탐색 알고리즘 (DFS / BFS)
참고
[알고리즘/Python]leetcode - 622.Design Circular Queue (원형 큐 디자인)
탐색알고리즘의 정의
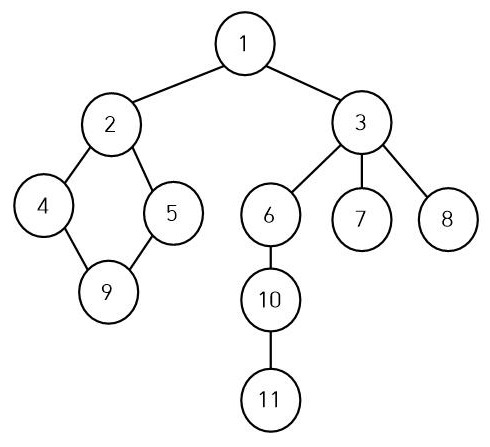
- 탐색 : 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정
- 그래프의 모든 정점들을 특정 순서에 따라 방문하는 알고리즘
- 정점과 간선으로 구성된 한정된 자료구조
- 각각의 지점 정점
- 연결을 간선
- 각 정점이 서로 연결되어 있는지, 주어진 시간내에 "탐색을 통해" 확인하는 알고리즘
활용
- 네비게이션 경로 검색 ( 특정 위치를 가는 경로 탐색 )
- 암시적 그래프 표현
- 그래프형식이 아니지만 그래프 탐색 알고리즘을 활용해 풀수있는 문제가 있다.
- 정점과 간선대신 x,y 좌표로 각 위치를 표현한다.

그래프로 변형하기에는 작업이많이소요되기 때문에 → 2차원 x, y 좌표로 접근하여 문제 해결
자료 구조 스택 / 큐
- 데이터 사이의 관계를 반영한 저장구조 및 그 조작방법을 뜻한다.
- DFS 와 BFS 를 알아보기전에 스택 / 큐를 먼저 알아보자.

스택(Stack)
- 후입 선출 ( Last in First Out )
- 입구와 출구가 동일한 형태
- 관속에 어떤 물건을 쌓는다고 생각하면 된다. (마지막에 쌓은것이 먼저나옴)
stack = []
stack.append(1)
stack.append(2)
stack.append(3)
>> [1, 2, 3]
stack.pop()
>> 3
stack.pop()
>> 2
stack.pop()
>> 1큐(Queue)
- 선입 선출 ( First in First Out )
- 대기줄에 비유
- list를 이용해서 queue를 구현하면 아래와 같이 할 수있다.
queue = []
queue.append(1)
queue.append(2)
queue.append(3)
queue.pop(0)
>> 1
queue.pop(0)
>> 2
queue.pop(0)
>> 3위 코드처럼 queue를 구현하면, 먼저들어간 데이터를 빼주는 작업에서 모든 데이터를 한칸씩 앞으로 당기는 작업을 수반하게 된다.
0x01 0x02 0x03
[ 1 ] - [ 2 ] - [ 3 ]
0x01 0x02 0x03
[ None ] - [ 2 ] - [ 3 ]
0x01 0x02 0x03
[ 2 ] - [ 3 ] - [ ? ]이는 데이터를 끄집어 내는데 걸리는 시간복잡도가 O(1)이 아닌 O(n)이 되는 현상이 벌어지게된다.
Collections.deque (Double-ended queue)
자료의 앞과 뒤 어느곳에서나 삽입/삭제가 가능한 데이터 구조
- 파이썬의 경우 queue를 이용할때 collections 패키지를 사용해주는것이 좋다.
from collections import deque # (*deque는 double ended queue의 약자)
queue = deque()
queue.append(1)
queue.append(2)
queue.popleft()
>> 1
queue.popleft()
>> 2- 다른방법으로는 Circular Queue 를 사용하는 방법이 존재한다.
Circular Queue
- 원형 큐, 환형 큐 또는 링버퍼(Ring Buffer)라고 부른다.
- 기존 queue 와 동일하게 선입선출의 구조이다.
- 마지막 위치가 시작위치에 연결되어있다.
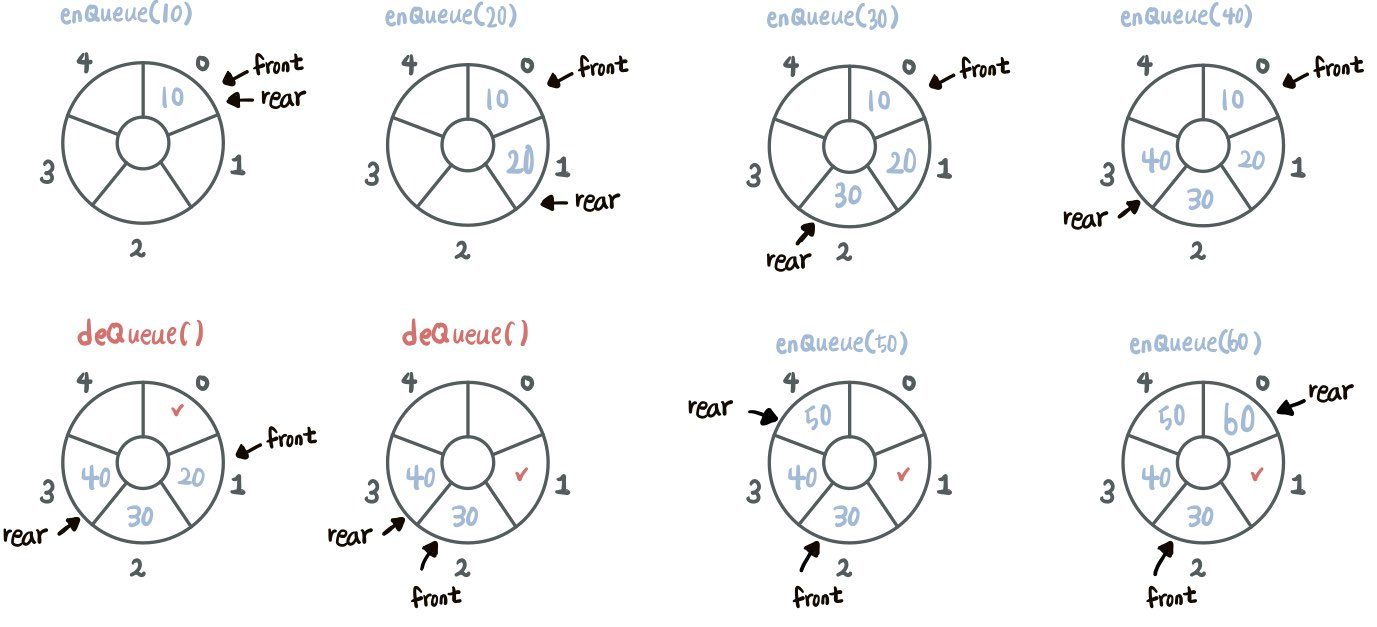
- front, rear 포인트가 enqueue, dequeue 시마다 빙글빙글 돌면서 이동하는 구조가 된다.
- python 코드 구현
class CircularQueue:
# 해당 배열의 크기를 인자로 받아 초기화
def __init__(self, k):
self.q = [None] * k
self.len = k
self.front = 0
self.rear = 0
def en_queue(self, value: int) -> bool:
if self.q[self.rear] is None:
self.q[self.rear] = value # rear이 가르키는 자리에 value삽입
self.rear = (self.rear + 1) % self.maxlen
# 다음 자리로 rear포인터 이동.
# 길이가 넘어가면 나머지 연산자를 이용하여 한바퀴 돌아서 자리찾기
return True
else
return False- self.rear ( rear 포인터 ) 에 값을 넣고, rear 를 한칸 앞으로 이동시킨다.
- 길이를 넘어갈것을 방지하기위해 나머지 연산을 하여 포인터 위치가 전체길이를 벗어나지 않게 한다.
- rear 가 가리키는값이 None아 아니라면 공간이 찬 상태이거나, 비정상적인 경우이므로 False를 리턴한다.
def de_queue(self):
if self.q[self.front] is None:
return False #이미 내보낼것이 없는 상태 ->False
else:
result = self.q[self.front] # result 변수에 배열의 첫번째 요소를 답는다.
self.q[self.front] = None # 삭제
self.front = (self.front + 1) % self.maxlen
return result - ( front 포인터 ) 의 위치에 None을 넣어 삭제하고, 포인터를 한칸 앞으로 이동시킨다.
- 나머지 연산으로 최대 길이를 넘지 않도록 한다.
class CircularQueue:
# 해당 배열의 크기를 인자로 받아 초기화
def __init__(self, k):
self.q = [None] * k
self.len = k
self.front = 0
self.rear = 0
# 삽입 메소드
def en_queue(self, value):
if self.q[self.rear] is None:
self.q[self.rear] = value # rear 포인터에 입력받은 인자를 넣는다.
self.rear = (self.rear + 1) % self.len # 전체길이로 나머지연산을 하여 포인터가 전체기리를 넘지 못하게 이동시킨다.
return True
else:
return False
# 추출 메소드
def de_queue(self):
if self.q[self.front] is not None:
result = self.q[self.front] # result 변수에 배열의 첫번째 요소를 답는다.
self.q[self.front] = None # 배열의 첫번쨰요소를 삭제
self.front = (self.front + 1) % self.len
return result # result 변수 리턴
else:
return False
# 배열의 첫번째 요소 출력
def pr_front(self):
return False if self.q[self.front] is None else self.q[self.front]
# 배열의 마지막 요소 출력
def pr_rear(self):
return False if self.q[self.rear] is None else self.q[self.rear]
# 배열이 비어있는지 확인
def is_empty(self):
return self.q[self.front] == None and self.q[self.rear] == None
# 배열이 꽉 차있는지 확인
def is_full(self):
return None not in self.q시간복잡도
- 가장 간단한 정의는 알고리즘의 성능을 설명한 것.
- 알고리즘을 수행하기 위헤 프로세스가 수행해야하는 연산을 수치화 한것.
Big-O 표기법

- 시간복잡도란 특정 알고리즘이 어떤 문제를 해결하는데 걸리는 시간을 의미한다.
- 입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다.
- Big-O로 측정되는 복잡성에는 시간/공간 복잡도가 존재한다.
- 공간복잡도는 알고리즘이 실행댈 때 사용하는 메모리의 양을 나타내지만, 메모리의 발전으로 중요도가 낮아졌다.
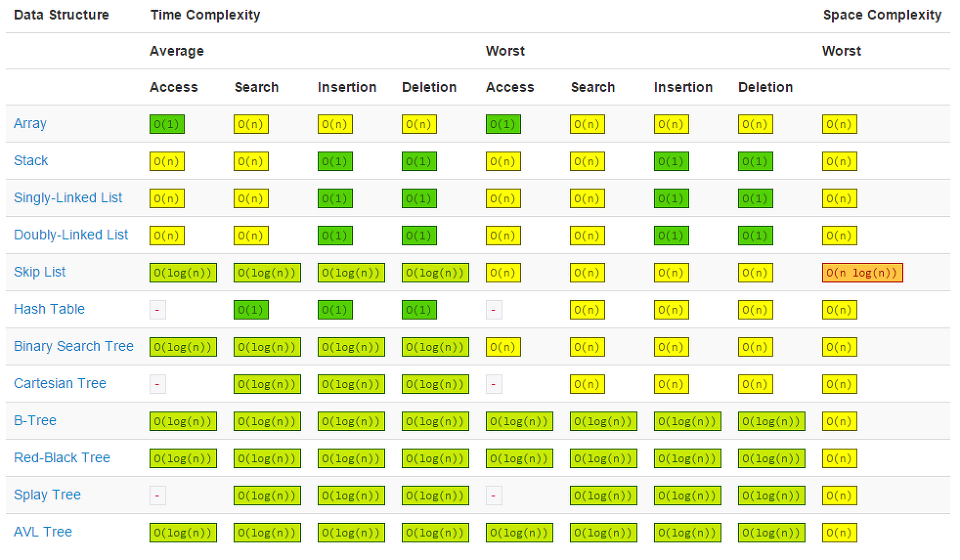
시간복잡도 종류

맨위에서부터 시간 복잡도가 낮고 빠르고, 아래로 갈수록 시간 복잡도가 높고 느려진다.
제한된 시간 안에 올바르게 output을 출력하려면 시간 복잡도를 낮춰야한다.
어떻게 줄일수 있을까?
- 반복문의 숫자를 줄인다.
- 반복문은 시간복잡도에서 가장 시간소모에 큰 영향을 미친다.
- 자료구조를 적절하게 이용한다.
- 알고리즘을 적절하게 이용한다.
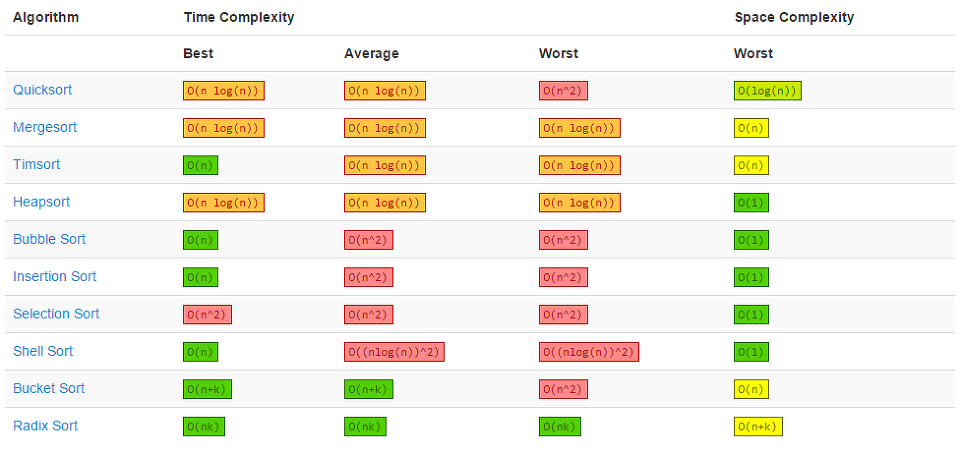
효율적인 알고리즘을 공부해서 적절할때 사용하면 큰 효과를 볼 수 있다.
DFS 알고리즘
깊이 우선 탐색 (DFS, Depth-First Search)
- 다음 분기로 넘어가기전 해당 분기를 완벽하게 탐색하고 넘어가는 탐색방법
- 예를들어 미로를 탐색할때 갈 수 있을 때까지 계속 가다가 더 이상 갈수 없게 되면 다시 가장 가까운 갈림길로 돌아와서 다른 방향으로 다시 탐색을 진행하는 방법과 유사
- 넓게(Wide) 탐색하기전에 깊게(Deep) 탐색하는 것
- 모든 정점를 방문하고자할 경우 DFS를 선택
- 같은 정점을 다시 방문하지 않도록 한번 방문한 곳에 표시를 해준다.
- 재귀 함수를 통해 구현한다.
DFS 작동 원리
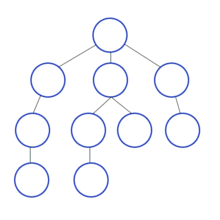
시작점에서 한 갈래로 더 이상 갈 수 없을 때까지 탐색하고, 더 갈 곳이 없다면 이전 경로로 되돌아가서 다시 탐색을 시작한다.
그래프 구현
def dfs_graph(node_id: int):
"""
visit(node_id) : id가 node_id 인 정점을 방문한 것으로 표시
linked_node(node_id) : 현재 정점(node_id)와 연결된 다른 정점의 목록 반환
is_visit(node_id) : id가 node_id인 정점을 방문했는지 여부를 반환
"""
visit(node_id) # 방문 표시
for node in linked_node(node_id):
# 방문하지 않은경우 재귀로 탐색
if is_visit(node.get_id() != True:
dfs_graph(node.get_id())2차원 이동 구현
def dfs_coordinate(x: int, y: int):
"""
is_valid(x, y) : 좌표값이 x, y인 접점을 방문할 수 있는지, 좌표값이 유효한지 반환
"""
visit(x, y) # 방문 표시
# 위로 이동
if is_valid(x, y - 1):
dfs_coordinate(x, y - 1)
# 아래로 이동
if is_valid(x, y + 1):
dfs_coordinate(x, y + 1)
# 왼쪽으로 이동
if is_valid(x - 1, y):
dfs_coordinate(x - 1, y)
# 오른쪽으로 이동
if is_valid(x + 1, y):
dfs_coordinate(x + 1, y)장점
- 코드가 직관적이고 구현하기 쉽다. (재귀함수의 흐름을 이해했다는 가정하에)
단점
- 재귀함수 때문에, 함수 호출 비용이 추가로 들어간다.
- 재귀 깊이가 지나치게 깊어지면 메모리 비용을 에측하기 어렵다.
- 데이터 사이즈가 일정 이상이면 DFS를 사용하지 않는것이 좋다.
- 최단 경로를 알수없다.
BFS 알고리즘
너비 우선 탐색 (BFS, Beradth-First Search)
- 시작점에서 가까운 정점부터 순서대로 방문하는 탐색 알고리즘
- 큐를 이용하여 구현한다.
- 출발점을 큐에 넣고, 다음로직을 반복
- 큐에 저장된 정점을 Dequeue 진행
- Dequeue된 정점과 연결된 모든 정점을 큐에넣는다.
- 큐가 비어있다면 반복을 종료
- 두 노드사이의 최단 경로, 혹은 임의의 경로를 찾고 싶을 때 주로 사용된다.
- 깊이 우선 탐색보다 좀 더 복잡하다.
BFS 작동원리
그래프
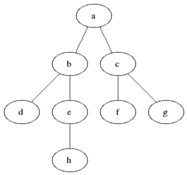
[ a ] → [ b, c ] → [ c, d, e ] → [ d, e, f, g ] → [ e, f, g ] → [ f, g, h ] → [ g, h ] → [ h ] → [ ] ⇒ 탐색 종료
2차원
- 시작점 기준으로 거리가 1인 모든 지점을 큐에 저장, 이후 2인 지점 탐색 큐에저장하는 식으로 모든 지점을 탐색
- 목표지점을 찾으면 탐색 종료, 찾지못하면 연결된 모든 지점을 탐색
그래프 코드 구현
from collections import deque
queue = deque([])
def bfs_graph(start_node_id: int):
"""
visit(node_id) : id가 node_id인 정점을 방문한 것을 표시
is_visit(node_id) : id가 node_id인 정점을 방문했는지 여부
target_id : 목적지 id
linked_node(node_id) : 현재 정점(node_id)와 연결된 다른 정점의 목록 반환
"""
queue.append(start_node_id)
while queue:
node_id = queue.popleft()
visit(node_id)
if target_id == node.get_id():
return node
for node in linked_node(node_id):
# 해당 정점과 연결된 다른 정점의 리스트를 순회하며 qeueu에 넣어준다.
if is_visit(node.get_id()) is False:
queue.append(node.get_id())2차원 이동 코드 구현
from collections import deque
queue = deque()
def bfs_coordinate(x, y):
"""
visit(x, y) : 좌표값이 x, y인 정점을 방문한 것으로 표시
is_valid(x, y) : 좌표값이 x, y인 정점을 방문할 수 있는지, 유효한지 반환
target_postion : 목적지의 위치 좌표값
x : 출발한 정점의 x 좌표 위치값
y : 출발한 정점의 y 좌표 위치값
"""
queue.push(Position(x, y))
while (queue.is_not_empty()):
position = queue.pop()
# 방문 처리 후, 목적지라면 로직 종료
visit(position.x, position.y)
if target_position.equals(position):
return
# 위로 이동
if is_valid(x, y - 1):
queue.append(x, y - 1)
# 아래로 이동
if is_valid(x, y + 1):
queue.append(x, y + 1)
# 왼쪽으로 이동
if is_valid(x - 1, y):
queue.append(x - 1, y)
# 오른쪽으로 이동
if is_valid(x + 1, y):
queue.append(x + 1, y)장점
- 효율적 운영이 가능, 시간/공간 복잡도 면에서 안정적이다.
- 간선의 비용이 모두 같을 경우, 최단 경로를 구할 수 있다.
- 간선의 비용이 각각 다를 경우(간선을 지나갈때 추가적인 비용이 드는 경우), 한번에 갈수있는 방법은 알지만, 그것이 가장 효율적인지는 알지 못한다.
- 다익스트라 알고리즘 등의 최단거리 알고리즘을 활용해야함
- 간선의 비용이 각각 다를 경우(간선을 지나갈때 추가적인 비용이 드는 경우), 한번에 갈수있는 방법은 알지만, 그것이 가장 효율적인지는 알지 못한다.
단점
- DFS에 비해 코드 구현이 어렵다.
- 모든 지점을 탐색할 경우를 대비해 큐의 메모리가 미리 준비되어 있어야한다.
탐색 알고리즘 예제문제
백준 1260 DFS 와 BFS : 그래프에서 DFS / BFS 연습문제
문제
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
4 5 1
1 2
1 3
1 4
2 4
3 4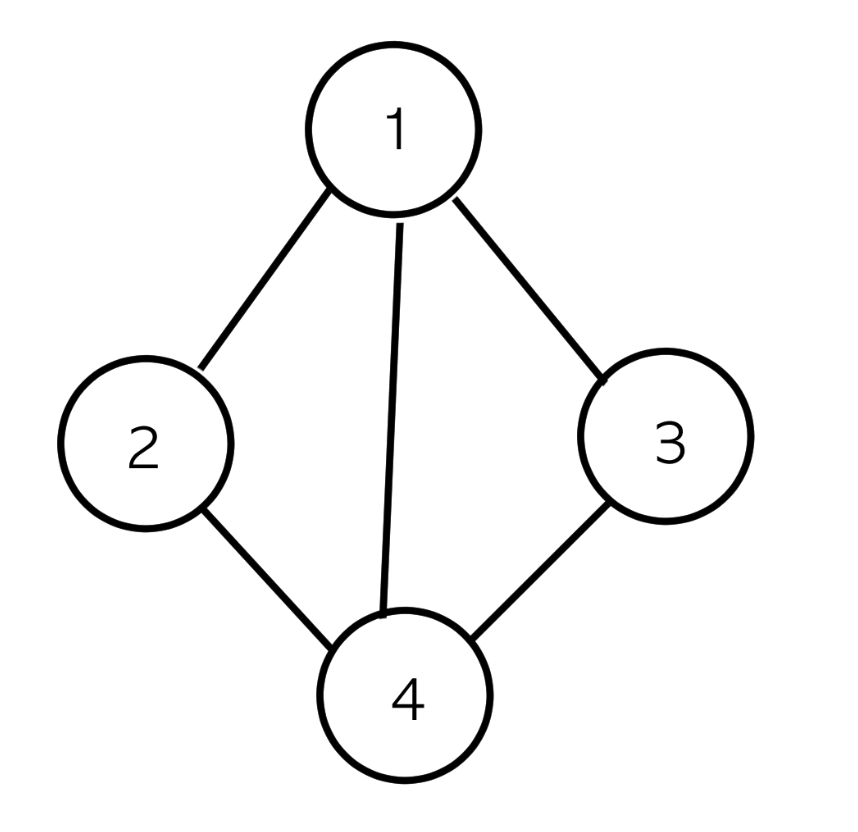
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
1 2 4 3
1 2 3 4풀이
from collections import deque
n, m, v = map(int, input().split()) # 입력값 할당
"""
n : 정점의 개수
m : 간선의 개수
v : 시작 정점
"""
graph = [[0] * (n + 1) for _ in range(n + 1)]
dfs_visit = [0] * (n + 1)
bfs_visit = [0] * (n + 1)
"""
n + 1로 진행한 이유는 리스트는 index가 0부터지만,
입력값은 1부터 시작하기 때문에 맞추기 위해서입니다.
"""
for _ in range(m):
"""
간선의 개수만큼 그래프에 정점간 연결을 표현해줍니다.
"""
a, b = map(int, input().split())
graph[a][b] = graph[b][a] = 1
# 깊이우선탐색
def dfs(v):
dfs_visit[v] = 1 # 시작점을 방문점으로 표시
print(v, end = " ")
for i in range(1, n + 1):
if dfs_visit[i] == 0 and graph[v][i] == 1:
# i에 방문한적이 없고, v와 i가 간선으로 연결되어 있는 경우 i에서 다시 깊이들어간다.
dfs(i)
# 너비우선탐색
def bfs(v):
queue = deque()
queue.append(v) # 시작점을 queue에 넣어주고 시작
bfs_visit[v] = 1 # 시작점 - 방문 표시
while queue:
# queue가 빌때까지 반복
v = queue.popleft()
print(v, end = " ")
for i in range(1, n + 1):
if bfs_visit[i] == 0 and graph[v][i] == 1:
# i에 방문한 적이 없고, v와 i가 간선으로 연결이 되어있는 경우
queue.append(i)
# i는 v와 연결되어있는 정점이므로 queue에 넣어준다.
bfs_visit[i] = 1
# 방문한것으로 표시
dfs(v)
print()
bfs(v)탐색 알고리즘의 활용
Flood Fill Algorithm (NHN 코딩테스트)

문제
n x m 크기 도화지에 그려진 그림의 색깔이 2차원 리스트로 주어집니다. 같은 색깔은 같은 숫자로 나타난다고 할 때, 그림에 있는 영역은 총 몇 개인지 알아내려 합니다. 영역이란 상하좌우로 연결된 같은 색상의 공간을 말합니다.
예를 들어, [[1,2,3], [3,2,1]] 같은 리스트는 다음과 같이 표현할 수 있습니다.

총 5개의 영역을 가짐
도화지의 크기 n과 m, 도화지에 칠한 색깔 image가 주어질 때,
그림에서 영역이 몇 개 있는지 리턴하는 solution 함수를 작성해주세요.
입력 / 출력
n m images 출력
2 3 [[1, 2, 3], [3, 2, 1]] 5
3 2 [[1, 2], [1, 2], [4, 5]] 4풀이
좌표를 0, 0에서부터 n, m까지 순회하면서 방문되지 않은 노드를 확인한다.
BFS를 진행하면서 같은 색을 가진 인접 노드를 방문처리해준다.
from collections import deque
def visitable(n, m, y, x):
# 방문할 수 있는지에 대한 여부
return 0 <= y < n and 0 <= x < m
def solution(n, m, image):
visited, bfs_nodes = set(), deque([])
DELTAS = [(1, 0), (-1, 0), (0, 1), (0, -1)]
answer = 0
for y in range(n):
for x in range(m):
if (y, x) in visited:
# 만약 y, x 좌표가 방문기록이 있다면 해당 loop 건너 뜀
continue
answer += 1 # 방문하지않았다면 answer를 1 더해주고
bfs_nodes.append((y, x)) # bfs 노드에 넣어준다.
visited.add((y, x)) # 방문했다는 표시를 남겨준다.
while bfs_nodes: # bfs 노드가 빌때까지 반복을 진행한다.
cur_y, cur_x = bfs_nodes.popleft()
# bfs 노드의 첫번째요소의 좌표를 추출한다.
for dx, dy in DELTAS:
# DELTA 리스트를 이용해, 해당위치에서 이동할 수 있는 값을 찾는다.
next_y, next_x = cur_y + dy, cur_x + dx
if visitable(n, m, next_y, next_x) and \
(next_y, next_x) not in visited and \
image[cur_y][cur_x] == image[next_y][next_x]:
# 만약 해당지점에 이동할 수 있고, 방문한적이 없으며,
# 같은 색상을 갖는다면,
bfs_nodes.append((next_y, next_x))
visited.add((next_y, next_x))
# 해당 지점을 bfs 노드에 넣어주고, 방문한것으로 표시한다.
# 이렇게 처리하면, 같은색상의 경우는 방문처리가 되고,
# n,m 순회시 해당 지점에 오면 asnwer값이 늘어나지않는다.
return answer