리팩토링 📦
⭐️ 코드 가독성 및 최적화

기존 코드에서,
직원의 총합의 데이터를 받아올 때, firebase로 직원들의 데이터를 받아오고 그 직원들을 순회하면서
totalEmployees를 증가시켜줬었습니다.
test.length를 사용하지 않은 이유는 test가 firebase로 받아올때 배열로 받아오지않고
객체로 받아왔던 상황이라 length 메소드를 사용하지 못했습니다.
객체 안에를 열어보니 아래 사진과 같이 size라는 메소드가 있었습니다.
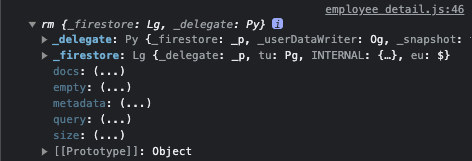
사용해보니 원하는 결과를 기존코드보다 가독성 좋고 성능도 좋은 것 같아서 아래와 같이 바꾸었습니다.
const data = await db.collection('profile').get();
let totalEmployees = data.size;⭐️ 코드 가독성 및 최적화
employee.classList.contains('hide') ? employee.classList.remove('hide') : undefined;기존의 코드에서 if문을 사용하지 않고 삼항연산자를 사용한 이유가 한줄로 표현하는 삼항연산자가
코드 가독성측면에서 좋을것같다고 판단해서 사용하였는데 else일때 아무 작업도 하지 않는다면 undefined이라는 값이 논리적으로 좋은 것 같지는 않아서
아래와 같이 더 논리적이고 가독성 좋은 코드로 교체하였습니다.
employee.classList.contains("hide") && employee.classList.remove("hide");해결하지 못한 문제 📦
⭐️ 비동기 실행방식
checkIds.forEach(checkId=>{
deleteFirestore('profile',checkId)
setTimeout(()=>window.location.href = "./index.html",500)
})기존의 코드에서 setTimeout을 사용하여 index 페이지로 새로고침할려고 했던 이유는,
setTimeout을 사용하지 않는다면 앞에 처리하는 로직들이 비동기함수로 실행되고 있는데
완료가 되지않고 index페이지로 넘어가고 로직들이 중단되는 현상이 있었습니다.
그래서 setTimeout으로 일정시간 이후 index 페이지로 넘어가게 했었는데,
만약 비동기적으로 실행되는 코드가 짧게걸리는 로직이 아닌, setTimeout으로 지정해준
시간보다 오래걸리는 작업이라면 불확실하고 위험한 코드 인 것 같아서 수정을 하기로 했습니다.
1차 시도 : 실패
checkIds.forEach(async (checkId)=>{
await deleteFirestore('profile',checkId)
})
window.location.href = "./index.html"문제점 : 검색 해보니 forEach 메서드에서 async await을 하면
콜백 함수 내에서 비동기 작업을 기다리지 않고 다음 요소로 넘어갈 수 있기 때문입니다.
이런 경우 검색해보니 map을 사용하여 promise.all을 사용하는 것 같아 2차 시도를 해봤습니다.
2차 시도 : 실패
try
{
await Promise.all(checkIds.map(deleteEmployeeData))
window.location.href = './index.html';
console.log('성공');
}
catch(error){
console.log(error);
}문제점 : promise.all로 비동기 작업을 완료 한 후에 시도를 해보아도 해결되지 않았습니다.
원인을 찾아보는중에 있고 비동기 부분에 대한 지식이 부족한 것 같아서 개념공부도 다시 진행하고있습니다.
추후 해결하거나 다른 방법으로 시도를 해본다면 게시글 업데이트 하겠습니다
리팩토링 하면서 궁금한 점 📦
⭐️ Network resource의 절약 vs 최신화,정확성
현재 데이터베이스를 클라우드 서비스를 사용하고 있는데,
클라우드 서비스의 데이터나 다른 유료 api를 사용한다면
사용자가 악의성을 가지고 데이터를 계속 받아온다면
개발자 입장에서는 지금은 무료라 괜찮겠지만
실제 서비스라고 생각하면 비용낭비라고 생각해서
이 부분을 막고자 어떻게 해결할지 생각하면서 검색을 구현했었는데
제가 선택한 방식은 매번 리소스를 받아오는게 아니라 받아온 리소스에서
검색한 키워드에 따라 보여줄지 안보여줄지를 결정했습니다.
의문이였던점은,
그래도 검색결과는 검색키워드에 따라서 데이터를 받아와
최신성과 정확성을 보장해주는 것이 맞는지,
악의적인 사용자의 데이터요청을 필터링하려면
필터링부분에서는 더 좋은 방법이 있는지 찾아보고
좀 더 좋은 방식으로 추후에 리팩토링을 통해 바꿔봐야겠다는 생각을 했습니다.
