MongoDB
Atlas Platform
- Full- text search queries 지원
- Data-tiering을 사용해서 오래된 (3개월이상)된 데이터들을 자연스럽게 S3로 내려줄 수 있다. (Federated queries using MQL)
- Native visualization of MongoDB data (Chart 형태로 data를 그려준다) => 현재는 한국에서 지원이 안되고 있음
- Edge to cloud synchronization (Firebase같은 기능을 갖고 있다) => 이것도 싱가폴에만 서버가 있기에 아직 한국 지원 미정
Compass
Basic Database CRUD Interactions
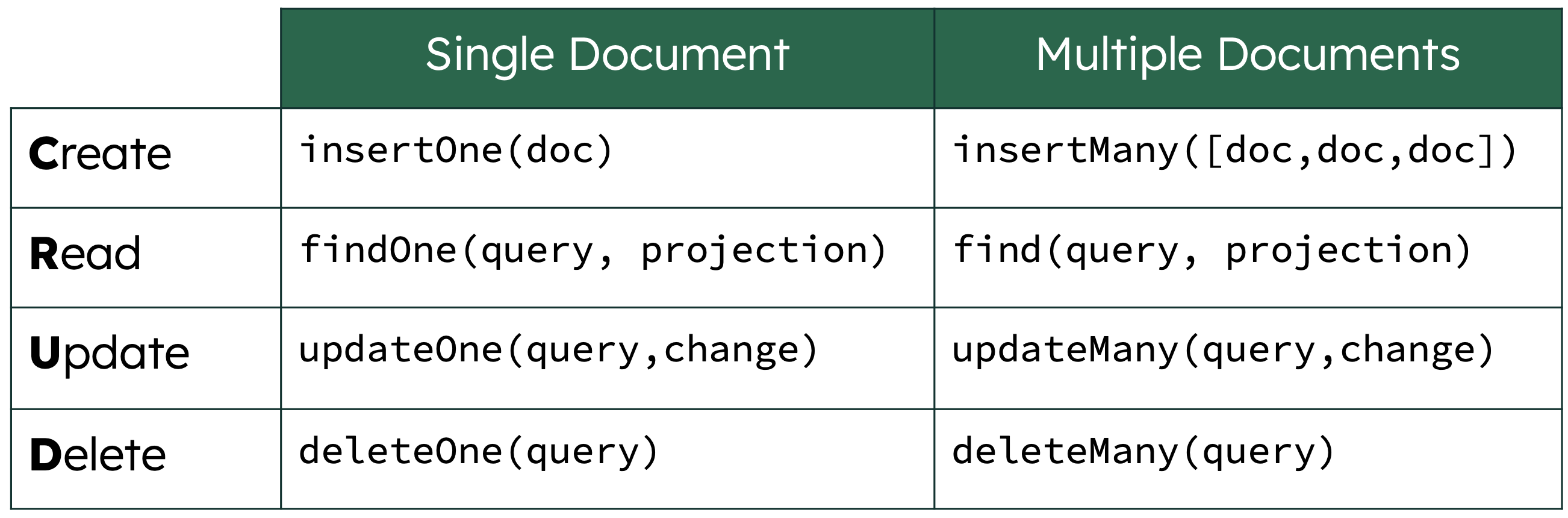
Create
insertOne()
- _id 는 pk같은 역할을 한다
- _id를 안넣을시 몽고디비는 알아서 _id를 생성해준다
insertMany()
- 배열 형태의 documents를 허용한다
- insertOne보다 network time을 줄일 수 있다.
- ordered(default) 옵션은 첫번째 에러에 멈춘다
- unordered 옵션은 에러가 나도 report만 하고 작업을 계속 진행한다.
Read
findOne()
- 빈 객체를 넣을시 모든 것을 포함한다는 뜻이다
find()
- 모든 객체들을 불러온다
- Cursor 이라는 개념을 통해 db를 조회할 떄 limit, skip을 수행할 수 있다
- projection에 value를 0으로 넣으면 필요 없는 값을 뺄 수 있다.
- 필요한 값은 아래처럼 1을 넣어준다.
db.diaries.find({},{_id: 0, name: 1, txt: 1}).skip(1).limit(1)Querying values in nested documents
- 중첩된 데이터에 접근하기 위해선 “” 와 . 을 활용한다
db.people.findOne({ “address.city” : “New York”})Query by ranges of values
- operators를 사용하게 된다
- ex) $in - true 같은 형태로 사용한다
db.inspections.find({$or:[{result:"Pass"} ,{result: "Fail"}]}).count() Array specific query operators
- array 형태의 db를 query할 때 유용하다
- $all
- $size
- $elemMatch : array의 각각의 element들의 대해서 query를 돌린다
db.restaurants.find({grades: { $elemMatch: { grade: "C", date: {$gt: ISODate("2013-12-31")}}}}).count()Sorting Results
- 정렬이고 cursor에 속한다
- ex) sort(), 값은 -1 과 1로 지정한다
db.scores.find({},{_id:0}).sort({swim:1, ride:-1}) Update
updateOne(query, mutation)
- 조건에 해당 첫번째 되는 값만 업데이트 한다
updateMany(query, mutation)
- 조건에 해당되는 모든 되는 값들을 업데이트 한다
mutation
- $set opertator : 해당 필드를 대체 및 수정
- $unset operator : 해당 필드를 삭제
- $inc & $mul operator: 연산 업데이트
- $min & $max operator: 최소 및 최대값 비교 업데이트
- $push & $pop operator: 배열 업데이트
- $addToSet operator: 중복없는 배열 업데이트
replaceOne()
- 사용 안하는것을 권장 => $set 사용 권장
upsert
- 들어오는 데이터가 있으면 upsert 없으면 insert를 진행한다.
Indexes and Optimizatioon
Indexes가 필요한 이유
- queries 와 update의 속도차이
- disk I/O를 피할수 있다
- overall computation을 줄일수 있다
Replication
Replication을 쓰는 이유
- High Availability(HA)
- 서버, 네트워크 스위치, 데이터센터가 중지되거나 문제가 생기더라도 DB 사용 가능하도록 한다
- Reduced Read Latency
- 거리적으로 제일 가깝게 복제된 디비를 가져오기 때문에 지연이 없다
- Different Access Patterns
- 다양한 사용패턴에 용이하다
Replica Set Components
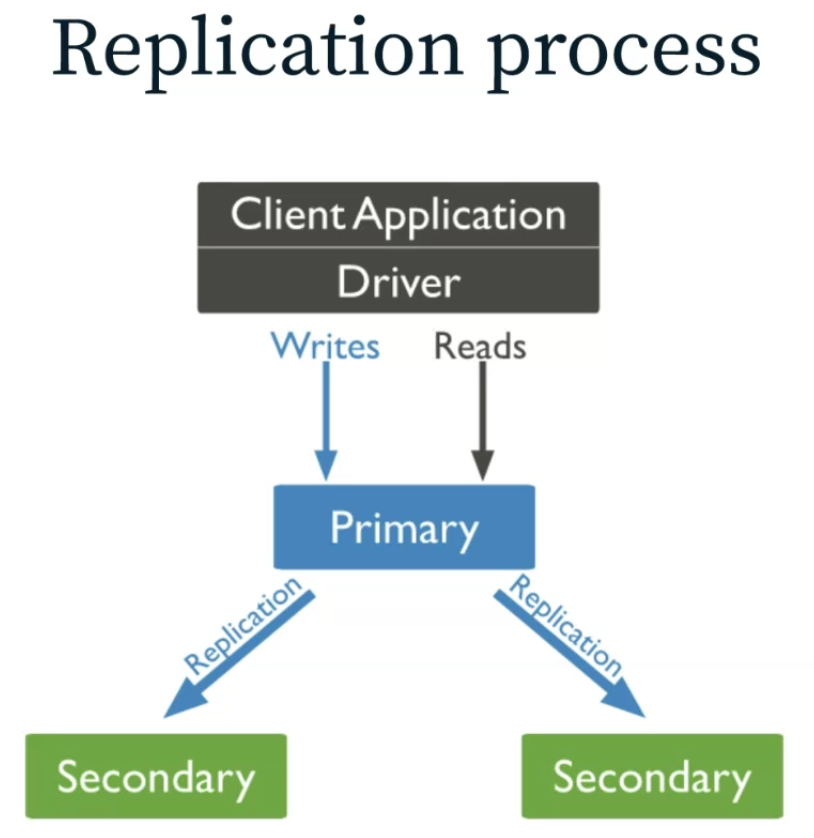 1. Primary Member
2. Secondary Members
- Secondary는 Primary data set의 복제본을 갖고있는다.
3. Non-voting Members
1. Primary Member
2. Secondary Members
- Secondary는 Primary data set의 복제본을 갖고있는다.
3. Non-voting Members
Oplog
Operation log는 읽기전용 BSON 문서이다.
- 쓰기에 대한 변경이 있을경우 Oplog에 저장되는 형식으로 진행된다.
- 데이터베이스의 바이너리 폼에서 독립적인 환경을 갖는다.
Aggregation
Basic Aggregation Stages
- $match equivalent to find(query)
- $project equivalent to find({},projection)
- $sort equivalent to find().sort(order)
- $limit equivalent to find().limit(num)
- $skip equivalent to find().skip(num)
- $count equivalent to find().count()
Aggregation Syntax 비교
- Using find()
db.listingsAndReviews.find(
{"address.country":"Canada"},
{"host.host_total_listings_count":1,"host.host_name":1}
).sort({"host.host_total_listings_count":-1}).limit(1)- Using aggregate()
db.listingsAndReviews.aggregate([
{$match:{"address.country":"Canada"}},
{$sort:{"host.host_total_listings_count":-1 }},
{$limit:1},
{$project:{
"host.host_total_listings_count":1,
"host.host_name":1}}
])- 성능적으로 보면 find()가 더 빠르기 때문에 find()를 쓸 수 있다면 쓰는 것을 권장한다.
Dollar Overloading
- {$match: {a: 5}} - Dollar on left means a stage name - in this case a $match stage
- {$set: {b: "$a"}} - Dollar on right of colon "$a" refers to the value of field a
- {$set: {area: {$multiply: [5,10]}} - $multiply is an expression name left of colon
- {$set: {priceswithtax: {$map: {input: "$prices",
as: "p",
in: {$multiply :["$$p",1.08]}}}}}
$$p Refers to the temporary loop variable "p" declared in $map
- {$set: {displayprice: {$literal: "$12"}}} - Use $literal when you want either a string with a $ or to $project an explicit numberThe $group stage
SQL의 GROUP BY와 가장 비슷한 결과물을 낸다.
- $addToSet : array of unique expression values
- $avg : average of numerical values
- last : value from the first or last document for each group
- min : highest or lowest expression value for each group
- $mergeObjects : document combined by input documents for each group
- $push : array of expression values for each group
- $stdDevSamp : sample standard deviation of the input values
- $sum : sum of numerical values
The $unwind stage
$group과 반대로 하나의 문서를 여러개로 나눠주는 기능이다.
Example: Having this initial document - { a: 1, b: [2,3,4] }
Unwind on b ({$unwind: "$b"}) gives 3 documents in the pipeline:
{a:1,b:2}, {a:1,b:3}, and {a:1,b:4}Data Modeling
Data Modeling Process
- 어플리케이션에서 데이터를 어떻게 쓸지 access pattern을 분석한다
- access pattern에 따라 관계도를 읽는다
좋은 모델은 무엇일까?
- 내가 표현하고자하는 모든 데이터가 들어가 있는지
- 좋은 쿼리 성능
- 데이터 변경에 대한 Flexibility
- 하드웨어에 따라서 최적화를 시킬 수 있는지
- 개발자의 Productivity
- 확장 가능성
BSON
- 몽고DB는 BSON 형태로 데이터를 저장한다.
- JSON보다 data types가 더 많다.
- images or videos 같은 바이너리 형태의 데이터를 저장하는 것도 가능하다.
- 최대 16MB까지 저장할 수 있다.
Arrays vs Documents
배열 vs 객체라고 생각하면 쉽다.
Documents
- 다큐먼트는 nested 될 수 있다.
- 중복된 field를 생성 할 수 없다.
- $project로 쉽고 빠르게 필요한 값을 찾을 수 있다
- single member을 쿼링하는게 array보다 빠르다
- field를 indexing 할수 있다.
Arrays
- 여러개의 operators로 배열을 handle할 수 있다.
- ex) $elemMatch/ $all/ $size / $push/ $pop
- 배열은 두개의 컬렉션을 하나로 합칠 수 있다.
Document Model
Advantages
- Fewer Joins
- Fewer Indexes
- Fewer Updates
- Faster Retrievals
- Enabling Scalability
Relation vs Document Model
RDBMS - one correct design
- 3rd Normal Form
- Design based on the data, not the usage
- REality is more nuanced
Document - Design Parttern
- Many design options
- Designed for a usage pattern
- Retrieval(Fast retrieval)
Schema Design in MongoDB
- 스키마는 application-level에서 정의된다.

만들고 싶은게 많은 개발자