.png)
시험기간이 다가왔습니다..
이번에는 아무래도 벼락치기를 해야할 것 같아요..
캡스톤 디자인을 하다보니 학교 수업에 시간 할애를 거의 하지 못했습니다. 허허..
중간고사 이후로 자료구조론 책을 처음 펴보았는데, 그나마 다행인건 이번 달에 코딩테스트에 입문하면서 여러가지 자료구조에 대한 공부를 했던 것들이 시험범위에 들어가더군요. (DFS/BFS,heapq 등등)
오늘은 C로 연결리스트를 만들어보는 포스팅을 진행하도록 하겠습니다.
연결리스트 (LinkedList)
연결리스트는 동적으로 크기가 변할 수 있고, 삭제나 삽입 시에 데이터를 이동시킬 필요가 없는 오브젝트입니다. 저는 체인이라고 생각하고 이해를 했습니다.
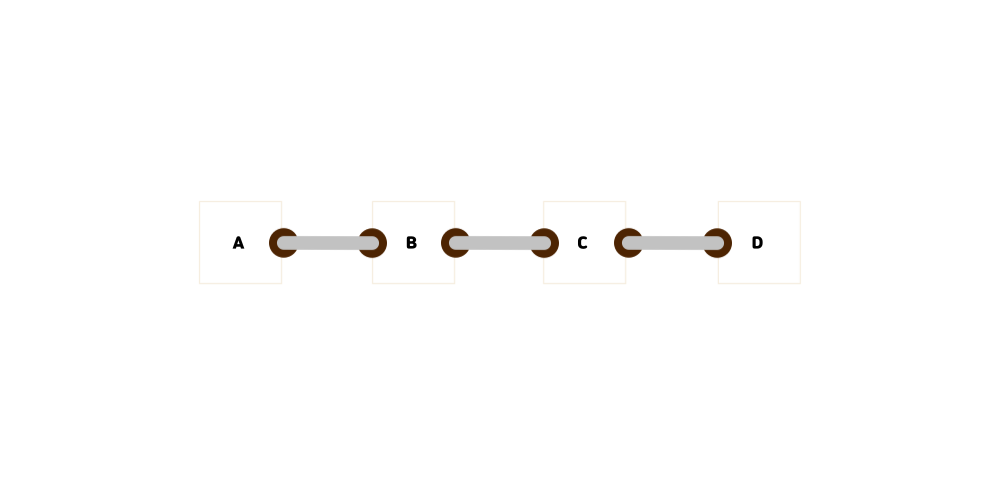
이제부터 한 덩어리를 노드라는 용어로 표현토록 하겠습니다.
위 그림에는 A,B,C,D라는 데이터를 가진 4개의 노드가 연결리스트로 구현되어있습니다.
만약 이 안에 B와 C 사이에 노드를 추가한다고 가정했을 때, 두 노드간의 체인을 잠시 끊고, 새로 들어가는 노드에 B로부터 나온 체인을 걸고, 새로 들어온 노드와 C를 새로운 체인으로 연결해주면 됩니다.
마찬가지로 C라는 데이터를 삭제할 때에는 C와 C에서 나온 체인을 삭제한 뒤에 B의 체인을 D에 연결해주면 되겠죠?
그렇다면 하나의 노드에 필요한 것은 어떠한 것이 있을까요? 일단은 위 그림의 예를 들면 A,B,C,D 이러한 Data가 필요하겠죠?
그 다음에는 자신의 다음 노드를 가리킬 체인이 필요합니다. 통상적으로 그러한 체인을 link라고 부릅니다.
다음 노드를 가리킨다? 이것은 어떠한 것을 의미할까요? 바로 주소를 의미합니다. link는 포인터 변수를 사용해야 하는 것이죠.
이제 이러한 정보를 토대로 한번 연결리스트의 구성요소인 ListNode를 정의해보도록 할까요?
선언 및 연결
ListNode 정의
typedef char element;
typedef struct ListNode {
element data;
struct ListNode *link;
} ListNode;
이런식으로 구현할 수가 있습니다. 이는 노드의 구조를 선언한 것이고 아직 노드가 생성된 것이 아니라는 것을 주의하셔야 합니다.
공백 ListNode 생성
단순 연결리스트는 헤드 포인터만 있으면 모든 노드를 찾을 수 있습니다.
다음과 같이 포인터 head를 정의해주도록 하겠습니다.
ListNode *head=NULL;이렇게 헤드 포인터를 선언해주면 헤드 포인터가 NULL 인 단순 연결리스트 하나가 만들어졌다고 볼 수 있습니다.
이번에는 노드를 생성해볼까요?
head ListNode에 데이터 할당
head=(ListNode *)malloc(sizeof(ListNode));
head->data="A";
head->link=NULL;
동적 메모리 할당이므로 malloc()을 사용해주면 됩니다. 그 이후에는 head라는 ListNode의 데이터를 지정해주고 그 뒤에 연결할 노드는 존재하지 않으므로 link는 NULL로 설정해줍니다. 현재 상태는 다음과 같습니다.
.png)
이번에는 노드를 연결하는 작업을 진행해보도록 하겠습니다.
p라는 ListNode를 생성해서 'B'라는 데이터를 할당해주도록 해볼까요?
ListNode *p;
p=(ListNode *)malloc(sizeof(ListNode));
p->data="B";
p->link=NULL;이제 조금 감이 오시나요?
기존에 만들어놓았던 head ListNode와 지금 만든 p ListNode를 연결해주도록 해보겠습니다.
ListNode들 간의 연결
head->link=p;생각보다 너무 간단하죠? 이렇게 해줌으로 현재 상태는 다음 그림과 같아집니다.
.png)
연결리스트 함수
구현할 연결리스트의 함수들은 다음과 같습니다.
- insert_first() : 리스트의 시작 부분에 항목을 삽입하는 함수
- insert() : 리스트의 중간 부분에 항목을 삽입하는 함수
- delete_first() : 리스트의 첫번째 항목을 삭제하는 함수
- delete() : 리스트의 중간 부분에서 항목을 삭제하는 함수
- print_list() : 리스트를 방문하여 모든 항목을 출력하는 함수
insert_first()
insert_first()부터 살펴보도록 하겠습니다.
기존에는 head라는 녀석이 첫번째 노드를 가리키고 있었죠? 새로운 노드를 하나 생성하고 새로운 노드의 link에 현재 head값을 저장한 후에 새로 만든 노드를 가리키도록 하면됩니다.
알고리즘은 다음과 같이 됩니다.
insert_first(head,value):
1, p->malloc()
2, p->data <- value // 새로 만든 node에 value 할당
3, p->link <-head // 새로 만든 node의 링크는 기존 head
4, head <- p //맨 앞 요소이므로 head로 변경
5, return head
이를 코드로 표현해보면 다음과 같습니다.
ListNode * insert_first(ListNode *head, element value){
ListNode *p=(ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->link=head;
head=p;
return head;
}차근차근 생각해보면 이해하기 쉽습니다 :)
insert()
위 insert_first()를 이해하셨다면 insert() 또한 쉽게 이해할 수 있습니다. 매개변수로는 들어가고자 하는 자리의 그 이전 노드가 필요해요.
제가 위에서 "새로 들어가는 노드에 B로부터 나온 체인을 걸고, 새로 들어온 노드와 C를 새로운 체인으로 연결해주면 됩니다." 라고 했었죠?
알고리즘은 다음과 같습니다.
insert(head,pre,value):
1, p->malloc()
2, p->data <- value
3, p->link <- pre->link // 이전 노드가 연결하고 있었던 링크는 이제 새로운 p의 링크로 변경
4, pre->link <- p // 이전 노드는 이제 p를 링크
5, return head // 반환은 늘 head!
코드로 구현하면 다음과 같습니다.
ListNode * insert(ListNode *head, ListNode *pre ,element value){
ListNode *p=(ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->link=pre->link;
pre->link=p;
return head;
}delete_first()
데이터를 삽입하는 함수에 대해서 알아보았으니 이번에는 삭제 함수를 알아봐야겠죠? delete_first()를 구현해보도록 하겠습니다.
삽입과는 조금 달라요. 이번에는 free()라는 메모리 반환 메소드를 적극 활용해야 합니다. delete_first()이므로 head로 지정되어 있는 노드를 삭제해야겠죠? head는 없어져서는 안되는 요소이므로 removed라는 ListNode를 하나 생성해준 후 기존 head에 있던 값을 removed 노드로 이동시킨 후에 head 값을 다음 노드의 링크로 변경해준 뒤 removed를 반환해주면 됩니다.
알고리즘은 다음과 같습니다.
delete_first(head):
1, removed <- head
2, head <- head->link
3, free(removed) // removed 반환
4, return head // 반환은 늘 head!
이를 바탕으로 코드를 한번 구현해볼까요?
ListNode * delete_first(head){
ListNode *removed;
if(head==NULL) return NULL; => 이미 head 요소가 없는 경우
head=removed->link;
free(removed);
return head;
}delete()
delete() 또한 delete_first()와 똑같은 메커니즘으로 동작합니다.
다만 중간에서 처리를 해준다는 점에서 유사한 insert()와 같이 기존 pre라는 매개변수가 필요해요.
알고리즘은 다음과 같이 나타낼 수 있습니다.
delete(head,pre):
1, removed <- pre->link
2, pre->link <- removed->link
3, free(removed)
4, return head
이제 쉽게 이해하실 수 있죠?
바로 코드를 작성하겠습니다.
ListNode * delete_first(head){
ListNode *removed;
removed=pre->link;
pre->link=removed->link;
free(removed);
return head;
}print()
연결리스트는 print() 도 굉장히 특이하게 생겨먹었는데요. 한번 이해하시면 쉽게 느껴질겁니다.
우선 for 반복문을 사용하여 노드들에 방문을 하며 printf를 처리해주어야 하는데요.
언제까지 for문이 반복되어야 할까요? head에서부터 시작하여 NULL값을 만나기 전까지 반복해야합니다. 또한 p=p->link라는 연산을 반복해주며 진행해나가야 하죠. 바로 소스코드를 작성해보도록 하겠습니다.
for(ListNode *p=head; p!=NULL;p=p->link)
printf("%d->",p->data);
printf("NULL \n"); 재미있지 않나요??🤗
LinkedList 코드
위에서 설명드렸던 함수를 토대로 연결리스트를 구현해보도록 하겠습니다.
#include <stdio.h>
#include <stdlib.h>
typedef int element;
typedef struct ListNode{
element data;
struct ListNode *link;
} ListNode;
void error(char *message){
fprintf(stderr,"%s\n",message);
exit(1);
}
ListNode* insert_first(ListNode *head,element value){
ListNode *p=(ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->link=head;
head=p;
return head;
}
ListNode* insert(ListNode *head,ListNode* pre, element value){
ListNode *p=(ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->link=pre->link;
pre->link=p;
return head;
}
ListNode* delete_first(ListNode *head){
ListNode *removed;
if(head==NULL) return NULL;
removed=head;
head=removed->link;
free(removed);
return head;
}
ListNode* delete(ListNode *head,ListNode *pre){
ListNode *removed;
removed=pre->link;
pre->link=removed->link;
free(removed);
return head;
}
void print_list(ListNode *head){
for (ListNode *p=head;p!=NULL;p=p->link){
printf("%d->",p->data);
}
printf("NULL\n");
}
int main() {
ListNode *head=NULL;
for(int i=0;i<5;i++){
head=insert_first(head,i);
print_list(head);
}
for(int i=0;i<5;i++){
head=delete_first(head);
print_list(head);
}
return 0;
}실행 결과는 다음과 같습니다.
0->NULL
1->0->NULL
2->1->0->NULL
3->2->1->0->NULL
4->3->2->1->0->NULL
3->2->1->0->NULL
2->1->0->NULL
1->0->NULL
0->NULL
NULL
.png)
.png)
🤔 연결리스트를 왜 사용하나요??
포스팅을 하며 찾아보니 이 질문이 은근 개발자 면접에서 많이나온다고 하더군요. 연결리스트와 배열의 차이점에 연결지어서 정리를 하시면 크나큰 도움이 될 것이라 생각합니다.
배열과의 큰 차이점과 장/단점
연결리스트는 데이터를 논리적 순서에 따라 데이터를 입력합니다. 하지만 물리적 주소는 순차적이지 않죠.
인덱스를 가지고 있는 배열과는 달리 연결리스트는 인덱스 대신 현재 위치의 이전 및 다음 위치를 기억하고 있습니다. 때문에 한번에 데이터 접근이 가능하지 않고 연결되어 있는 링크를 따라가야만 접근이 가능하고, 배열에 비해 속도가 떨어진다는 단점이 존재합니다. 배열에 비해 구현 난이도가 높은 것도 단점이 될 수 있습니다.
하지만 데이터 삽입/삭제는 논리적 주소만 바꿔주면 되기 때문에 데이터 삽입/삭제는 용이하다는 확연한 장점도 존재하죠.
결론
데이터에 대한 접근이 빈번하게 일어나며 삽입/삭제를 할 상황이 많이 예견되지 않는다면 배열을 사용하는 것이 좋고,
데이터에 대한 접근에 비해 삽입/삭제가 빈번하게 일어난다면 연결리스트를 사용하는 것이 좋습니다!
마무리
처음 연결리스트를 접했을 때 저는 조금 자료구조 쪽에 대한 이해도가 떨어지는 것인가? 라는 생각이 들었어요.
그렇지만 한편으로는 포인터에 대한 개념이 잘 정립되어 있다면 오히려 스택,큐보다 더 쉽게 느껴질 수 있다고 생각합니다.
긴 포스팅 글 읽어주셔서 감사합니다:)

시험기간인데도 좋은 글 남겨주셔서 감사합니다~