
목표
- 한국거래소에서 기업별 코드 리스트를 가져온다.
- 일별 시세를 알고 싶은 기업명을 입력하면 해당 기업의 코드값을 찾아 네이버 금융에 검색한다.
- 검색한 결과를 가져와 일별 시세 차트를 만든다.
필요한 패키지
pip install pandas
pip install matplotlib
pip install plotly
pip install lxml
pip install requests파일구조
| 파일명 | 내용 |
|---|---|
| main.py | 프로그램 실행 |
| krx.py | 한국거래소에서 기업코드 가져오기 |
| stock.py | 네이버 금융에서 특정회사의 일별 시세 데이터 가져오기 |
1. 입력받은 회사명의 종목코드를 가져오는 함수 만들기
📄 krx.py
import pandas as pd
def get_stock_code(company):
## 한국거래소에서 종목코드 리스트 가져오기
KRX_code = pd.read_html('http://kind.krx.co.kr/corpgeneral/corpList.do?method=download', header=0)[0]
## 최신 상장순으로 정렬
KRX_code = KRX_code.sort_values(['상장일'], ascending=False)
## 필요한 칼럼만 가져오기
KRX_code = KRX_code[['회사명', '종목코드']]
## 컬럼명 영어로 바꾸기
KRX_code = KRX_code.rename(columns={'회사명': 'company', '종목코드': 'code'})
## 종목코드 6자리로 포맷 맞추기
KRX_code['code'] = KRX_code['code'].map('{:06d}'.format)
## 입력받은 회사명과 일치하는 code 값 가져오기
code = KRX_code[KRX_code['company'] == company]['code'].values[0].strip()
return code
2. 네이버 금융에서 일별 시세 데이터 가져오는 함수 만들기
User-agent 값 확인하기
requests를 전송할 때 오류가 발생했다.
이를 해결하기 위해 User-agent를 header에 넣어 요청했다.
User-agent 값을 확인하는 방법은 다음과 같다.
- https://www.useragentstring.com 접속한다.
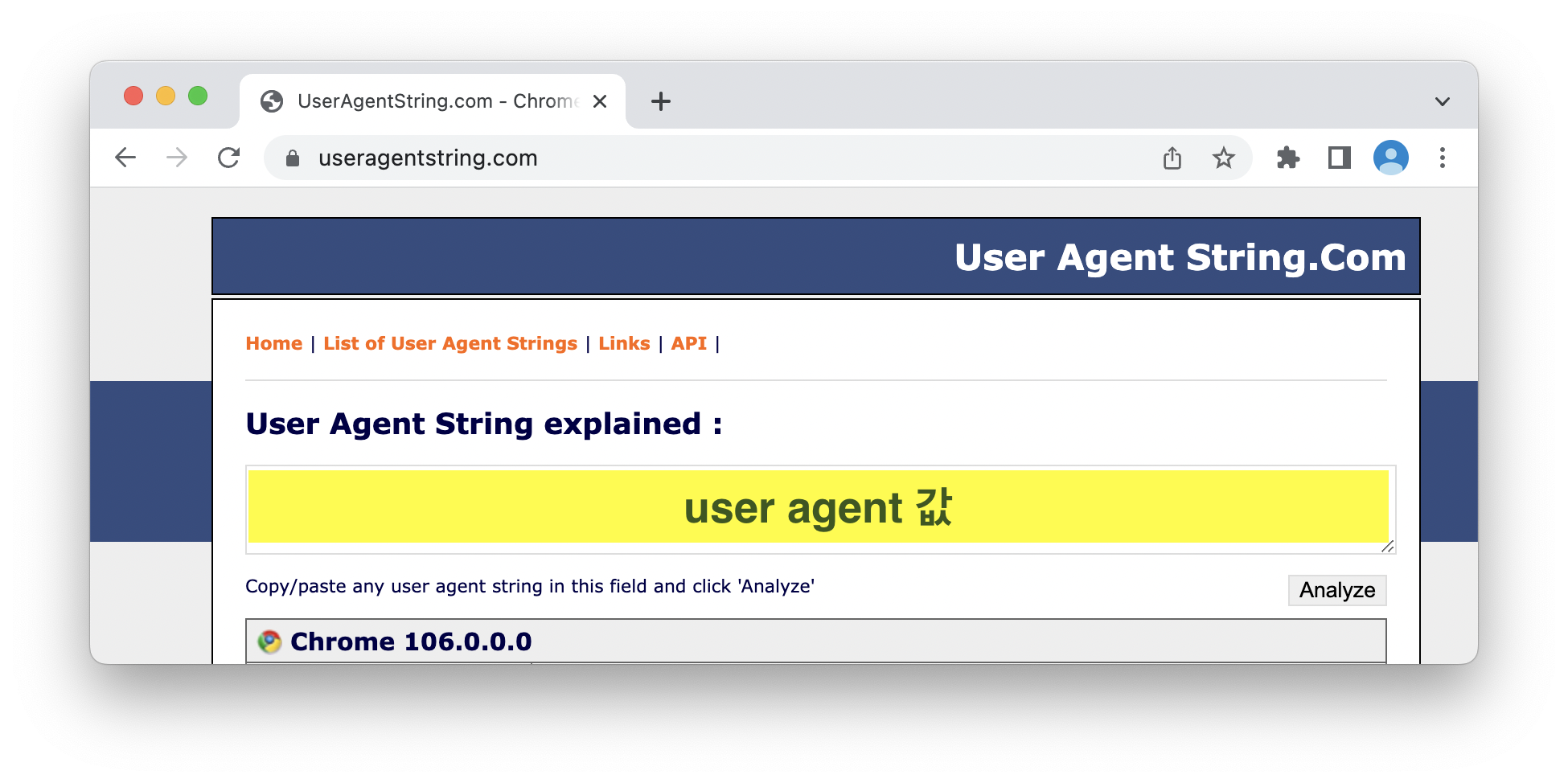
- 노란색 영역에 있는 값들이 User-agent 값이다.
📄 stock.py
import requests
import pandas as pd
from krx import get_stock_code
def get_daily_stock_info_by_company(company):
code = get_stock_code(company)
## 헤더에 user-agent 값 보내기
header = {
'User-Agent': '<User-agent 값>'}
df = pd.DataFrame()
for page in range(1, 21):
url = f"https://finance.naver.com/item/sise_day.naver?code={code}&page={page}"
res = requests.get(url, headers=header)
result = pd.read_html(res.text, header=0)[0]
## '날짜' 칼럼이 NaN 인 행은 삭제하기
result = result.dropna(subset=['날짜'])
df = pd.concat([df, result])
## 칼럼명 영어로 수정
df = df.rename(
columns={'날짜': 'date', '종가': 'close', '전일비': 'diff', '시가': 'open', '고가': 'high', '저가': 'low', '거래량': 'volume'})
## 데이터 타입 바꾸기
df[['close', 'diff', 'open', 'high', 'low', 'volume']] = df[
['close', 'diff', 'open', 'high', 'low', 'volume']].astype(int)
df['date'] = pd.to_datetime(df['date'])
## 일자별로 오름 차순 정렬
df = df.sort_values('date', ascending=True)
return df
✏️ Note
네이버 금융의 일별 시세는 총 20 페이지이다. 반복문을 통해 20 페이지까지 있는 모든 데이터를 불러와 df에 담았다.
❗️이때 df.append()를 사용해도 좋지만 권장하지 않아 concat을 사용하여 데이터프레임을 하나로 합쳤다.
3. 일별 시세 차트 그리기
단순 그래프
📄 main.py
import matplotlib.pyplot as plt
import plotly.express as px
from stock import get_daily_stock_info_by_company
company = '삼성전자'
df = get_daily_stock_info_by_company(company)
## 단순 차트 그리기
plt.figure(figsize=(10,4))
plt.plot(df['date'], df['close'])
plt.xlabel('')
plt.ylabel('close')
plt.tick_params(
axis='x',
which='both',
bottom=False,
top=False,
labelbottom=False)
plt.savefig(company + ".png")
plt.show()결과
- 회사명.png 파일 생성
- 결과 출력
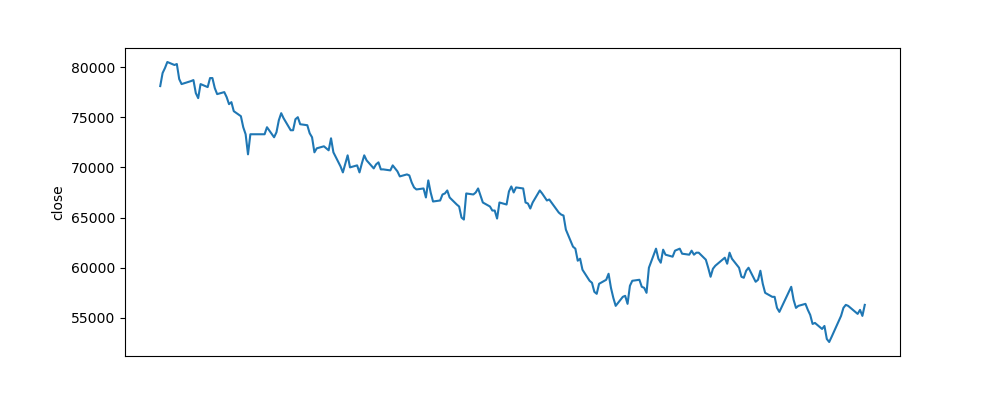
반응형 그래프
## main.py 기존 코드에 이어서 작성
## 반응형 차트 그리기
fig = px.line(df, x='date', y='close', title='{}의 종가(close) Time Series'.format(company))
fig.update_xaxes(
rangeslider_visible=True,
rangeselector=dict(
buttons=list([
dict(count=1, label="1m", step="month", stepmode="backward"),
dict(count=3, label="3m", step="month", stepmode="backward"),
dict(count=6, label="6m", step="month", stepmode="backward"),
dict(step="all")
])
)
)
fig.show()
fig.write_html("file.html")결과
- file.html 파일 생성
- 결과 출력
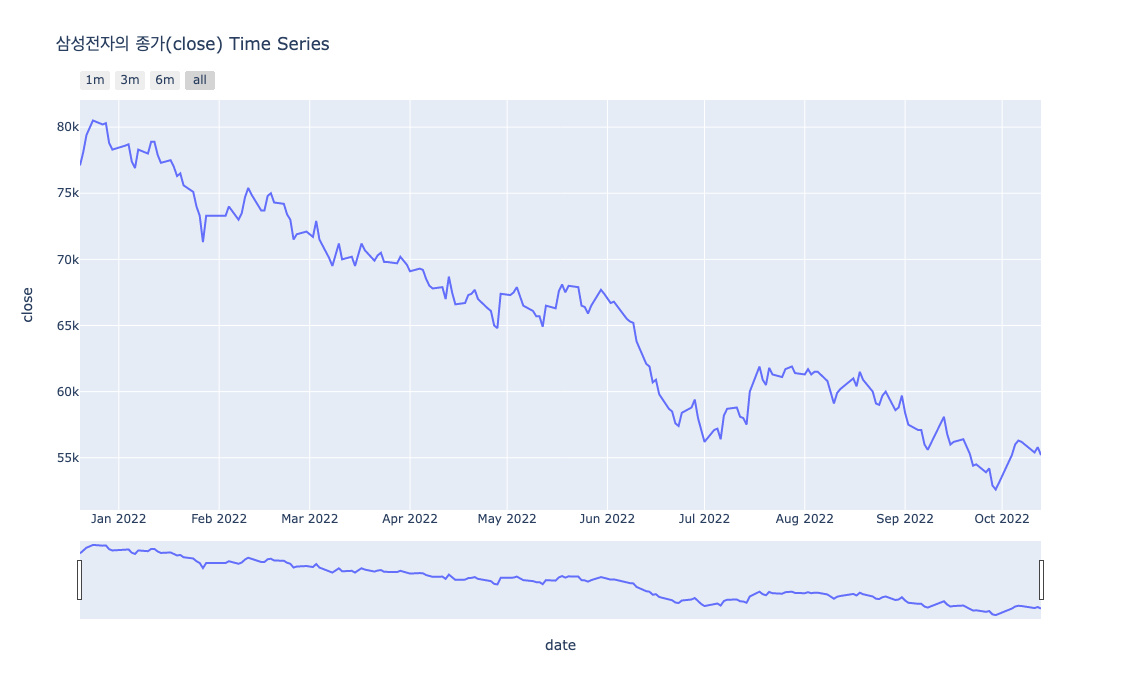
참고자료
해당 포스팅은 https://ai-creator.tistory.com/51 를 바탕으로 작성했습니다.

올해보단 낫겠지....