
💡급하신 분들을 위해서 결론 먼저!
- 의존적 쿼리는 이전 쿼리의 결과에 따라 다음 쿼리를 실행하는 패턴으로,
enabled옵션을 활용해 구현한다. - 병렬 쿼리는 여러 데이터를 동시에 가져와 성능을 최적화하는 것이며,
useQuery를 나열하거나,useQueries로 구현한다. - 데이터 프리페칭은 사용자 행동을 예측해 미리 데이터를 로드하여 UX를 개선하는 기법이다.
- 각각의 기법은 서로 다른 요구사항에 따라서 다르게 사용할 수 있으며,
React Query와Suspense를 동시에 같이 쓸 때는 기존의 코드와 차이점을 유의해서 사용해야만 한다.
데이터 페칭부터 UX까지
현대 웹 애플리케이션에서 데이터 페칭은 단순한 API 호출 그 이상이다. 사용자가 버튼을 클릭하고 화면이 전환되는 그 짧은 순간, 수많은 데이터 요청과 응답이 오고 간다. 이 과정을 최적화하는 것은 마치 복잡한 교통 체계를 설계하는 것과 같다. 데이터가 지나가게끔 신호등은 언제 켜야 할까? 어떤 차량(포크레인, SUV, 킥보드) 이 먼저 지나가야 할까? 우리는 데이터라는 차량이 애플리케이션이라는 도로를 가장 효율적으로 달릴 수 있는 방법을 찾아야 한다. SUV, 포크레인, 킥보드 순으로 보내면 좋을 것이다.
👨🏻🏫 : (" 안녕하세요! 오늘은 데이터 페칭의 고급 패턴에 대해 함께 알아볼 거예요. 복잡한 요구사항에도 완벽히 수행을 하기 위해서는 데이터 페칭의 상황에 맞는 각각의 패턴을 적용하면 도움이 될 거예요!")
데이터 페칭 최적화는 단순히 속도를 높이기 위한 것 뿐만이 아니다. 아니? 되려 잘못 쓰게 된다면, 속도가 저하된다. 사용자 경험, 서버 부하, 네트워크 효율성, 그리고 애플리케이션의 반응성까지 모두 고려해야 한다. 이 글에서는 React Query에서 현대적인 데이터 페칭 라이브러리에서 공통적으로 활용할 수 있는 고급 패턴들을 살펴본다.
0. 단일 쿼리 작동 방식
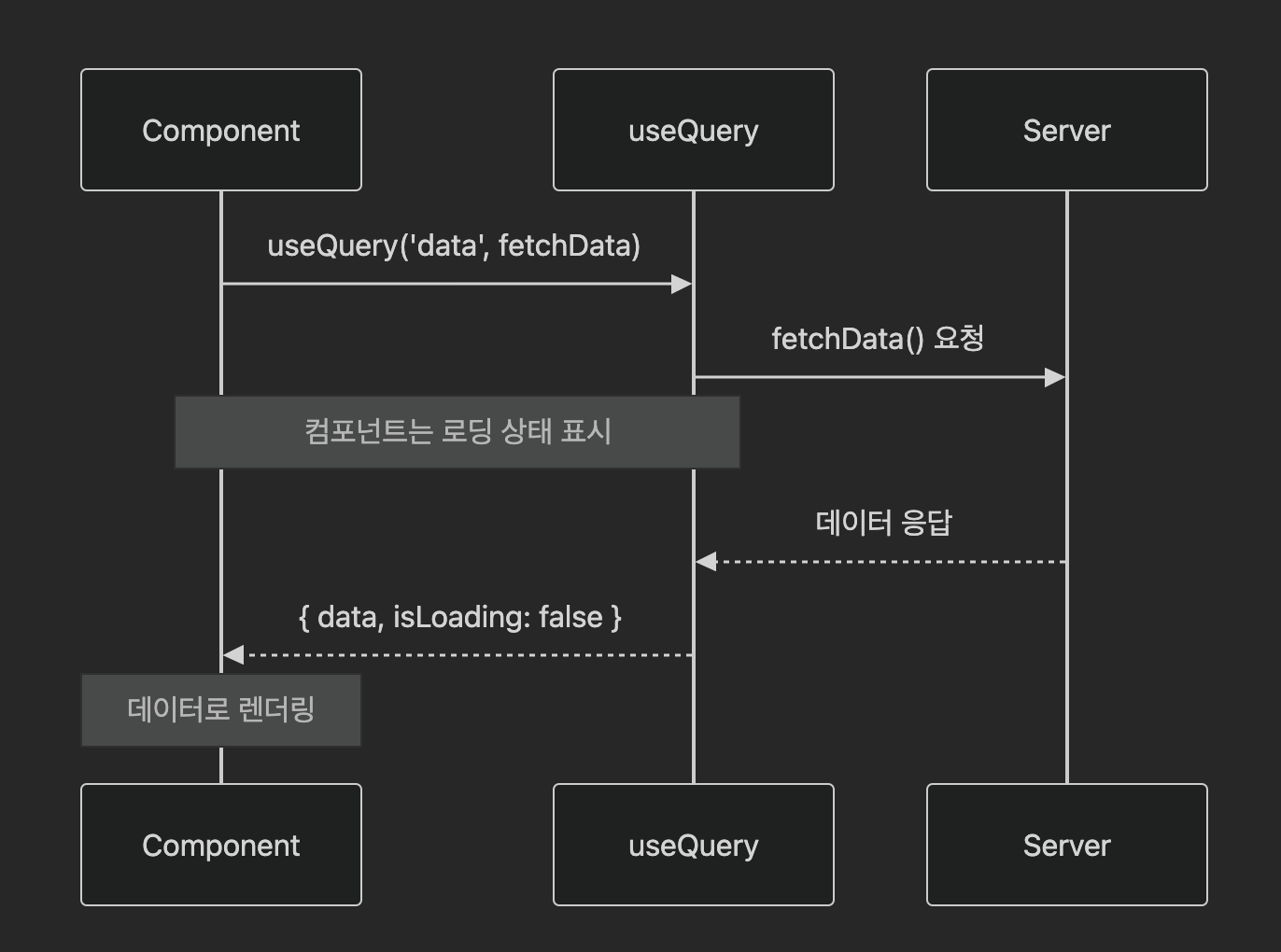
Suspense와 같이 사용할 때의 단일 쿼리 작동 방식
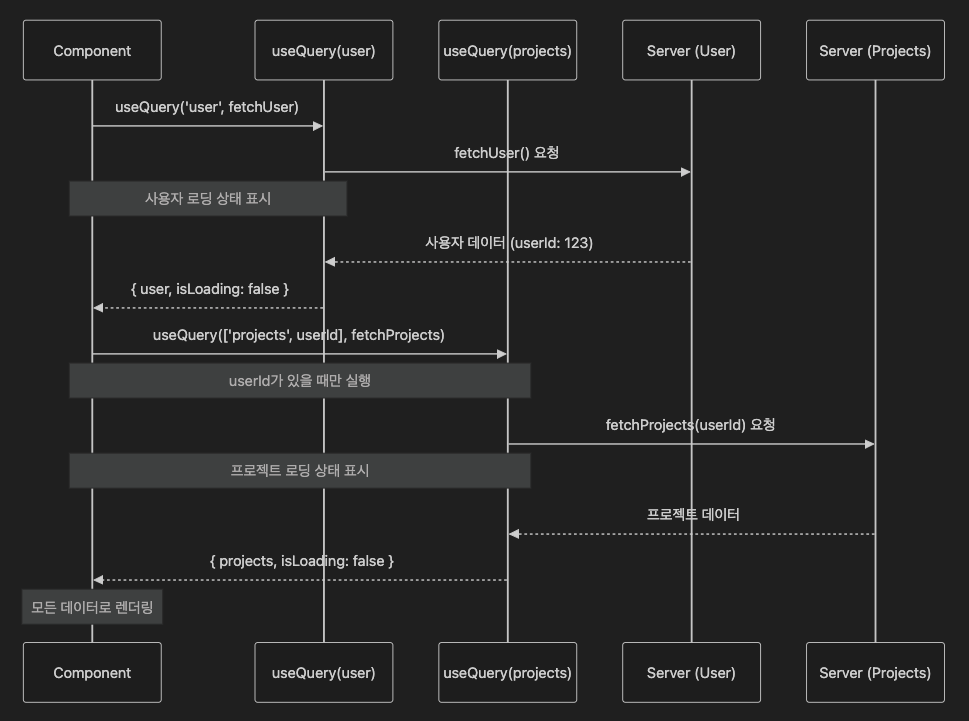
1. 의존적 쿼리(Dependent Queries) 구현하기
의존적 쿼리란?
의존적 쿼리는 이전 쿼리의 결과에 따라 다음 쿼리를 실행하는 패턴이다. 예를 들어, 사용자 정보를 먼저 가져온 후 해당 사용자의 주문 내역을 가져오는 경우가 있다. 이런 시나리오에서는 첫 번째 쿼리가 성공적으로 완료되고 필요한 데이터가 있을 때만 두 번째 쿼리를 실행해야 한다.
의존적 쿼리 작동 방식
React Query에서의 구현
React Query에서는 enabled 옵션을 사용하여 의존적 쿼리를 쉽게 구현할 수 있다.
*// 사용자 정보 가져오기*
const { data: user } = useQuery(['user', userId], fetchUser);
*// 사용자 정보가 있을 때만 주문 내역 가져오기*
const { data: orders } = useQuery(
['orders', user?.id],
() => fetchOrders(user.id),
{
*// user가 있고 user.id가 존재할 때만 쿼리 활성화*
enabled: !!user?.id,
}
);
*// 출처: https://tanstack.com/query/latest/docs/react/guides/dependent-queries*의존적 쿼리의 장점
- 불필요한 API 호출 방지: 선행 데이터가 없는 경우 후속 쿼리를 실행하지 않아 리소스를 절약한다.
- 데이터 일관성 유지: 의존 관계가 있는 데이터를 순차적으로 가져와 일관성을 보장한다.
- 에러 핸들링 간소화: 선행 쿼리에서 오류가 발생하면 후속 쿼리는 실행되지 않으므로 에러 처리가 단순해진다.
"(👨🏻🏫 : 의존적 쿼리는 마치 도미노와 같아요! 첫 번째 도미노가 쓰러져야 다음 도미노도 쓰러질 수 있죠. 이처럼 데이터 간의 관계를 명확히 하는 것이 중요합니다. 저라면 저
enabled안에 값을 넣을 때, 최대한 남들이 봤을 때 직관적인 변수로 이름을 적어서 쓸 거 같아요!!user?.id가 아니라isUserIdExist로 말이죠 )"
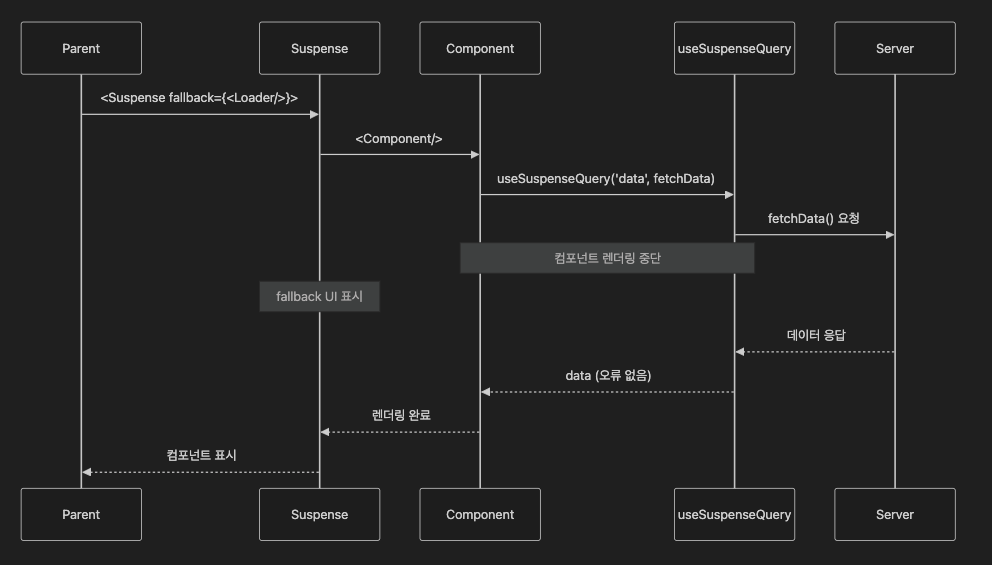
Suspense와 같이 사용할 때의 의존적 쿼리 작동 방식
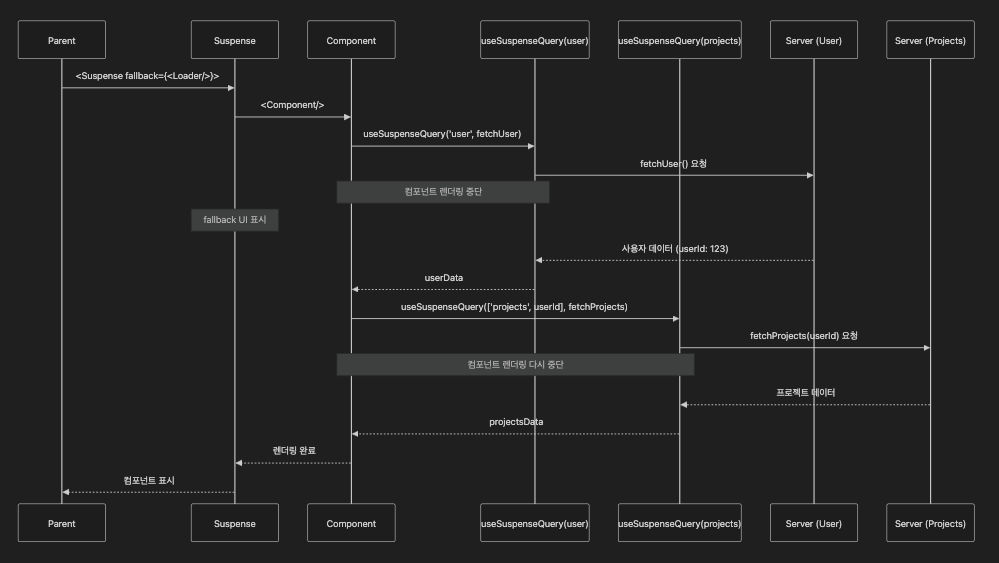
2. 병렬 쿼리(Parallel Queries)와 성능 최적화
병렬 쿼리의 개념
병렬 쿼리는 여러 데이터 요청을 동시에 실행하여 전체 로딩 시간을 단축하는 기법이다. 서로 독립적인 데이터를 가져올 때 특히 유용하다. 예를 들어, 대시보드 페이지에서 사용자 정보, 통계 데이터, 최근 활동 등을 동시에 가져와야 할 때 병렬 쿼리를 사용한다.
병렬 쿼리 작동 방식
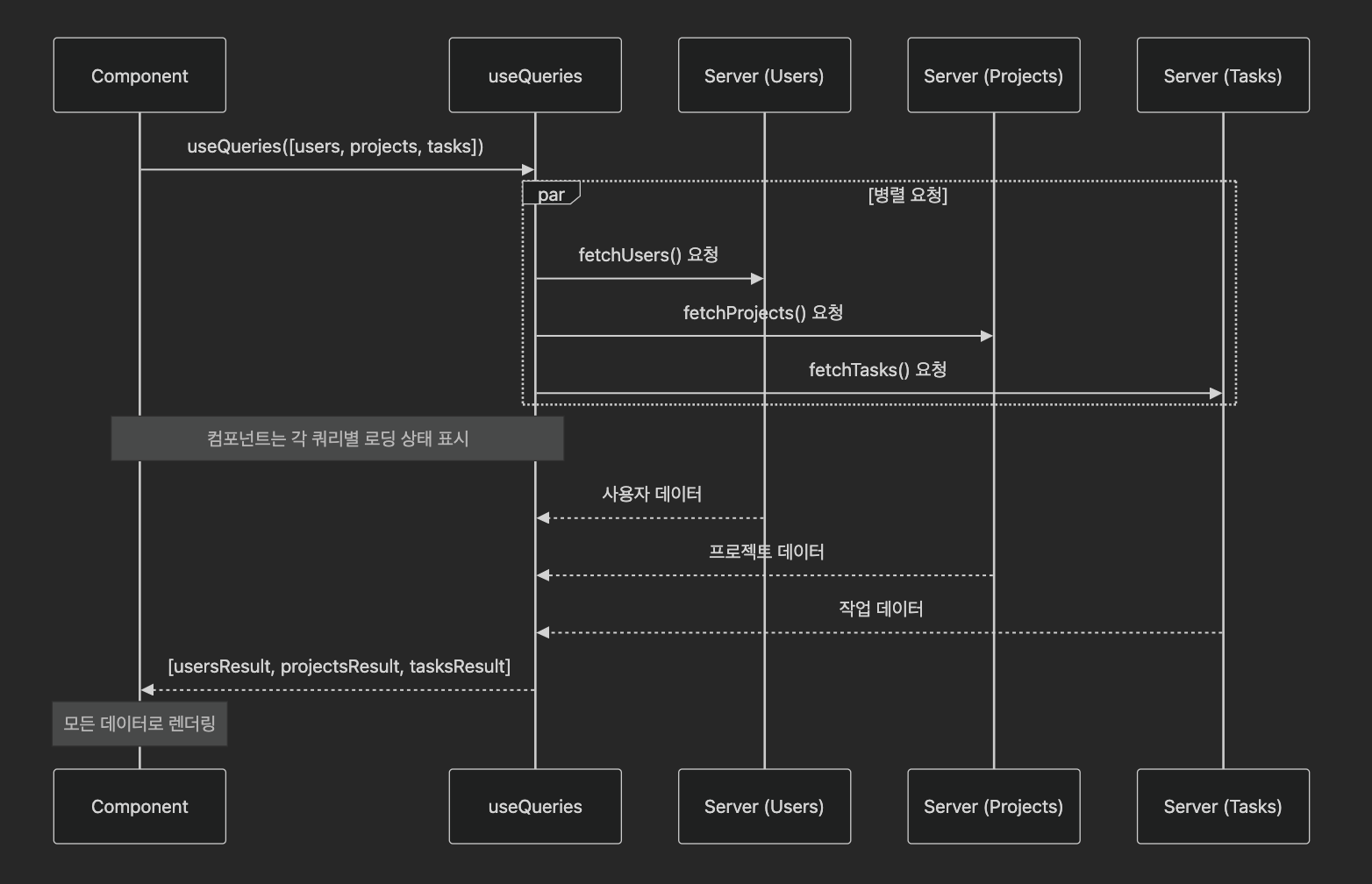
React Query에서의 구현
React Query에서는 여러 useQuery 훅을 사용하거나 useQueries 훅을 활용할 수 있다.
*// 방법 1: 여러 useQuery 훅 사용*
const usersQuery = useQuery('users', fetchUsers);
const projectsQuery = useQuery('projects', fetchProjects);
const tasksQuery = useQuery('tasks', fetchTasks);
*// 방법 2: useQueries 훅 사용*
const results = useQueries([
{ queryKey: ['users'], queryFn: fetchUsers },
{ queryKey: ['projects'], queryFn: fetchProjects },
{ queryKey: ['tasks'], queryFn: fetchTasks }
]);
*// 출처: https://tanstack.com/query/latest/docs/react/guides/parallel-queries*동적 병렬 쿼리 처리
때로는 동적으로 생성된 여러 쿼리를 병렬로 실행해야 할 수도 있다. 예를 들어, 여러 사용자 ID 목록이 있을 때 각 사용자의 정보를 동시에 가져오는 경우가 있다.
*// 동적으로 생성된 쿼리들을 병렬로 실행*
const userQueries = useQueries(
userIds.map(id => {
return {
queryKey: ['user', id],
queryFn: () => fetchUser(id),
}
})
);
*// 출처: https://tanstack.com/query/latest/docs/react/guides/parallel-queries*병렬 쿼리의 성능 최적화 팁
- 적절한 캐싱 전략 사용: 자주 변경되지 않는 데이터는 캐시 시간을 길게 설정한다.
- 쿼리 우선순위 설정: React Query의
priority옵션을 사용하여 중요한 쿼리에 우선순위를 부여한다. - 네트워크 워터폴 방지: 의존성이 없는 쿼리는 병렬로 실행하여 워터폴 효과를 방지한다.
- 데이터 프리페칭 활용: 사용자가 필요로 할 가능성이 높은 데이터는 미리 가져온다.
*// 쿼리 우선순위 설정 예시*
const usersQuery = useQuery('users', fetchUsers, { priority: 1 }); *// 높은 우선순위*
const logsQuery = useQuery('logs', fetchLogs, { priority: 0 }); *// 낮은 우선순위
// 출처: https://tanstack.com/query/latest/docs/react/guides/query-priorities*"(👨🏻🏫 : 병렬 쿼리는 마치 여러 명의 직원이 각자 다른 업무를 동시에 처리하는 것과 같아요! 효율적이지만, 너무 많은 요청을 동시에 보내면 서버에 부담이 될 수 있으니 적절한 균형이 필요합니다.)"
Suspense와 같이 사용할 때의 병렬 쿼리
TanStack Query v5에서 Suspense와 병렬 쿼리를 함께 사용할 때의 접근 방식을 분석하겠다.
Suspense와 TanStack Query의 병렬 처리 이슈
React Suspense와 TanStack Query를 함께 사용할 때 발생하는 중요한 고려사항이 있다:
useQuery는 기본적으로 병렬로 실행된다.- 하지만, React-Query와 Suspense를 같이 사용할 때에는
useSuspenseQuery를 사용해야 한다. - 여러 개의
useSuspenseQuery를 한 번에 사용할 때 문제가 발생한다. 각 쿼리가 순차적으로 처리되어 워터폴(waterfall) 효과가 발생할 수 있다. - 각 쿼리가 동기적으로 실행되어서, 병렬 처리를 해주지 않으면 각각의 쿼리들이 앞단의 쿼리들이 끝나기까지를 기다려야한다.
워터폴 현상 시각화
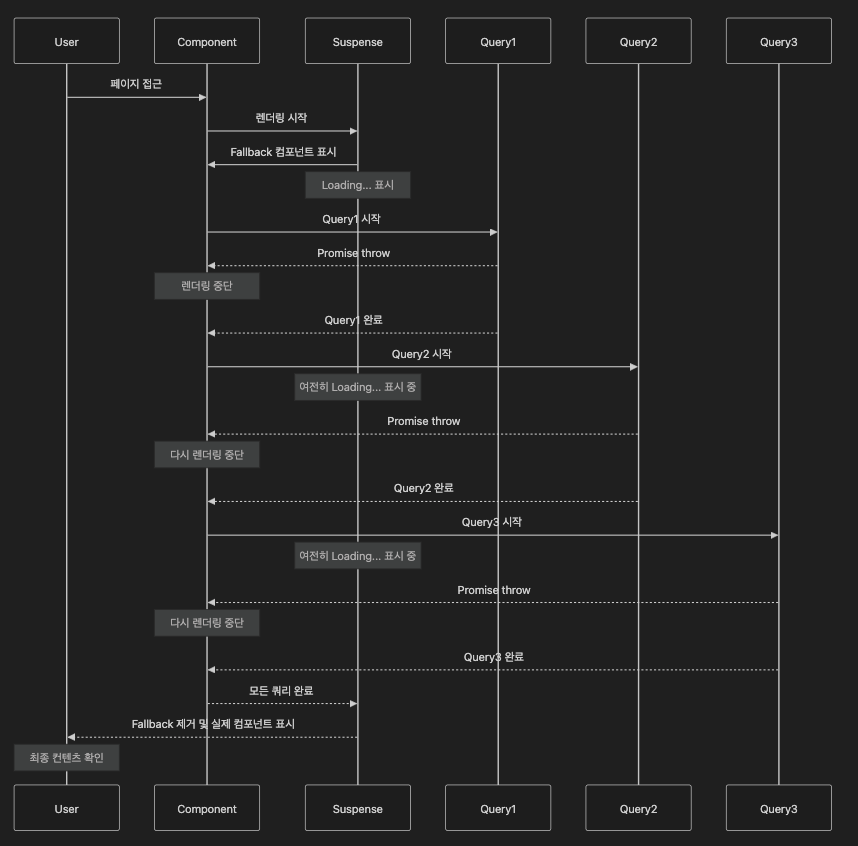
"(👨🏻🏫 : 병렬 처리가 아닌, 동기적 처리처럼 보이죠? Fallback UI 를 띄워둔 채, 하나가 끝날 때까지 다음 쿼리는 대기하고 있어야 하고, 그렇게 모든 쿼리들이 다 끝나고 나서야 랜더링이 되는 것은 병렬 처리라고 할 수 없겠죠? ㅎㅎ)"
해결책1: useSuspenseQueries
TanStack Query v5에서는 이 문제를 해결하기 위해 useSuspenseQueries를 제공한다. 이는 Suspense 환경에서 여러 쿼리를 병렬로 실행할 수 있게 해주는 훅이다.
import { useSuspenseQueries } from '@tanstack/react-query';
*// Suspense와 함께 병렬 쿼리 실행*
const results = useSuspenseQueries({
queries: [
{ queryKey: ['users'], queryFn: fetchUsers },
{ queryKey: ['projects'], queryFn: fetchProjects },
{ queryKey: ['tasks'], queryFn: fetchTasks }
]
});이 방식을 사용하면:
- 모든 쿼리가 병렬로 시작된다.
- 모든 쿼리가 완료될 때까지 컴포넌트는 일시 중단(suspend)된다.
- 워터폴 효과를 방지할 수 있다.
해결책2: 각각의 쿼리마다 Suspense 사용
또 다른 방법으로는 각 쿼리를 별도의 컴포넌트로 분리하고, 각 컴포넌트에 Suspense 경계를 설정하는 것이다:
function App() {
return (
<>
<Suspense fallback={<div>Loading users...</div>}>
<UserComponent />
</Suspense>
<Suspense fallback={<div>Loading projects...</div>}>
<ProjectComponent />
</Suspense>
<Suspense fallback={<div>Loading tasks...</div>}>
<TaskComponent />
</Suspense>
</>
);
}이 방식은 각 데이터 로딩이 독립적으로 처리되어 사용자 경험을 개선할 수 있다.
결론적으로, Suspense와 함께 병렬 쿼리를 사용하려면 useSuspenseQueries를 사용하는 것이 가장 적합한 방법이다.
3. 데이터 프리페칭 전략과 사용자 경험 개선
프리페칭의 개념과 중요성
데이터 프리페칭은 사용자가 실제로 데이터를 요청하기 전에 미리 데이터를 가져오는 기술이다. 이는 사용자의 행동 패턴을 예측하여 필요할 것으로 예상되는 데이터를 미리 로드함으로써 사용자 경험을 크게 향상시킨다. 예를 들어, 사용자가 목록에서 항목을 클릭할 가능성이 높을 때 해당 항목의 상세 정보를 미리 가져올 수 있다.
프리페칭 작동방식
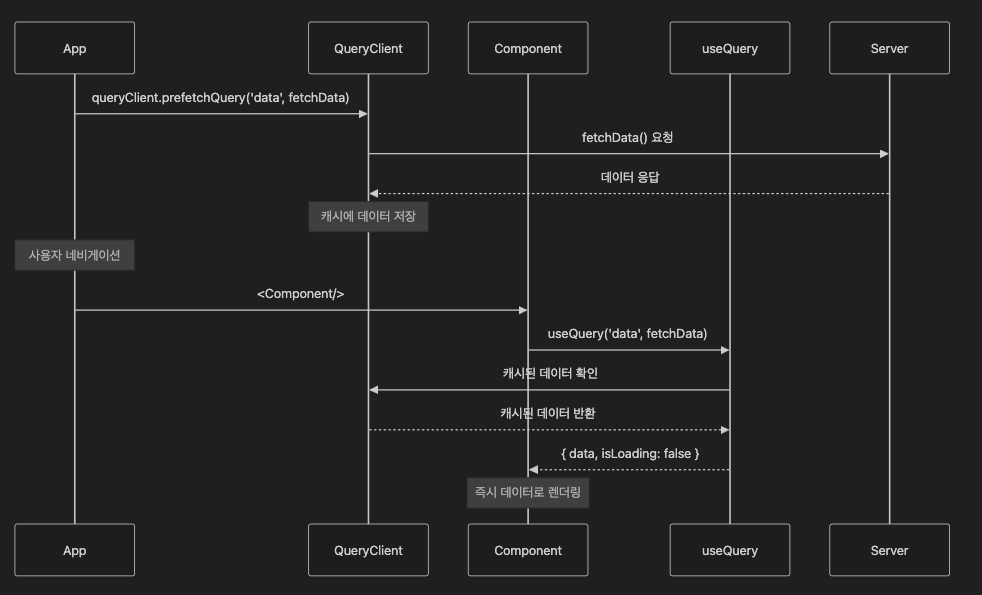
React Query에서의 프리페칭 구현
React Query에서는 queryClient.prefetchQuery 메서드를 사용하여 데이터를 미리 가져올 수 있다.
*// 사용자가 목록 항목에 마우스를 올렸을 때 상세 정보 미리 가져오기*
const queryClient = useQueryClient();
const handleMouseEnter = (itemId) => {
queryClient.prefetchQuery(
['item', itemId],
() => fetchItemDetails(itemId),
{ staleTime: 30000 } *// 30초 동안 데이터를 신선한 상태로 유지*
);
};
*// 출처: https://tanstack.com/query/latest/docs/react/guides/prefetching*프리페칭 전략
- 호버 기반 프리페칭: 사용자가 요소 위에 마우스를 올렸을 때 관련 데이터를 미리 가져온다.
- 페이지 전환 기반 프리페칭: 사용자가 링크나 버튼을 클릭하기 전에 다음 페이지에 필요한 데이터를 미리 로드한다.
- 스크롤 기반 프리페칭: 사용자가 목록의 끝에 가까워질 때 다음 페이지의 데이터를 미리 가져온다.
- 시간 기반 프리페칭: 특정 시간 간격으로 자주 사용되는 데이터를 주기적으로 갱신한다.
사용자 경험 개선을 위한 프리페칭 구현 예시
*// 페이지 전환 기반 프리페칭 예시*
import { Link } from 'react-router-dom';
import { useQueryClient } from 'react-query';
function ProductList({ products }) {
const queryClient = useQueryClient();
return (
<ul>
{products.map(product => (
<li
key={product.id}
onMouseEnter={() => {
*// 마우스를 올렸을 때 상세 정보 미리 가져오기*
queryClient.prefetchQuery(
['product', product.id],
() => fetchProductDetails(product.id)
);
}}
>
<Link to={`/product/${product.id}`}>
{product.name}
</Link>
</li>
))}
</ul>
);
}
*// 출처: https://tanstack.com/query/latest/docs/react/guides/prefetching*프리페칭 시 고려사항
- 리소스 사용량: 너무 많은 데이터를 미리 가져오면 네트워크 대역폭과 메모리 사용량이 증가할 수 있다.
- 캐시 관리: 프리페치된 데이터의 적절한 캐시 유효 기간을 설정하여 불필요한 메모리 사용을 방지한다.
- 사용자 행동 예측: 사용자의 실제 행동 패턴을 분석하여 프리페칭 전략을 최적화한다.
- 오프라인 지원: 프리페치된 데이터를 활용하여 오프라인 상태에서도 기본적인 기능을 제공할 수 있다.
"(👨🏻🏫 : 프리페칭은 마치 식당에서 손님이 주문하기 전에 인기 메뉴를 미리 준비해두는 것과 같아요! 손님이 오자마자 바로 음식을 제공할 수 있죠. 하지만 너무 많은 음식을 미리 준비하면 낭비가 될 수 있으니 적절한 예측및 최적화가 중요합니다.)"
앞으로의 웹 개발에서는 데이터와 UI의 경계가 더욱 모호해지고, 데이터 페칭이 더욱 선언적이고 자동화될 것이다. ‘선언적이다’ 라는 말은 점차 ‘무엇’을 할지에 초점을 두고, ‘어떻게’ 작동되는지에 대해서는 추상화가 되니 더더욱 직접 알아보고 제대로 써야한다는 점으로 볼 수 있다. 따라서 무작정 좋은 기술이라고 마구잡이로 썼다가는, 오히려 독이 될 수 있다. 이러한 변화에 뒤쳐지지 않으려면, 계속해서 지속적으로 학습하고 실험하는 자세가 중요하다.
🙇🏻 글 내에 틀린 점, 오탈자, 비판, 공감 등 모두 적어주셔도 됩니다. 감사합니다..! 🙇🏻
