1. Subquery
: 쿼리 안의 쿼리라는 의미, 하위 쿼리의 결과를 상위 쿼리에서 사용하면, SQL 쿼리가 훨씬 간단하고 편하게 데이터를 얻을 수 있음.
: 하나의 SQL 쿼리 안에 또다른 SQL 쿼리가 있는 것을 의미
: 안에 있는 쿼리 먼저 작동되고 그뒤에 큰 쿼리가 작동1-1 where : 이미 뽑아놓은거 안에 이 쿼리 안에 있니?
+ Where은 조건문으로 Subquery의 결과를 조건에 활용하는 방식으로 유용하게 사용
+ where 필드명 in (subquery)카카오페이로 결제한 주문건 유저들만, 유저 테이블에서 출력
SELECT user_id, name, email FROM users u
WHERE user_id in (
SELECT user_id FROM orders o
WHERE payment_method = 'kakaopay'
)
쿼리 실행 순서
(1) from 실행: users 데이터를 가져와줌
(2) Subquery 실행: 해당되는 user_id의 명단을 뽑아줌
(3) where .. in 절에서 subquery의 결과에 해당되는 'user_id의 명단' 조건으로 필터링 해줌
(4) 조건에 맞는 결과 출력
1-2 selet : 뽑을때마다 실행되게!
+ Select는 결과를 출력, 기존 테이블에 함께 보고싶은 통계 데이터를 손쉽게 붙이는 것에 사용
+ select 필드명, 필드명, (subquery) from ..'오늘의 다짐' 좋아요의 수가, 본인이 평소에 받았던 좋아요 수에 비해 얼마나 높고 낮은지
select c.checkin_id, c.user_id, c.likes,
(select avg(likes) from checkins c2
where c2.user_id = c.user_id) as avg_like_user
from checkins c;쿼리 실행 순서
(1) 밖의 select * from 문에서 데이터를 한줄한줄 출력하는 과정에서
(2) select 안의 subquery가 매 데이터 한줄마다 실행되는데
(3) 그 데이터 한 줄의 user_id를 갖는 데이터의 평균 좋아요 값을 subquery에서 계산해서
(4) 함께 출력해준다!
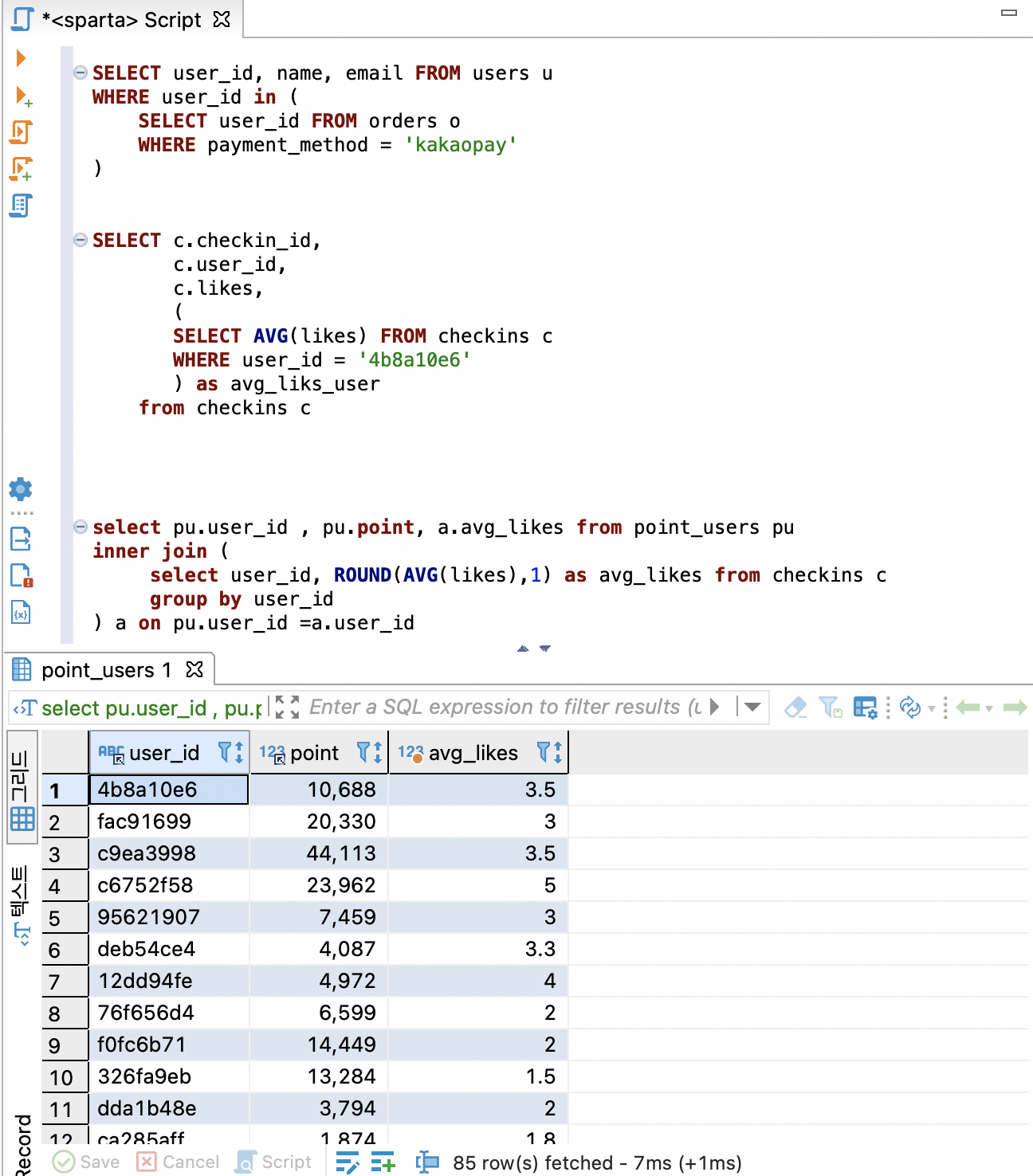
1-3 from:내가 만든 Select와 이미 있는 테이블을 Join하고 싶을 때
가장 많이 사용되는 유형!
- 우선 유저 별 좋아요 평균
- 해당 유저 별 포인트
=> 포인트와 like의 상관정도를 알 수 있음.
- 해당 유저 별 포인트
select pu.user_id , pu.point, a.avg_likes from point_users pu
inner join (
select user_id, ROUND(AVG(likes),1) as avg_likes from checkins c
group by user_id
) a on pu.user_id =a.user_id쿼리 실행 순서
(1) 먼저 서브쿼리의 select가 실행되고,
(2) 이것을 테이블처럼 여기고 밖의 select가 실행!
이씨 성을 가진 유저들의 평균 포인트보다 더 많은 포인트를 가지고 있는 데이터를 추출
select * from point_users pu
where pu.point > (
select avg(point) from users u
inner join point_users pu on pu.user_id =u.user_id
where u.name = '이**'
)둘은 동일하다
하위는 서브쿼리안에 서브쿼리가 또 들어갈 수 있음.
SELECT * from point_users pu
WHERE pu.point > (
SELECT avg(point) from point_users pu
WHERE user_id in (
SELECT user_id from users u
WHERE name = '이**'
)
)2. with : with 절로 더 깔끔하게 쿼리문을 정리

select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from
(
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) a
inner join
(
select course_id, count(*) as cnt_total from orders
group by course_id
) b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_id이걸 with를 사용해서 변경
VVVVVV
with table1 as (
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
), table2 as (
select course_id, count(*) as cnt_total from orders
group by course_id
)
select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from table1 a inner join table2 b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_id3. substring : 문자열 데이터를 원하는 형태로 한번 정리
3-1 substring_index : 문자열 쪼개보기
이메일에서 아이디만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', 1) from users이메일에서 도메인만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', -1) from users3-2 substring : 문자열 일부만 출력하기
orders 테이블에서 날짜까지 출력하게 해보기
select SUBSTRING(created_at,1,10) as date, count(*) from orders o
group by date일별로 몇 개씩 주문이 일어났는지 살펴보기
SELECT created_at, SUBSTRING(created_at,12,8) from orders o CASE : 경우에 따라 원하는 값을 새 필드에 출력
특정 조건에 따라, 데이터를 구분해서 정리해주고 싶을 때, CASE 라는 문법이 사용
10000점보다 높은 포인트를 가지고 있으면 '잘 하고 있어요!', 평균보다 낮으면 '조금 더 달려주세요!' 라고 표시해 주려면 어떻게 해야할까?
select pu.user_id, pu.point,
(CASE when pu.point > 10000 then ' 잘 하고 있어요!'
ELSE '조금만 더 파이팅!' end) as msg
from point_users pu 포인트 보유액에 따라 다르게 표시해주기> 서브쿼리를 이용해서 group by로 통계 > with 절과 함께해 정리
with table1 as (
select pu.user_id, pu.point,
(CASE when pu.point > 10000 then ' 1만 이상'
WHEN pu.point > 5000 then '5 이상'
ELSE '5천 미만' end) as lv
from point_users pu
)
select a.lv, COUNT(*) as cnt from table1 a
group by a.lv