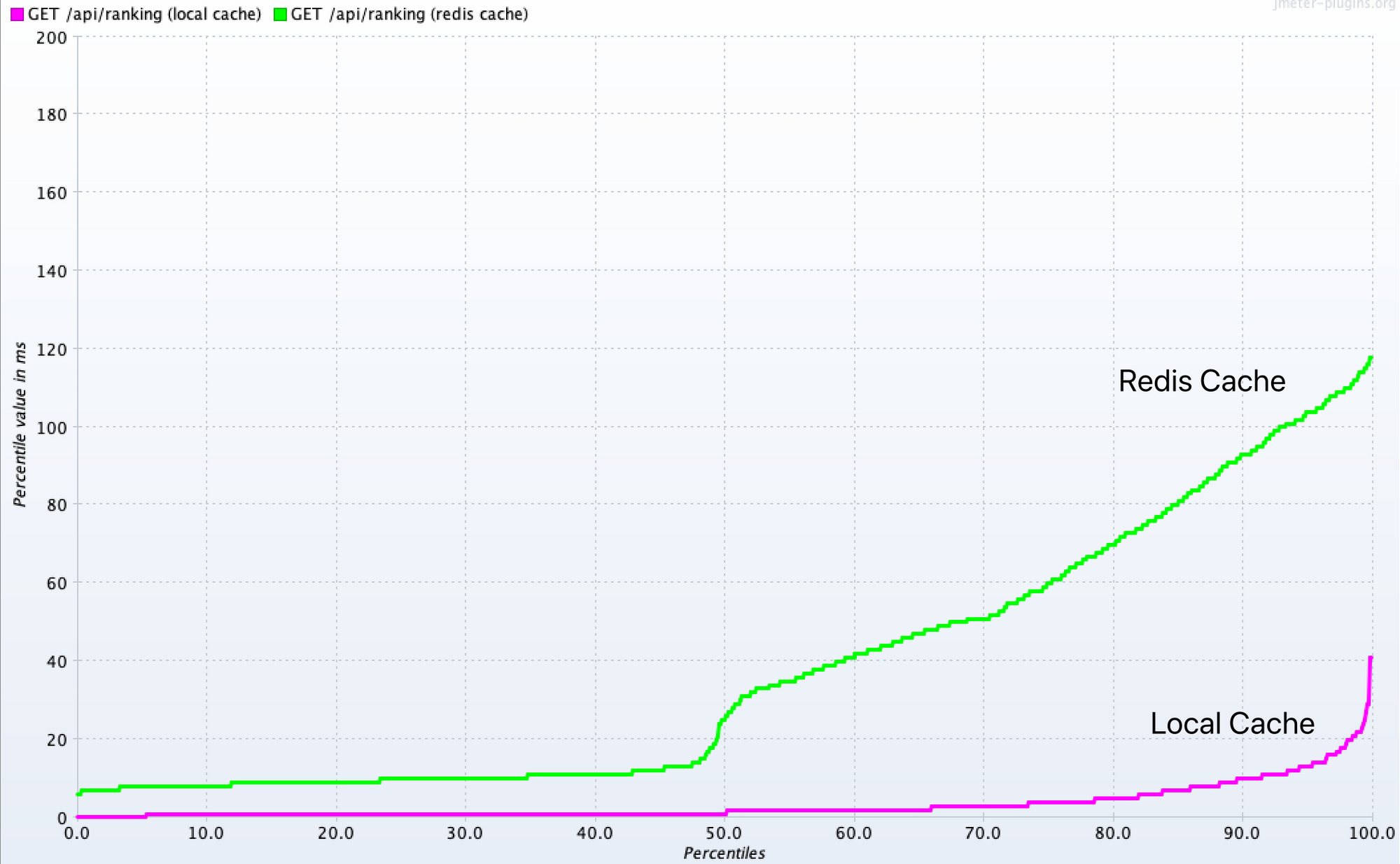
이 정도면 거의 미미하지 않을까…?
5. 정리 및 추후 개선점
마무리 하면서 전체적인 내용을 정리하면 아래와 같다.
상위 50개의 공연 랭킹 데이터를 조회하는 API에 대해 캐시를 적용하여 단계별로 효율화를 진행하였다.
1. 캐시 없이 매 요청마다 쿼리 발생 → 느린 속도로 인한 커넥션 에러, 각 요청마다 랭킹 결과가 다름
2. 로컬 캐시 적용하여 속도 개선과 결과 통일 → 다중 서버의 경우 데이터 정합성 훼손됨
3. Redis를 이용한 다중 서버 외부의 공동 캐시 저장소 → 속도, 데이터 정합성 모두 해결
추후 개선점으로는 두 가지 정도가 있다.
하나는, 다중 서버에서 중복 캐시 업데이트가 발생한다는 점이다.
만약 아까의 상황에서, 두 서버 모두 스케줄러가 정상적으로 동작하면 아래와 같은 현상이 발생한다.
이미 서버 1에서 캐시를 업데이트 했는데, 서버 2에서 중복으로 업데이트를 하는 비효율이 나타나게 된다.
중복으로 업데이트 하는 과정에서 들어오는 다른 요청으로 찰나의 순간에 데이터 정합성이 깨질 가능성도 있다.
이를 해결하기 위해 세 가지 방법을 적용할 수 있다고 한다. 나중에 꼭 적용 해보고 싶다.
1. 서버 하나가 캐시를 업데이트 했다면 Redis에 락을 걸어서 중복 업데이트를 방지하기
2. 각 서버에서 스케줄링 기능을 빼고, 별도의 스케줄링 서버를 띄워서 캐시 업데이트 하기
3. Github Actions나 Jenkins를 이용해서 일정 주기마다 스케줄링 API를 호출하여 캐시 업데이트 하기
둘째는, 우리의 배포 서버는 아직 단일 서버라는 점이다.
사실 Redis를 사용하는 이유는 단일 서버가 아닌 다중 서버에서의 데이터 정합성을 맞추기 위함이다.
로컬 환경에서는 인텔리제이를 통해 다중 서버를 띄워서 해봤지만, 배포 환경에서는 그러지 못했다.
EC2 인스턴스 내의 단일 애플리케이션 서버에서 AWS ElastiCache에 캐싱 및 스케줄링은 지금도 잘 되지만,
추후에 EC2 인스턴스 내에 서버를 하나 더 띄워서 데이터 정합성이 잘 맞는지도 확인해 보고 싶다.
