
1. Kafka란?
Kafka는 Apache Kafka로 알려진 분산 메시징 시스템으로, 데이터 스트리밍, 메시지 큐잉, 분산 로그 처리를 위한 플랫폼이다. LinkedIn에서 처음 개발되었으며, 현재는 Apache Software Foundation에서 관리하고 있습니다. Kafka는 실시간 데이터 스트리밍 처리와 이벤트 기반 시스템에서 널리 사용된다.
2. Kafka의 주요 특징
1. 분산 시스템
Kafka는 분산 아키텍처로 설계되어 여러 서버(브로커)에서 데이터를 저장하고 처리할 수 있다. 이를 통해 확장성과 높은 처리량을 제공한다.
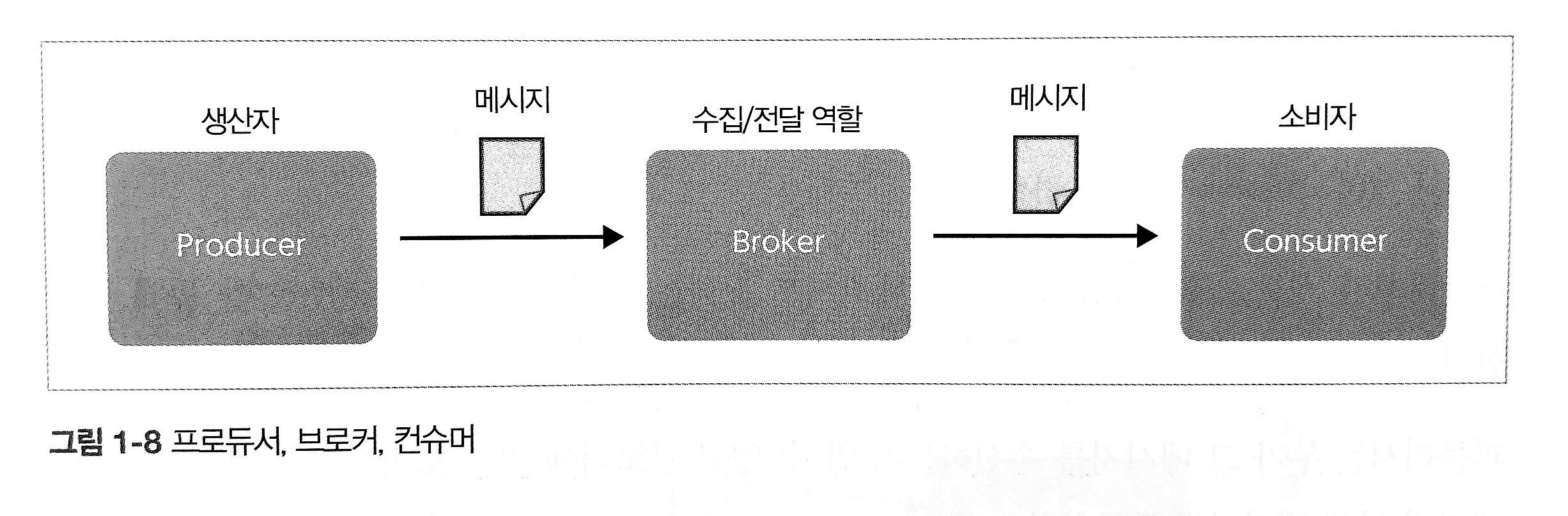
2. 내구성(Durability)
데이터를 디스크에 저장하여 내구성을 보장하며, Replication을 통해 데이터 손실을 방지한다.
3. 높은 처리량 및 저지연성
대규모 데이터 처리에 적합하며, 초당 수백만 건의 메시지를 낮은 지연으로 처리할 수 있다.
4. Publisher-Subscriber 모델
Kafka는 게시자(Publisher)와 구독자(Subscriber) 사이의 데이터를 효율적으로 전송한다.
5. 이벤트 스트리밍 플랫폼
실시간 데이터 처리뿐 아니라 데이터를 저장하고, 처리하며, 분석할 수 있는 플랫폼으로 사용된다.
3. Kafka의 주요 구성 요소
1. Producer (생산자)
- 데이터를 Kafka로 보내는 클라이언트
- 메시지를 특정 토픽(Topic)에 게시한다.
2. Consumer (소비자)
- Kafka에서 메시지를 읽는 클라이언트
- 특정 토픽을 구독하여 데이터를 소비한다.
3. Broker (브로커)
- Kafka 클러스터의 각 서버를 브로커라고 한다.
- 메시지를 저장하고, Producer와 Consumer 간 데이터 전송을 담당한다.
4. Topic (토픽)
- 메시지가 분류되어 저장되는 단위
- 각 토픽은 하나 이상의 파티션(Partition)으로 구성된다.
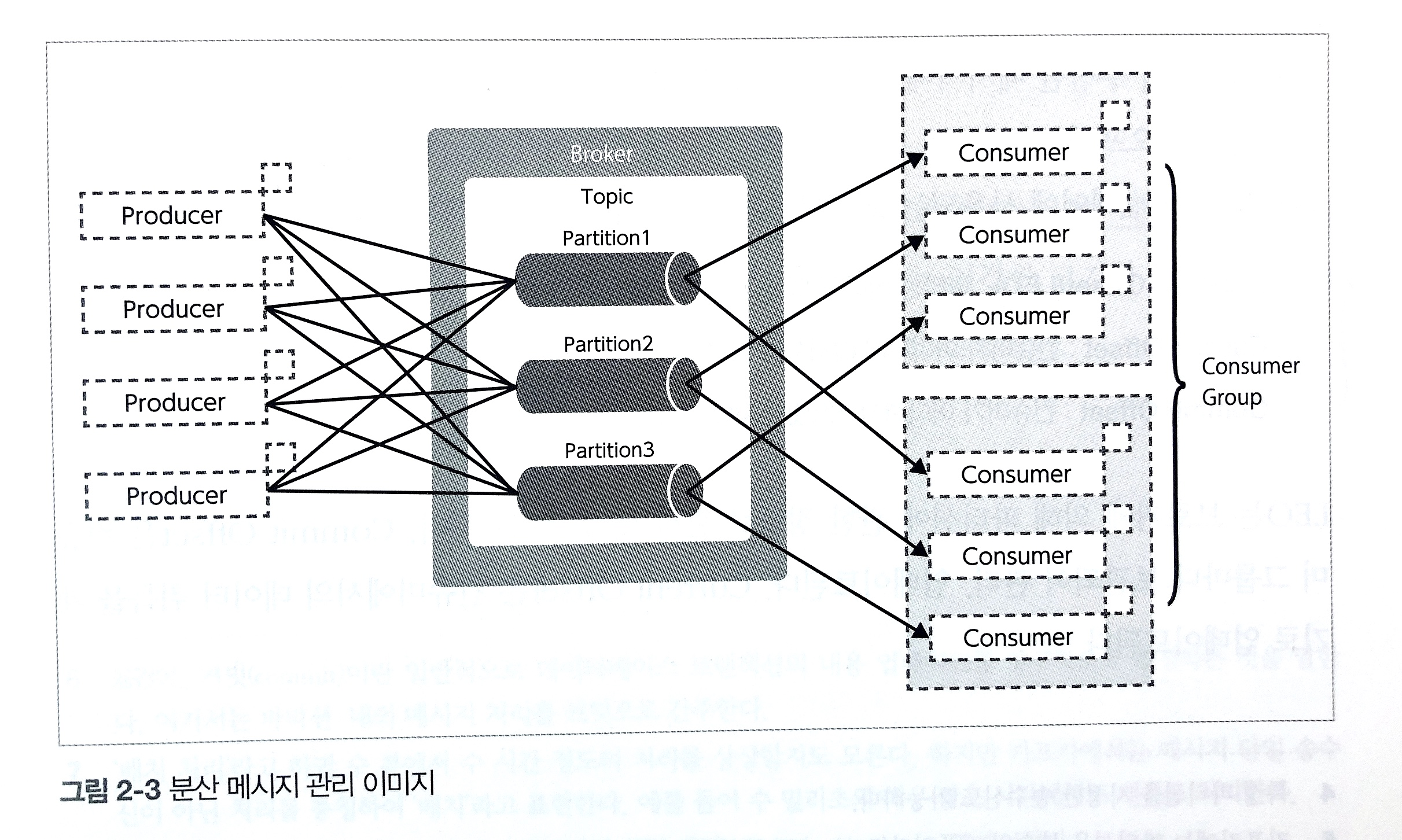
5. Partition (파티션)
- 각 토픽은 여러 파티션으로 나뉘며, 데이터는 파티션 단위로 저장된다.
- 파티션을 통해 데이터 병렬 처리가 가능하며, 확장성을 높인다.
- 적정 파티션 수
- 구성 및 요구 사항에 따라 다르기 때문에 시스템을 설계할 때 고려
- 메시지 처리 속도, 컨슈머 그룹 내 컨슈머 개수, 컨슈머 내 스레드 수 등을 동시에 고려해야 함
- 파티션 수는 증가할 수는 있지만 한 번 증가한 파티션 수는 다시 줄일 수 없음
- 구성 및 요구 사항에 따라 다르기 때문에 시스템을 설계할 때 고려
6. Zookeeper (or Kafka Raft)
- Kafka의 메타데이터를 관리하고, 클러스터를 조정하는 역할을 한다.
- 최근 버전에서는 Kafka Raft Consensus Algorithm(KRaft)으로 Zookeeper 의존성을 제거
4. Kafka의 작동 원리
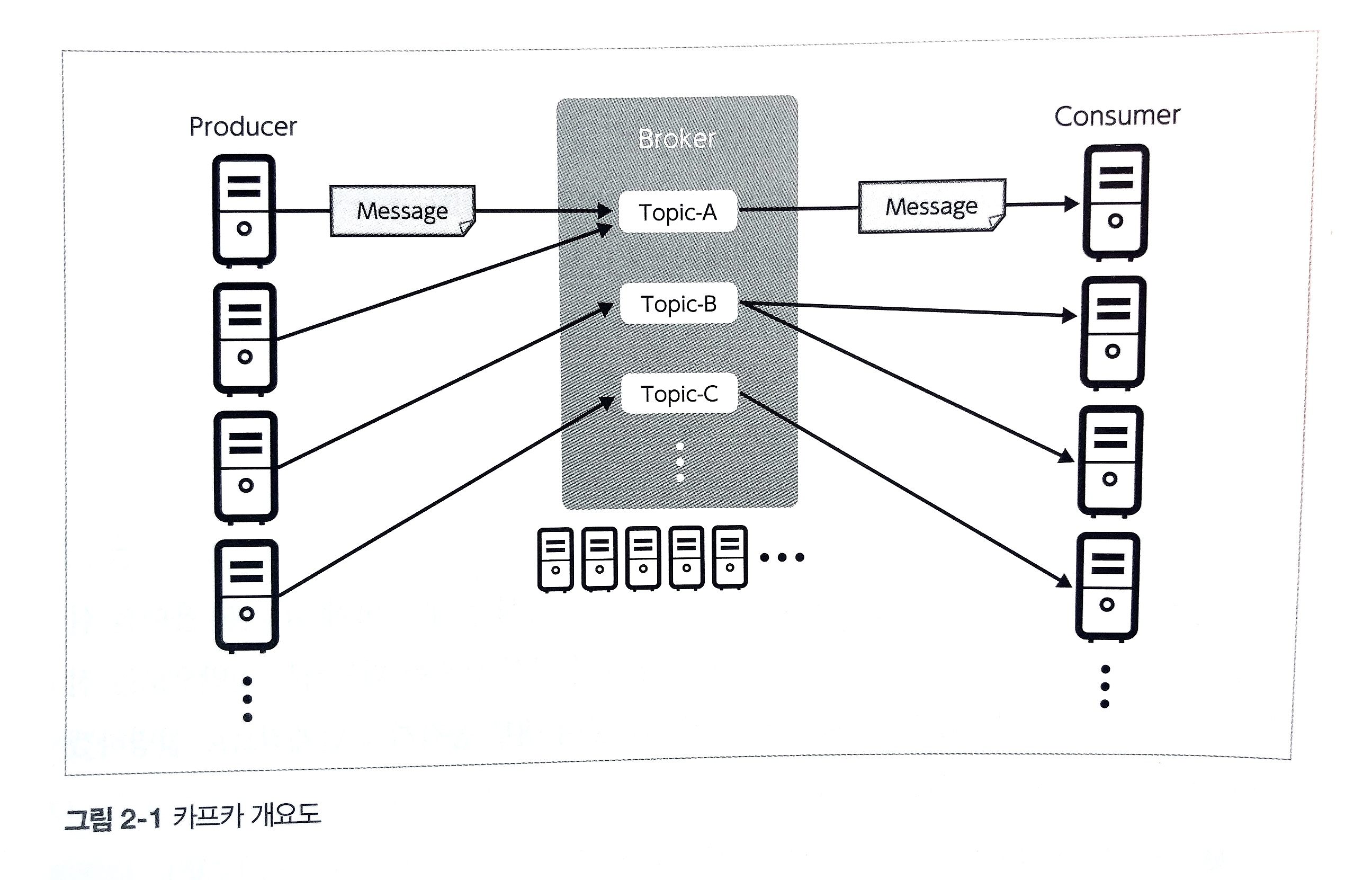
1. Producer가 데이터를 Topic으로 전송
- Producer는 데이터를 Topic의 특정 Partition으로 전송한다.
- 메시지는 Key를 기준으로 특정 파티션에 할당되거나, 라운드 로빈 방식으로 배분된다.
2. Partition에 메시지가 저장
- 메시지는 파티션의 로그 파일에 추가되며, 메시지는 순차적으로 번호(오프셋)를 부여받는다.
3. Consumer가 데이터를 읽음
- Consumer는 Topic을 구독하고, 각 파티션의 데이터를 읽는다.
- Consumer Group을 사용하면 각 파티션이 하나의 Consumer에만 할당되어 병렬 처리가 가능하다.
5. Kafka의 주요 개념
1. Replication (복제)
- 각 파티션은 여러 브로커에 복제되어 장애 발생 시 데이터를 복구할 수 있다.
- 리더(Leader): 파티션의 주 복제본, 모든 읽기/쓰기 작업을 처리
- 팔로워(Follower): 리더를 복제하여 데이터 백업
2. Offset (오프셋)
- 파티션 내에서 메시지의 고유 번호
- Consumer는 오프셋을 기반으로 메시지를 읽으며, 커밋된 오프셋을 통해 읽기 위치를 기록한다.
- Offset Commit
- 컨슈머는 어느 메시지까지 처리를 완료했는지 카프카 클러스터에 기록할 수 있다. 정확하게는 다음 수신 및 처리해야 할 메시지의 오프셋 기록 이다.
- 오프셋 커밋의 기록은 컨슈머 그룹 단위로 이루어진다.
- 수기로 메시지 커밋할 경우 중간에 메시지가 처리되지 않을 경우 무한 루프가 돌 수 있음
- Auto Offset Commit
- 자동 오프셋 커밋은 일정 간격마다 자동으로 오프셋을 커밋
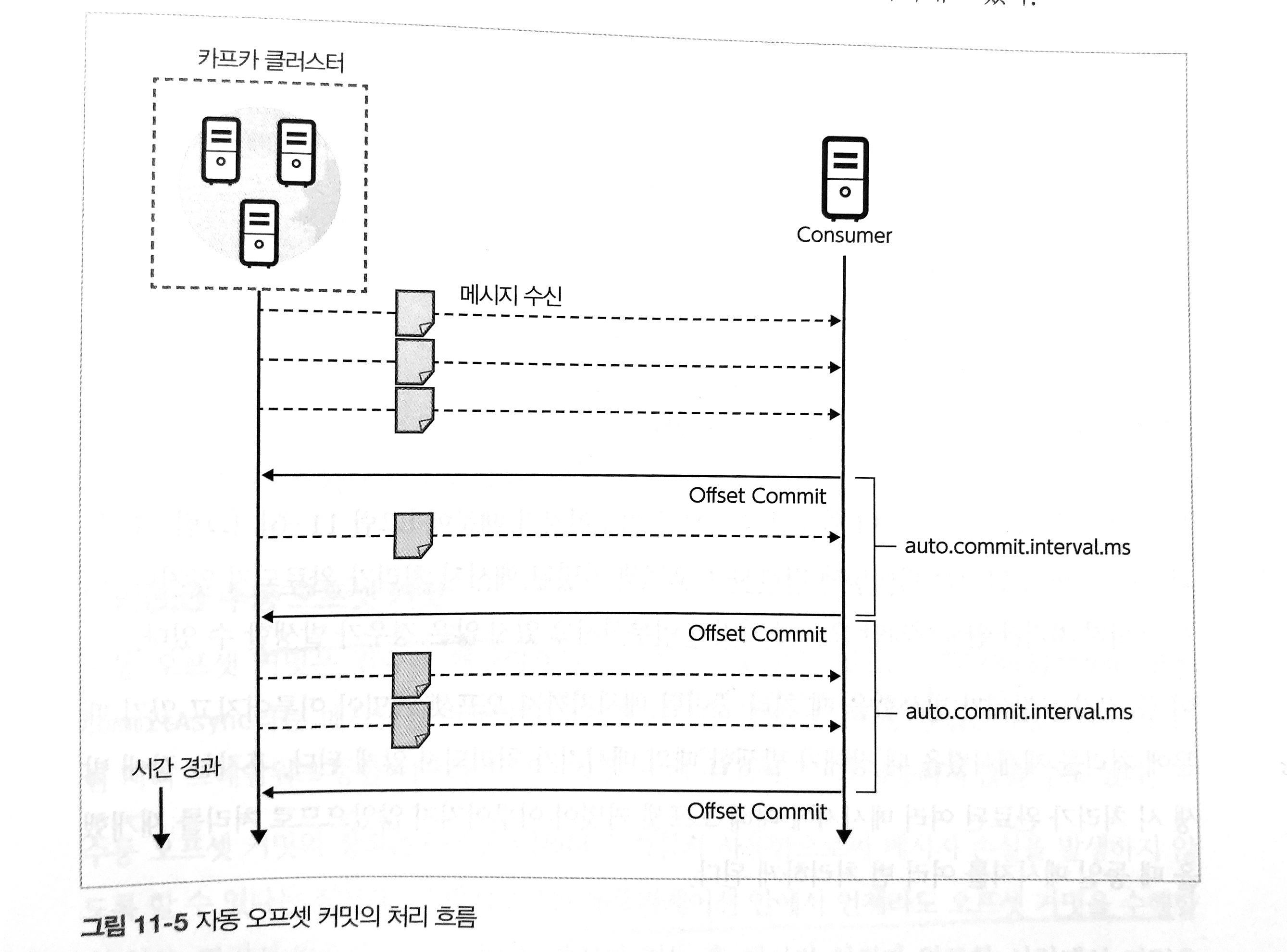
- 장점: 컨슈머는 오프셋 커밋을 명시적으로 실시할 필요가 없음
- 단점: 컨슈머 장애가 발생했을 때 메시지가 손실되거나 메시지 중복이 발생할 수 있음
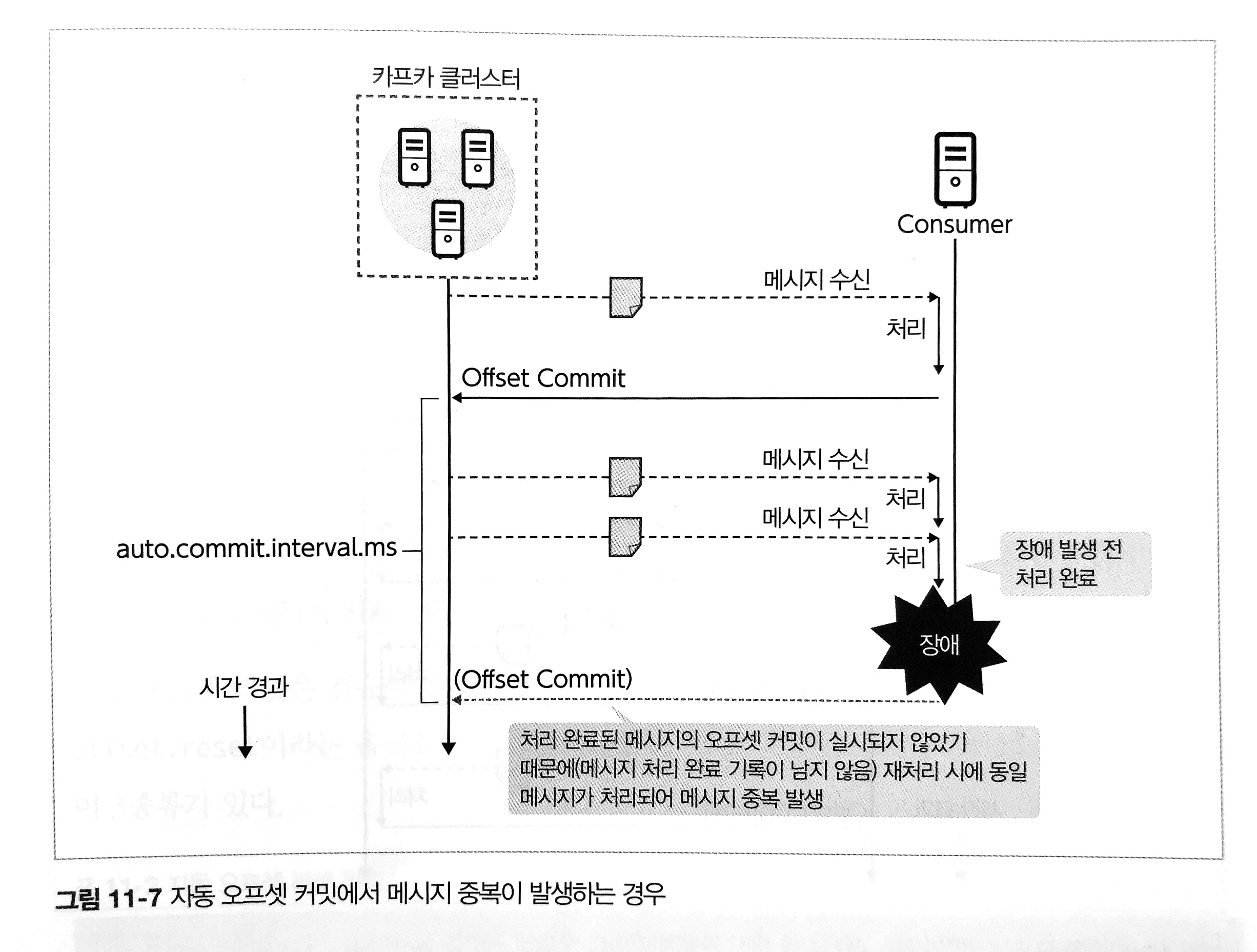
- 자동 오프셋 커밋은 일정 간격마다 자동으로 오프셋을 커밋
- Manual Offset Commit
- 애플리케이션 안에서 언제라도 오프셋 커밋 수행 가능
- 카프카 클러스터에서 메시지 취득 후 메시지 처리가 완료한 시점에서 커밋
- 장점
- 해당 메시지 처리는 반드시 완료되어 있기 때문에 메시지 손실이 발생하지 않음
- 컨슈머 장애 발생 시 메시지 중복을 최소화할 수 있음
- 단점
- 메시지 양에 따라 다르지만, 수동 오프셋 커밋이 자주 커밋 처리를 하므로 카프카 클러스터 부하가 높아진다는 점에는 주의 필요
3. Retention (보관 기간)
- 메시지는 Kafka에 일정 기간 동안 보관되며, 기본적으로 디스크에서 삭제되지 않는다.
- 보관 기간은 설정 가능하며, 데이터가 오래된 경우 디스크 공간을 확보하기 위해 삭제된다.
4. Consumer Group
- 동일한 Group ID를 가진 Consumer들은 협력하여 데이터를 처리한다.
- 하나의 Consumer Group 내에서는 파티션이 고유하게 할당되므로 병렬 처리가 가능하다.
- 컨슈머 그룹에서 기대한 대로 분산하여 메시지를 수신하기 위해서는 파티션 수는 적어도 각 컨슈머 그룹에 속하는 컨슈머보다 많아야 함
- 토픽의 파티션보다 컨슈머가 많을 경우 파티션이 할당되지 않는 컨슈머가 발생할 수 있음
6. Kafka의 주요 활용 사례
1. 실시간 데이터 스트리밍
- 로그 수집 및 처리 (ELK Stack과 함께 사용)
- 실시간 데이터 분석 (예: 사용자 행동 분석)
2. 이벤트 기반 시스템
- 마이크로서비스 간 메시지 전달
- 비동기 이벤트 처리
3. 데이터 통합 및 파이프라인
- 다양한 데이터 소스를 통합하여 데이터 웨어하우스나 데이터 레이크로 전달
4. 분산 로그 저장소
- 이벤트 및 로그의 저장 및 복구
7. Kafka의 장단점
장점
1. 높은 처리량과 확장성
Kafka는 분산 시스템으로 설계되어 클러스터 내 여러 브로커가 데이터를 병렬로 처리한다.
- 파티셔닝: 토픽이 여러 파티션으로 나뉘어 각 파티션이 독립적으로 처리된다. 파티션을 늘림으로써 처리량을 확장할 수 있다.
- 프로듀서와 컨슈머 병렬 처리: 여러 프로듀서와 컨슈머가 동시에 작업할 수 있어 처리 속도가 향상된다.
- 고성능 처리: 내부적으로 디스크 I/O 최적화를 통해 초당 수백만 개의 메시지를 처리할 수 있다.
2. 내구성을 보장하는 데이터 저장
Kafka는 데이터를 디스크에 저장하며, 리플리케이션(Replication) 메커니즘을 통해 데이터를 복제한다.
- 각 파티션은 여러 브로커에 복제본을 유지하며, 하나의 브로커에 장애가 발생해도 다른 복제본으로 데이터 손실 없이 복구할 수 있다.
- 기본 보관: 메시지는 디스크에 설정된 기간 동안 유지되며, 이를 통해 컨슈머가 데이터를 재처리하거나 복구할 수 있다.
3. 실시간 데이터 처리 가능
Kafka는 스트리밍 데이터 처리에 최적화되어 있으며, 빠르게 데이터를 전송하고 소비할 수 있다,
- Producer-Consumer 모델: 프로듀서가 데이터를 토픽에 게시하면, 컨슈머는 이를 실시간으로 소비한다.
- 지연 최소화: 데이터는 디스크에 기록되자마자 바로 읽을 수 있어, 실시간 분석 및 처리가 가능하다.
4. 다양한 클라이언트 라이브러리 지원
Kafka는 여러 프로그래밍 언어(Java, Python, C#, Go 등)를 지원하는 클라이언트 라이브러리를 제공한다.
- 개발자가 선호하는 언어로 Kafka를 쉽게 통합할 수 있으며, 마이크로서비스 아키텍처에서 강력한 유연성을 제공한다.
- 다양한 오픈소스 커뮤니티에서 지속적으로 새로운 언어와 기능을 추가하고 있어 활용성이 높다.
단점
1. 운영 및 설정이 복잡함
Kafka는 강력한 기능을 제공하지만, 이를 설정하고 운영하기 위해서는 높은 수준의 기술적 이해와 노력이 필요하다.
- 클러스터 설정: 브로커 수, 파티션 개수, 복제본 구성 등 초기 설정이 복잡하며, 잘못 설정하면 성능 저하 또는 데이터 손실 위험이 있다.
- 장애 복구 관리: 브로커 장애 시 리더 선출이나 데이터 재분배가 발생하며, 이를 제대로 관리하지 않으면 클러스터가 불안정해질 수 있다.
- 모니터링 필요: Kafka의 성능을 유지하려면 클러스터 상태와 메시지 처리량 등을 지속적으로 모니터링하고 조정해야 한다.
2. 데이터 지연 시간이 메시지 큐보다 상대적으로 길 수 있음
Kafka는 데이터를 디스크에 저장한 후 읽기 때문에, 전통적인 메시지 큐(RabbitMQ, ActiveMQ 등)보다 약간의 지연 시간이 발생할 수 있다.
- 지연 발생 원인: 디스크 쓰기 및 읽기, 리플리케이션 동기화 등이 추가적인 지연을 유발할 수 있다.
- 단점 완화 방법: 적절한 설정(예: 배치 크기, 압축 설정)과 튜닝을 통해 지연을 최소화할 수 있다.
3. 트랜잭션 지원은 일부 제한적
Kafka는 트랜잭션을 지원하지만, 기존 데이터베이스나 일부 메시지 큐의 강력한 트랜잭션 기능과 비교하면 제한적이다.
- 트랜잭션 동작: Kafka는 Exactly Once Semantices(EOS)를 제공하여 프로듀서와 컨슈머 간 메시지 전송의 정확성을 보장하지만, 복잡한 다중 토픽/파티션 간 트랜잭션은 어려울 수 있다.
- 복잡성 증가: 트랜잭션을 사용하는 경우 성능 저하 및 설정 복잡도가 증가할 수 있다.
- 사용 사례 제한: 고도로 복잡한 트랜잭션이 필요한 애플리케이션에서는 적합하지 않을 수 있다.
