Data Base
1.DataBase의 개요
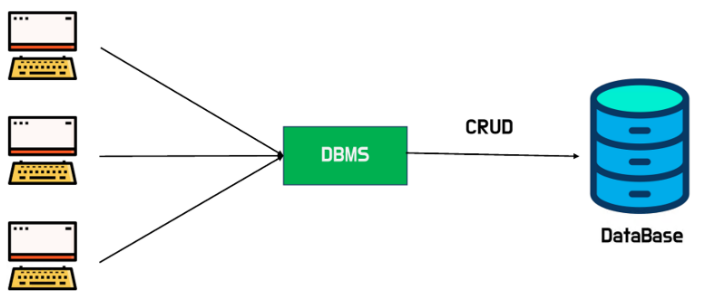
관찰의 결과로 나타난 정량적 혹은 정성적인 실제 값을 의미한다.자료들이라고 생각하면 편함데이터를 기반으로 의미를 부여한 것잘 정돈한 자료들을 불러모아 온 정보한 조직에 필요한 정보를 여러 응용 시스템에서 공용할 수 있도록 논리적으로 연관된 데이터를 모으고, 중복되는 데
2.SQL - SELECT

쿼리 진행 순서From절을 가장 먼저 판단Select절에 있는 컬럼을 조회데이터 출력전체를 조회하고 싶을 때일부 컬럼만 조회하고 싶을 때단독 셀렉별칭전체를 조회하고 싶을 때일부 컬럼만 조회하고 싶을 때단독 셀렉별칭Oracle과 MariaDB와 다른 점Oracle에서는
3.SQL - ORDER_BY

쿼리 진행 순서From절Select조회한 데이터 Order by로 정렬무조건 맨 마지막에 적혀야 함정렬의 기본은 오름차순select문과 함께 사용하며 결과 집합을 특정 열이나 열들의 값에 따라 정렬하는데 사용함null값에 대한 정렬Field와 ORDER_BY에 Fiel
4.SQL - WHERE
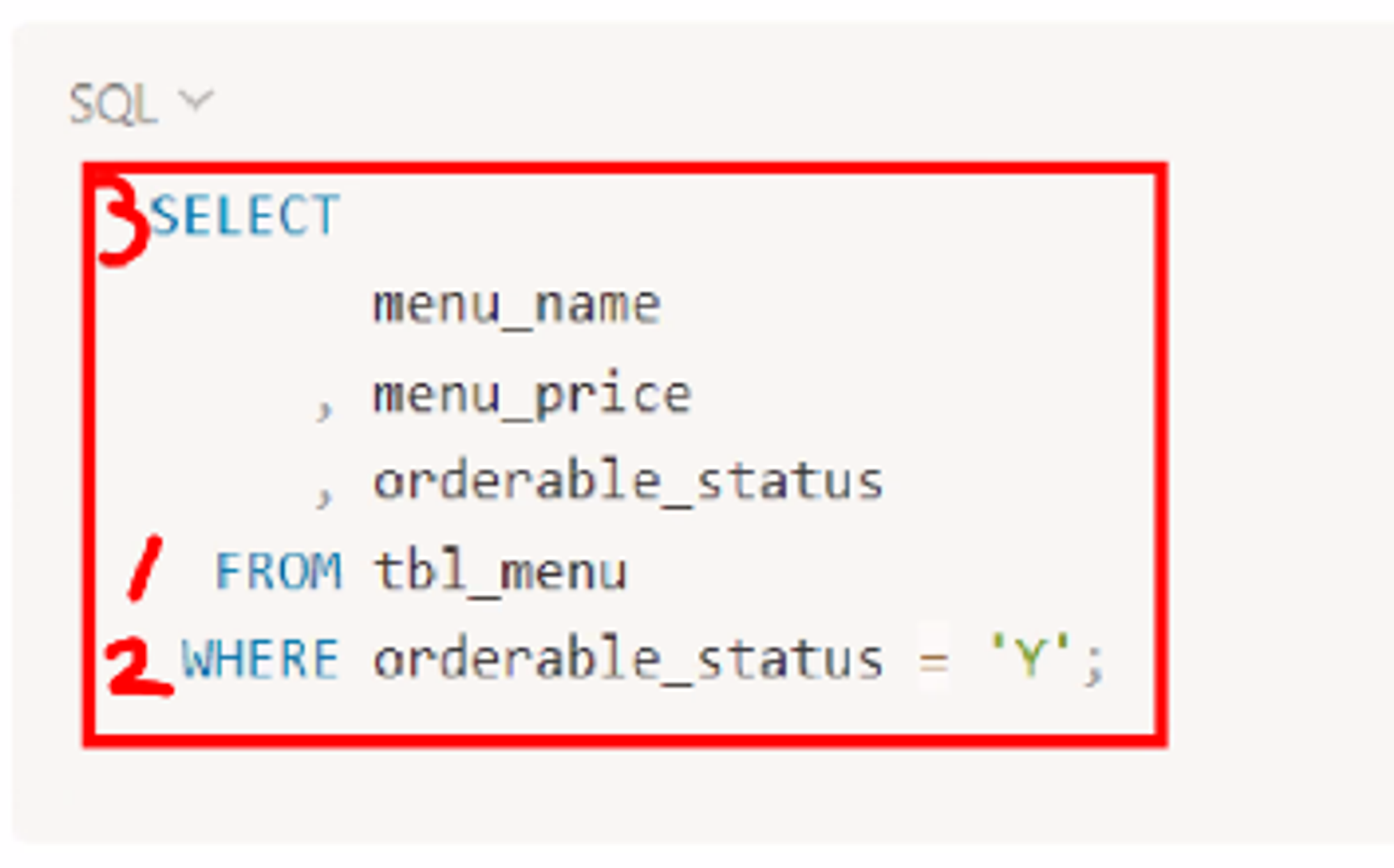
쿼리 진행 순서 tbl_menu라는 테이블에서 조건부와 값이 같을 경우 true로 나오고, 다를 경우 false가 나오는데 y인 값만 출력하도록 되어 있으니 y인 값을 조회해서 select 절에 있는 데이터를 모두 조회할 수 있도록 함 1. 비교 연산자 > 같지
5.SQL - DISTINCT
1. DISTINCT DISTINCT는 중복된 값을 제거하는데 사용된다. 컬럼에 있는 컬럼값들의 종류를 쉽게 파악할 수 있다. null도 한 종류로 봄 distinct는 해당 컬럼의 종류를 보여준다 distinct 사용 시에는 일반 컬럼을 사용할 수 없다.(disti
6.SQL - LIMIT
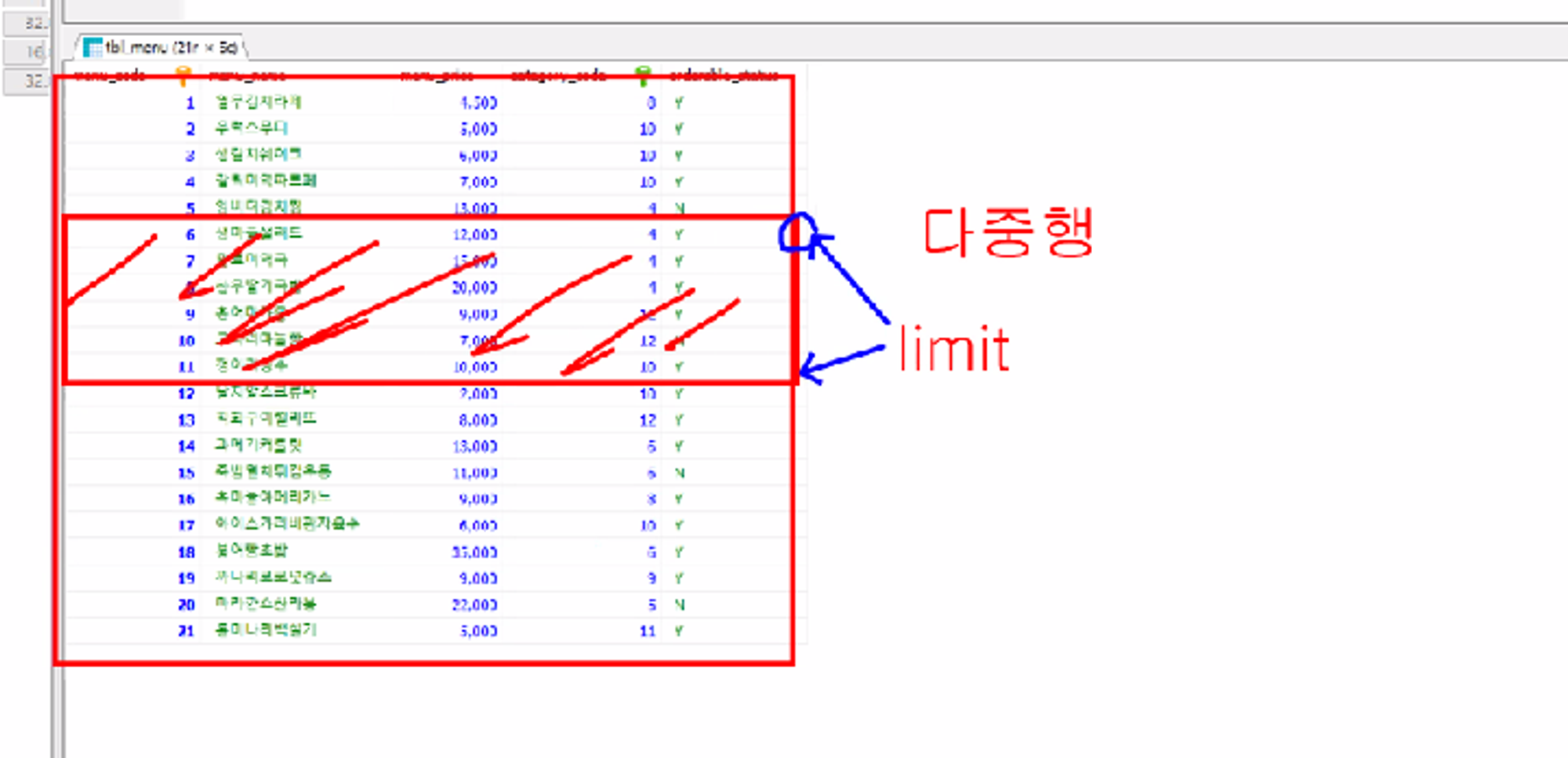
LIMIT 절은 SELECT문의 결과 집합에서 반환할 행의 수를 제한하는데 사용된다.offset 생략시LIMIT 대신 ROWNUM 사용OFFSET 생략 시Oracle에서는 LIMIT의 OFFSET 기능을 ROWNUM과 함께 직접적으로 사용하기 어렵기 때문에 ROW_NU
7.SQL - JOIN
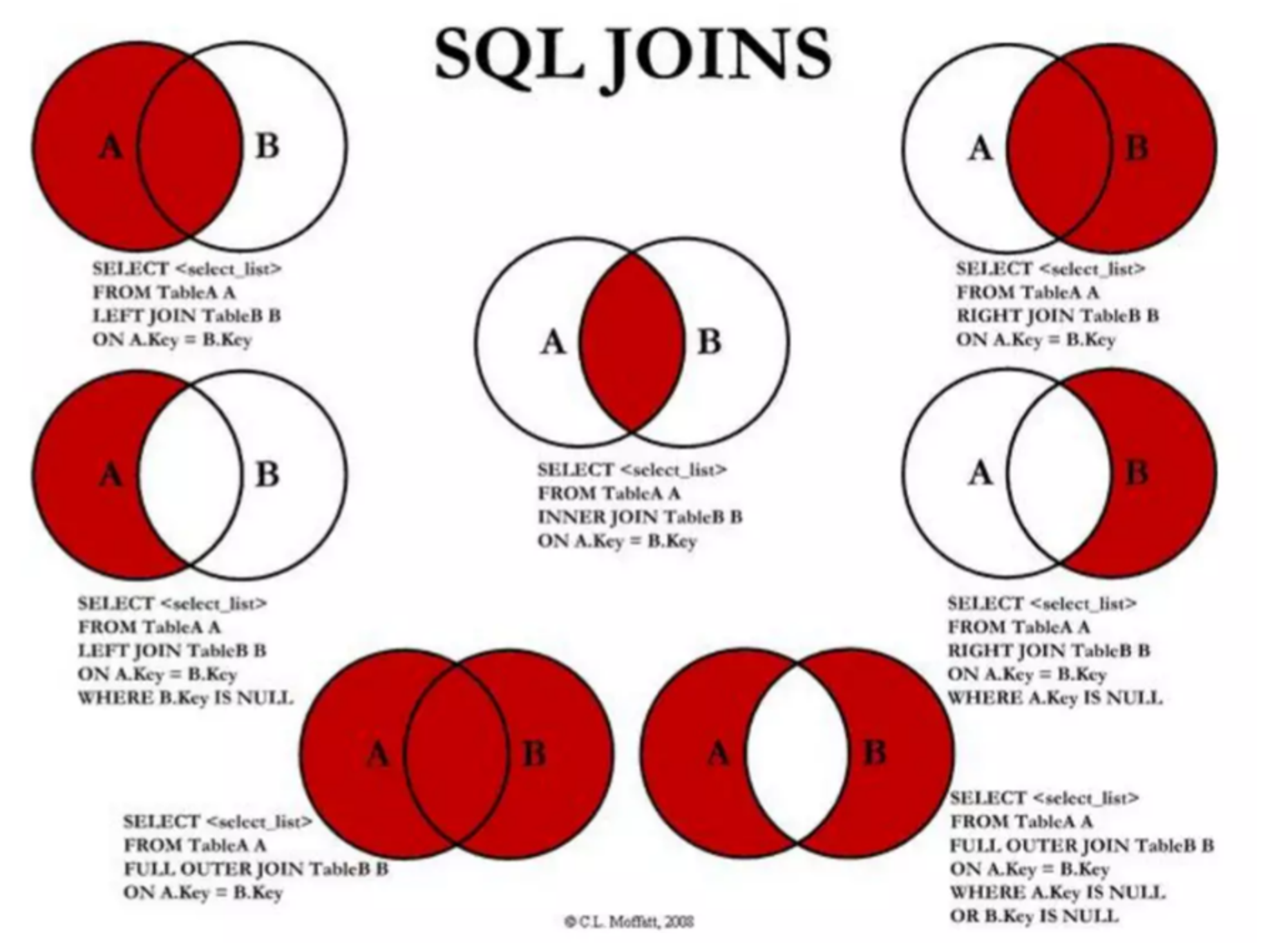
JOIN은 두 개 이상의 테이블을 관련있는 컬럼을 통해 결합하는데 사용된다.두 개 이상의 테이블은 반드시 연관있는 컬럼이 존재해야 하며 이를 통해 JOIN된 테이블들의 컬럼을 모두 활용할 수 있다.join은 사실 from절에 있음업로드중..join은 관계를 맺은 다른
8.SQL - GROUPING
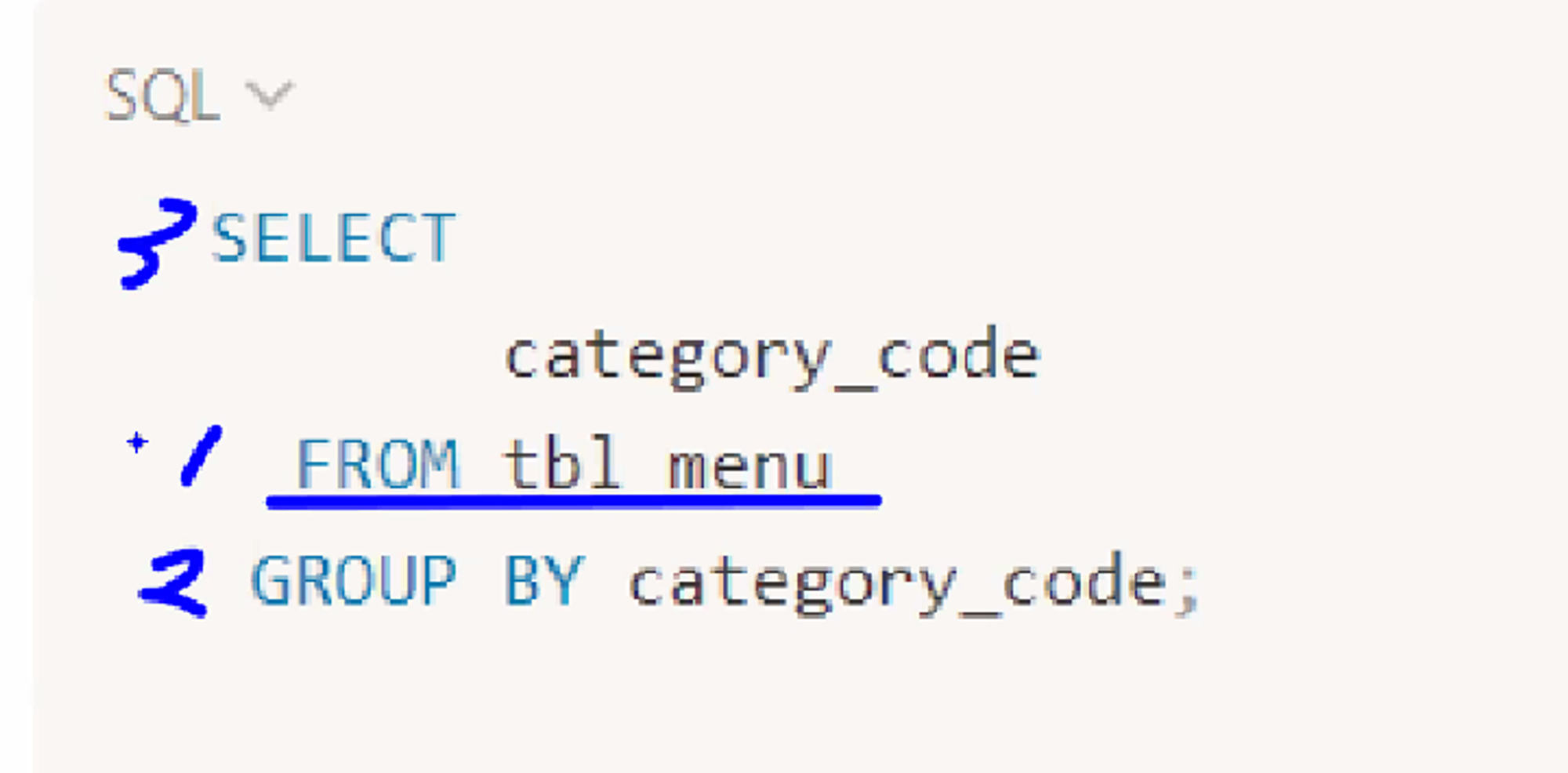
group by절은 결과 집합을 특정 열의 값에 따라 그룹화하는데 사용된다.HAVING은 GROUP BY 절과 함께 사용해야 하며 그룹에 대한 조건을 적용하는데 사용GROUP BY 쿼리 진행 순서where절 있을 경우 쿼리 진행 순서order by까지 있을 경우 쿼리
9.SQL - SUBQUERIES
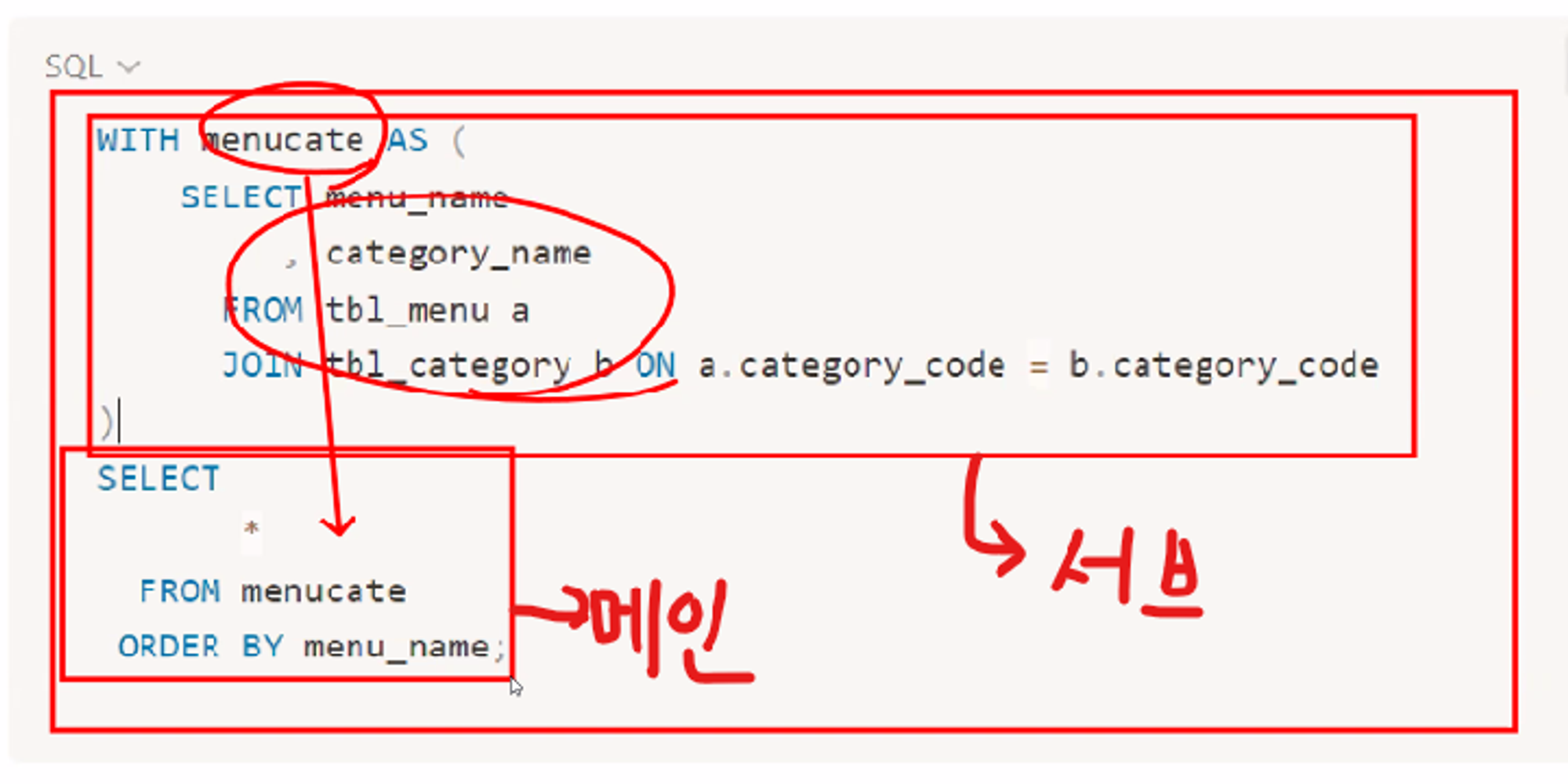
SUBQUERIES는 다른 쿼리 내에서 실행되는 쿼리이다.SUBQUERIES의 결과를 활용해서 복잡한 MAINQUERY를 작성해 한번에 여러 작업을 수행할 수 있다.서브쿼리와 메인 쿼리를 활용한 다중열 결과 조회서브쿼리메인쿼리범위가 큰게 메인 쿼리, 범위가 좁으면 서브
10.SQL - SET_OPERATORS
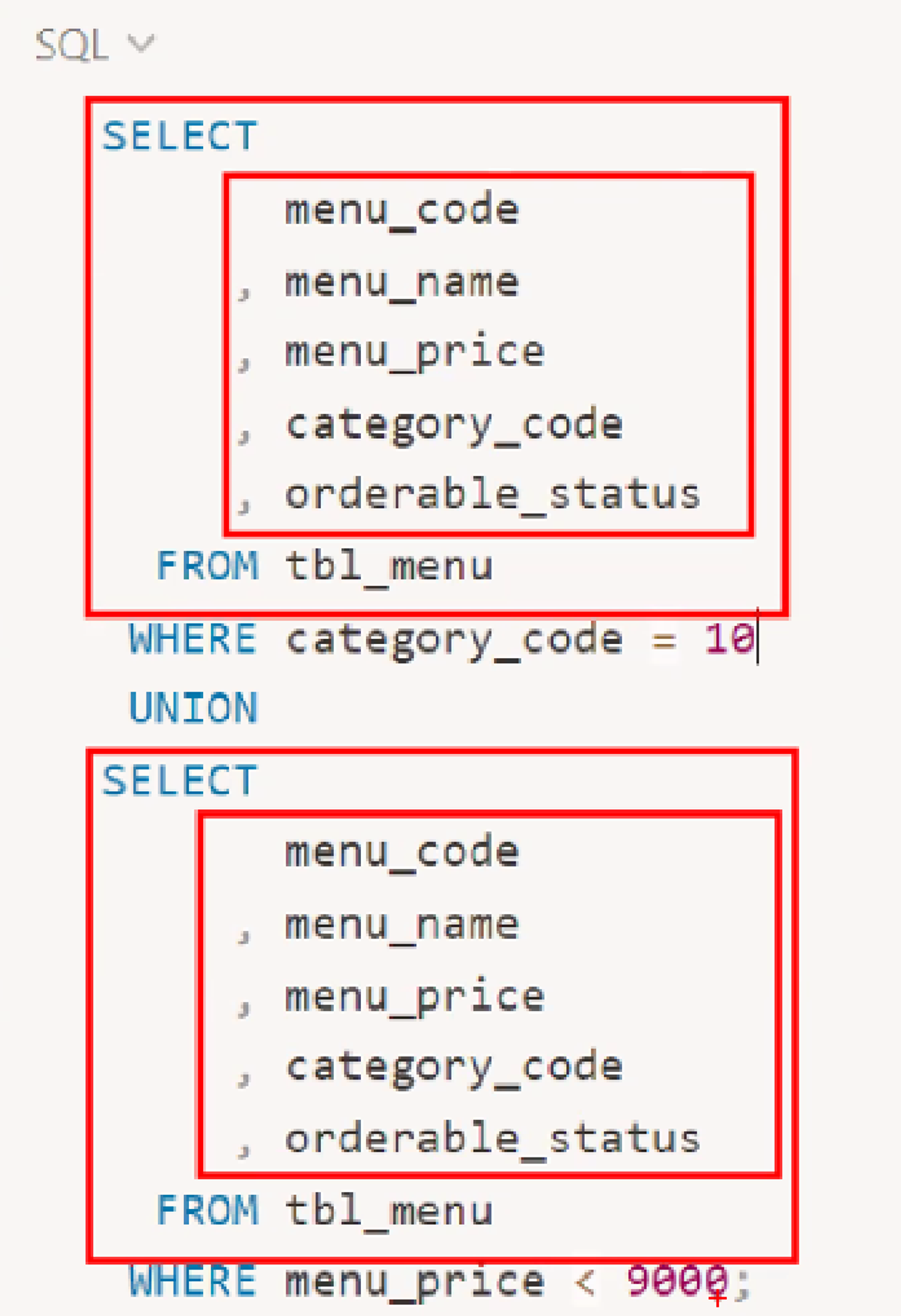
SET 연산자는 두 개 이상의 SELECT문의 결과 집합을 결합하는데 사용한다.SET 연산자를 통해 결합하는 결과 집합의 컬럼이 동일해야 한다.업로드중..join이 가로로 하는 거라면 set operators는 세로로 병합하는 것두 개 이상의 SELECT 문의 결과를
11.SQL - DML
데이터 조작언어, 테이블에 값을 삽입하거나 수정하거나 삭제하는(데이터베이스 내의 데이터를 조작하는데 사용하는) SQL의 한 부분이다.새로운 행을 추가하는 구문테이블의 행의 수가 증가null 허용 가능한(NULLABLE) 컬럼이나 AUTO_INCREMENT가 있는 컬럼을
12.SQL - TRANSACTION
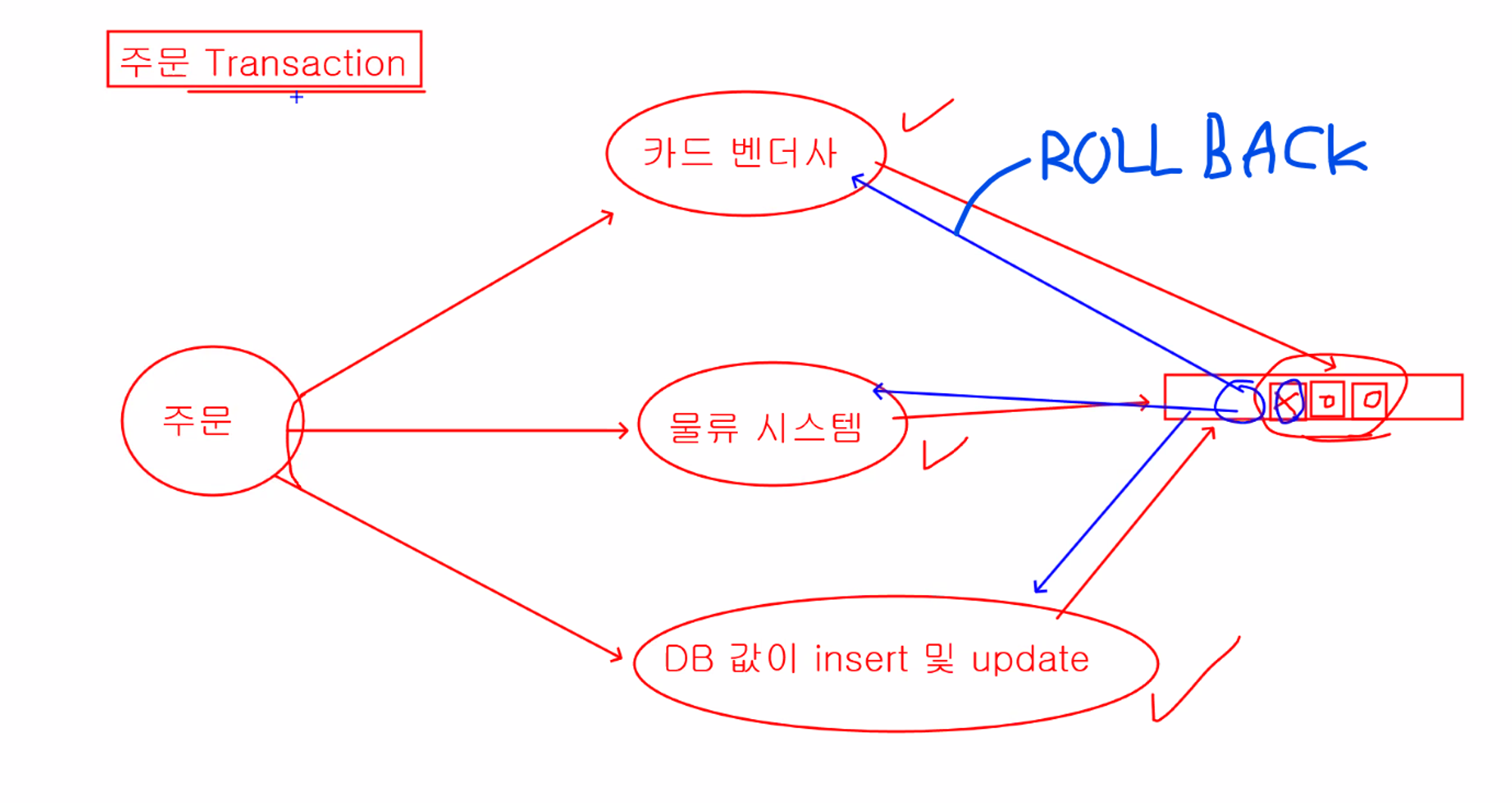
일의 논리적 단위데이터베이스에서 한 번에 수행되는 작업시작, 진행, 종료 단계를 가지며 만약 중간에 오류가 발생하면 롤백(시작 이전 단계로 되돌리는 작업)을 수행하고 데이터 베이스에 제대로 반영하기 위해서는 커밋(이후 롤백이 되지 않음)을 진행autocommit을 비활
13.SQL - DDL
스키마(데이터 틀)를 정의하거나 수정하는데 사용되는 SQL의 한 부분이다.스키마(schema): 테이블의 구조(컬럼, 자료형, 자료형 크기, 테이블 명 등) 및 제약조건(primary, unique, not null, check, foreign key) 전반을 아울러
14.SQL - CONSTRAINTS

데이터 무결성을 보장하는데 도움이 됨제약조건으로 테이블에 데이터가 입력되거나 수정될 때의 규칙을 정의컬럼 레벨에만 작성NULL값을 허용하지 않는 제약조건컬럼 레벨에도 작성할 수 있고, 테이블 레벨 밑에도 작성 가능중복값 허용하지 않는 제약조건PK = PRIMARY KE
15.SQL - DATA_TYPE
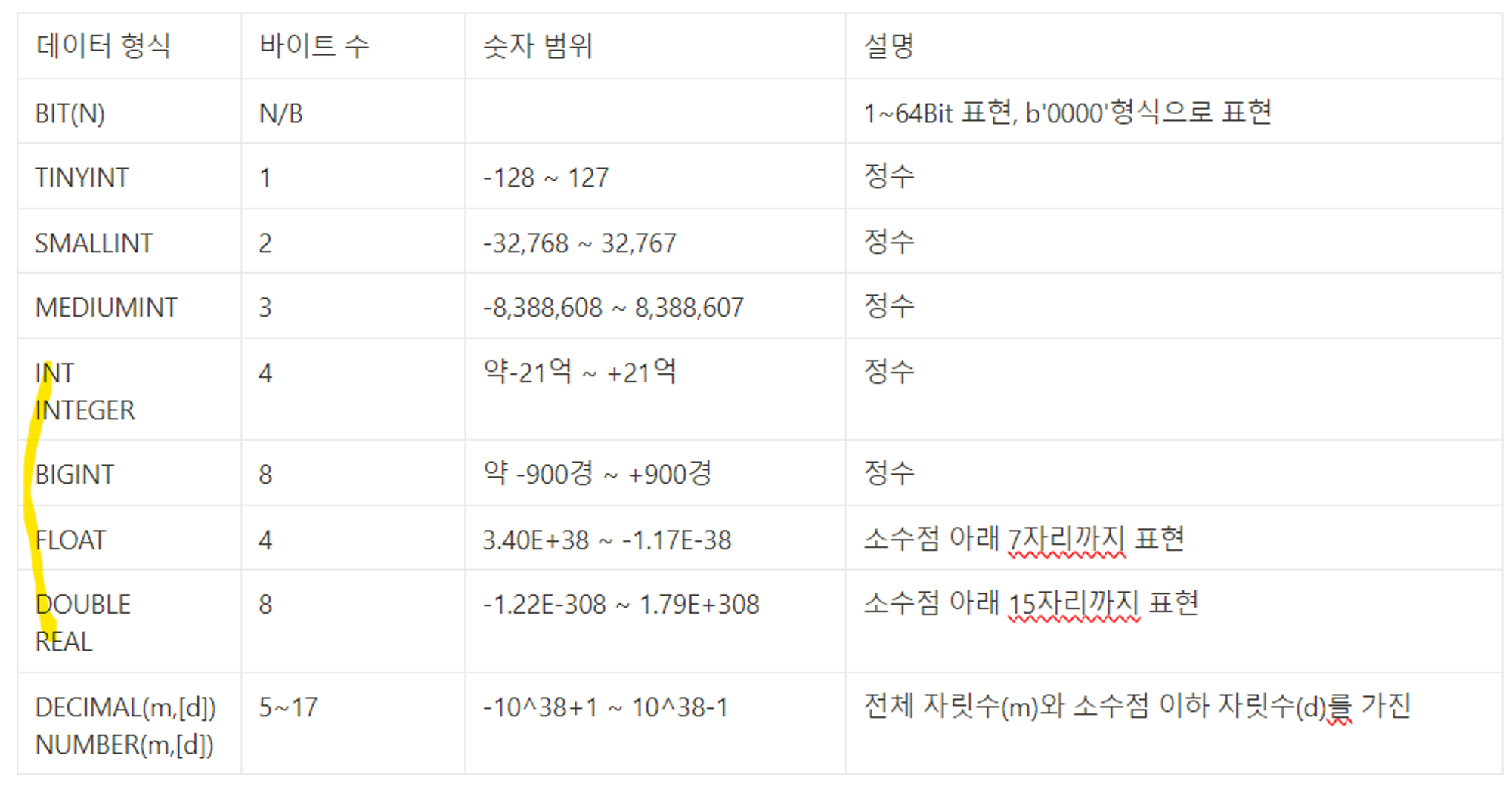
여러가지 데이터 유형 지원: 문자열, 숫자, 날짜, 시간적절한 데이터 유형을 정의하면 데이터 저장 공간을 효율적으로 사용하고 데이터 입력의 유효성 검사에도 도움이 됨정수 또는 실수 등의 숫자를 표현한다.FLOAT이나 DOUBLE형은 큰 범위의 숫자를 저장할 수 있지만
16.SQL - BUILD IN FUNCTIONS
문자열, 숫자, 날짜, 시간에 관한 다양한 작업 수행에 많은 내장 함수 제공ASCII(아스키 코드), CHAR(숫자)아스키 코드 FIND_IN_SET(찾을 문자열, 문자열 리스트), INSTR(기준 문자열, 부분 문자열), LOCATE(부분 문자열, 기준 문자열)TRI
17.SQL - VIEW
SELECT 쿼리문을 저장한 객체로 가상테이블이라고 불림실질적인 데이터를 물리적으로 저장하고 있지 않고 쿼리만 저장했지만 테이블을 사용하는 것과 동일하게 사용할 수 있음데이터를 쉽게 읽고 이해할 수 있도록 돕는 동시에, 원본 데이터의 보안을 유지하는데 도움이 됨결과SE
18.SQL - INDEX
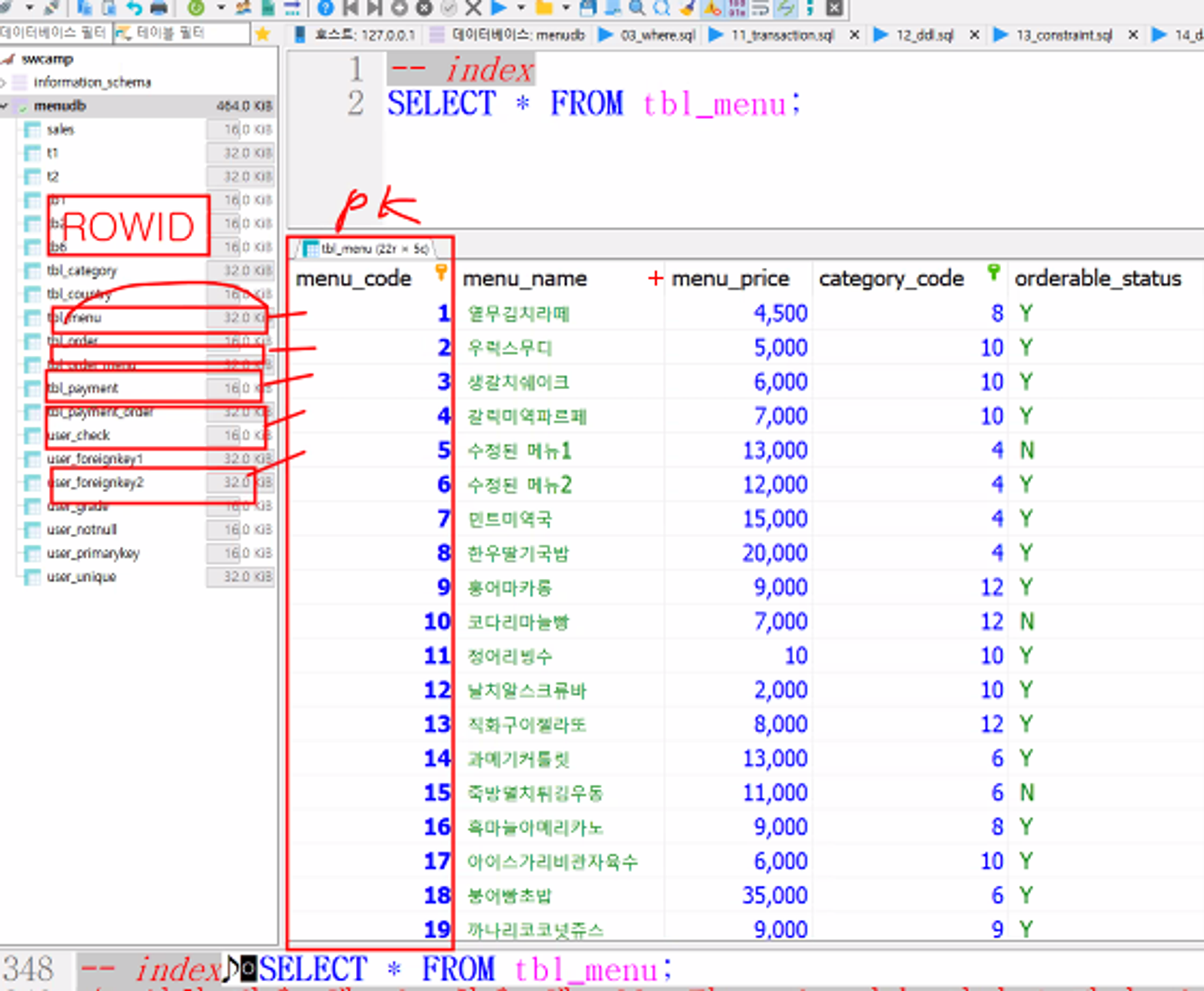
인덱스(Index)는 데이터 검색 속도를 향상시키는 데이터 구조로 데이터를 빠르게 조회할 수 있는 포인터를 제공함데이터베이스에서 데이터를 찾을 때 전체 테이블을 검색하는 대신 인덱스를 통해 검색을 하므로 속도가 더 빨라지게 됨인덱스는 주로 WHERE절의 조건이나 JOI
19.SQL - TRIGGER
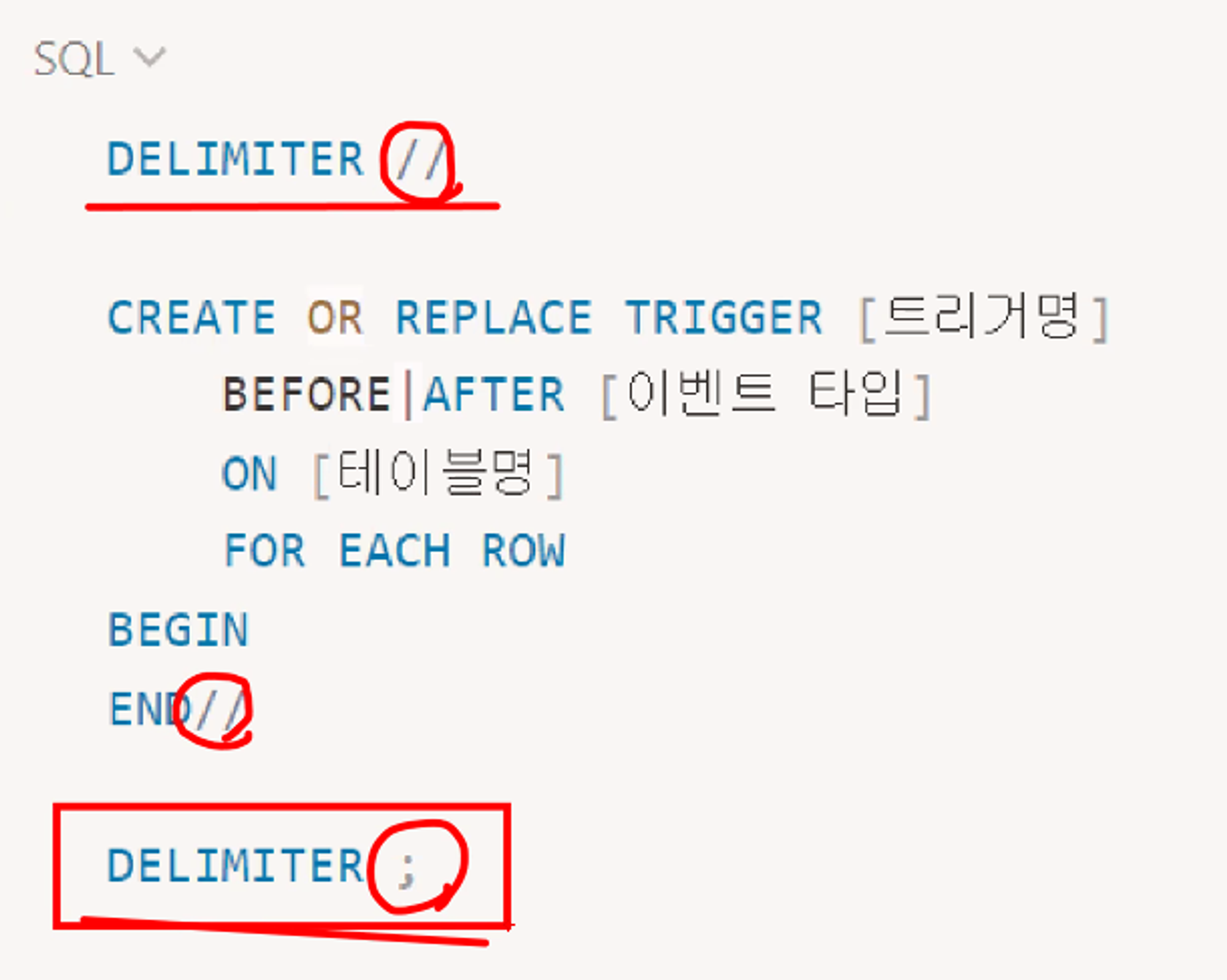
데이터베이스 테이블에서 발생하는 특정 이벤트(INSERT, UPDATE, DELETE)가 발생했을 때 자동으로 실행되는 데이터베이스 객체이다.주요 사용 목적은 데이터의 무결성을 유지하고 복잡한 비즈니스 로직을 처리하기 위함이다.다만 트리거를 남용할 시 성능 문제나 복잡
20.SQL, NoSQL, OpenSQL
SQL은 관계형 데이터베이스(Relational Database)를 관리하기 위한 언어로, 데이터를 테이블 형식으로 저장하고 관리하는 방식. 데이터는 고정된 스키마(schema)를 따르며, 이를 통해 데이터 간의 관계를 정의하고 조작할 수 있다.특징:스키마 기반: 데이