본 내용은 "이것이 코딩 테스트다(한빛미디어)"자료를 참고하였습니다.
이진 탐색 알고리즘 소개
-
순차 탐색: 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 확인하는 방법
-
이진 탐색: 정렬되어 있는 리스트에서 탐색의 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법
- 이진 탐색은 시작점(start), 끝점(end), 중간점(mid)를 이용하여 탐색 범위를 설정합니다.
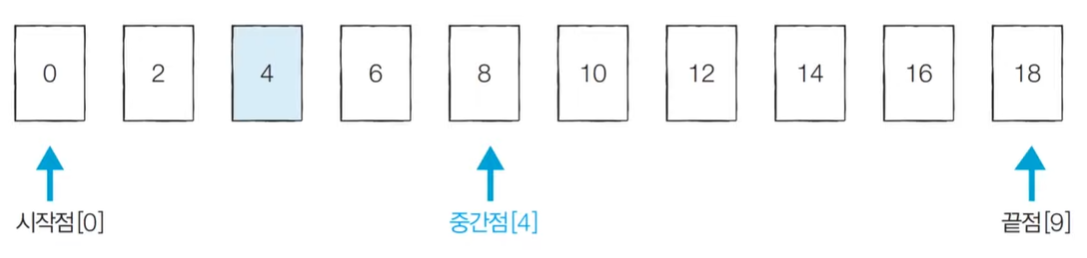
실행과정) 아래의 배열(=A)에서 4(=target)를 찾아 해당 index를 return한다.
※ mid = (start + end) // 2
[Step 1] target < A[mid] -> 0 ~ mid-1로 범위 좁힘
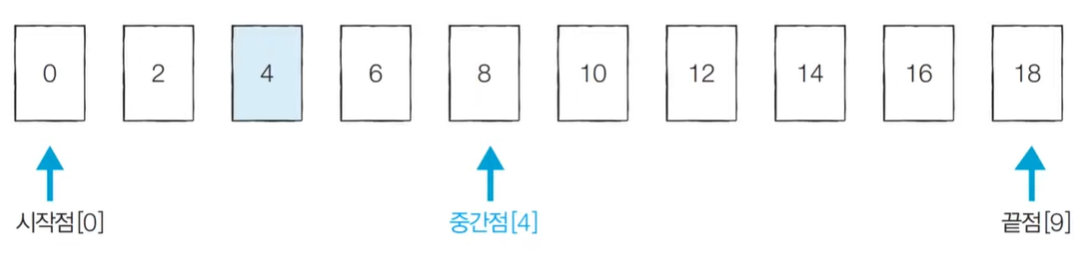
[Step 2] target > A[mid] -> 0 ~ mid-1로 범위 좁힘
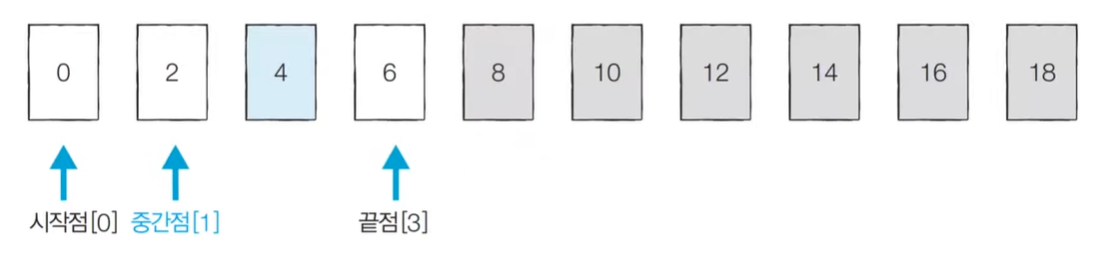
[Step 3] target = A[mid] -> return mid
이진 탐색 알고리즘 시간복잡도
- 단계마다 탐색 범위를 2로 나누는 것과 동일하므로 연산 횟수는 에 비례합니다. (ex. = 3.01)
- 예를 들어 초기 데이터 개수가 10개일 때, 위와같이 1단계를 거치면 4개의 데이터만 남습니다.
- 2단계를 거치면 2개의 데이터만 남습니다.
- 3단계를 거치면 1개의 데이터만 남습니다.
- 다시 말해서 이진 탐색은 탐색 범위를 절반씩 줄입니다. 따라서 시간 복잡도는 O()을 보장합니다.
이진 탐색 알고리즘 구현
'''재귀함수 방식'''
def binary_search(A, start, end, target):
# return index of target in A[start] ... A[end]
if start > end: return None
mid = (start + end)//2
if target == A[mid]: #값을 찾았다!
return mid
elif target < A[mid]:
return binary_search(A, start, mid-1, target)
else:
return binary_search(A, mid+1, end, target)'''반복문 방식'''
def binary_search2(A, start, end, target):
while start <= end:
mid = (start+end)//2
if target == A[mid]: #값을 찾았다!
return mid
elif target < A[mid]:
end = mid - 1
else:
start = mid + 1
return None파이썬 이진 탐색 라이브러리
- binsect_left(A, x): 정렬된 순서를 유지하면서 배열A에 x를 삽입할 가장 왼쪽 인덱스를 반환
- binsect_right(A, x): 정렬된 순서를 유지하면서 배열A에 x를 삽입할 가장 오른쪽 인덱스를 반환
from binsect import binsect_left, binsect_right
A = [1, 2, 4, 4, 8]
x = 4
print(binsect_left(A, x)) # 2
print(binsect_right(A, x)) # 4파라메트릭 서치(Parametric Search)
- 파라메트릭 서치란 최적화 문제를 결정 문제('Yes' or 'No')로 바꾸어 해결하는 방법입니다.
- 예: 특정한 조건을 만족하는 가장 알맞은 값을 빠르게 찾는 최적화 문제
- 일반적으로 코딩 테스트에서 파라메트릭 서치 문제는 이진탐색을 이용하여 해결할 수 있습니다.
문제1) 떡볶이 떡 만들기
문제 설명
- 오늘 길동이는 여행가신 부모님을 대신해서 떡집 일을 하기로 했습니다. 오늘은 떡볶이 떡을 만드는 날입니다. 길동이네 떡볶이 떡은 재밌게도 떡볶이 떡의 길이가 일정하지 않습니다. 대신에 한 봉지 안에 들어가는 떡의 총 길이는 절단기로 잘라서 맞춰줍니다.
- 절단기의 높이(H)를 지정하면 줄지어진 떡을 한 번에 절단합니다. 높이가 H보다 긴 떡은 H 위의 부분이 잘릴 것이고, 낮은 떡은 잘리지 않습니다.
- 예를 들어 높이가 19, 14, 10, 17cm인 떡이 나란히 있고 절단기 높이를 15cm로 지정하면 자른 뒤 떡의 높이는 15, 14, 10, 15cm가 될 것입니다. 잘린 떡의 길이는 차례대로
4, 0, 0, 2cm입니다. 손님은 총 6cm만큼의 길이를 가져갑니다. - 손님이 왔을 때 요청한 총 길이가 M일 때, 적어도 M만큼의 떡을 얻기 위해 절단기에 설정할 수 있는 높이의 최댓값을 구하는 프로그램을 작성해보세요.
제한 사항
첫째 줄에 떡의 개수 N과 요청한 떡의 길이 M이 주어진다. (1<=N<=1,000,000, 1<=M<=2,000,000,000)
둘째 줄에는 떡의 개별 높이가 주어진다. 떡 높이의 총합은 항상 M 이상이므로, 손님은 필요한 양만큼 떡을 사갈 수 있다. 높이는 10억보다 작거나 같은 양의 정수 또는 0이다.
입력 예시
4 6
19 15 10 17
출력 예시
15
문제 해결 아이디어
- 적절한 높이를 찾을 때까지 이진 탐색을 수행하여 높이 H를 반복해서 조정하면 됩니다.(높이가 커지면 잘린 떡의 길이 감소, 높이가 낮으면 잘린 떡의 길이 증가)
- '현재 이 높이로 자르면 조건을 만족할 수 있는가?(M만큼의 떡을 얻을 수 있는가?)'를 확인한 뒤에 조건의 만족 여부('Yes' or 'No')에 따라 탐색 범위를 좁혀서 해결할 수 있습니다.
- 절단기의 높이는 0부터 10억까지의 정수 중 하나 입니다.
- 이렇게 큰 탐색 범위를 보면 가장 먼저 이진탐색을 떠올려야합니다.
- 문제에서 제시된 예시를 그림을 통해 이해해봅시다.
[Step 1] 시작점: 0, 끝점: 19, 중간점: 9, 잘린 떡의 총 길이: 25 (M=6)
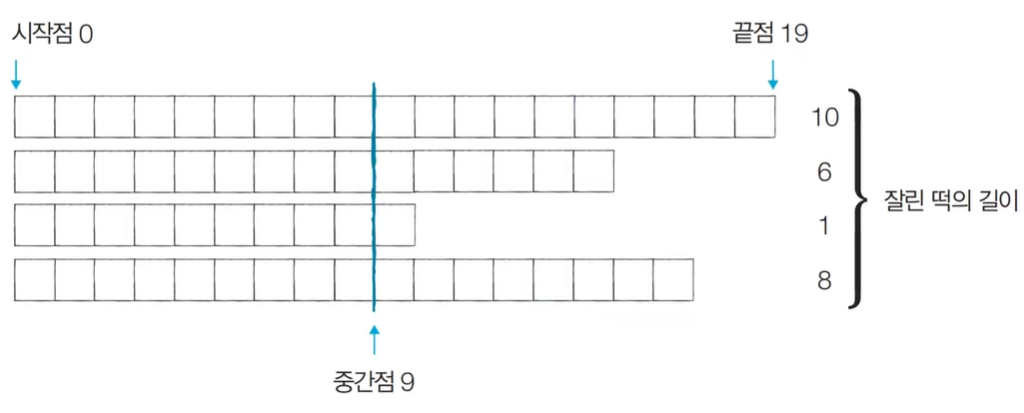
[Step 2] 시작점: 10, 끝점: 19, 중간점: 14, 잘린 떡의 총 길이: 9 (M=6)
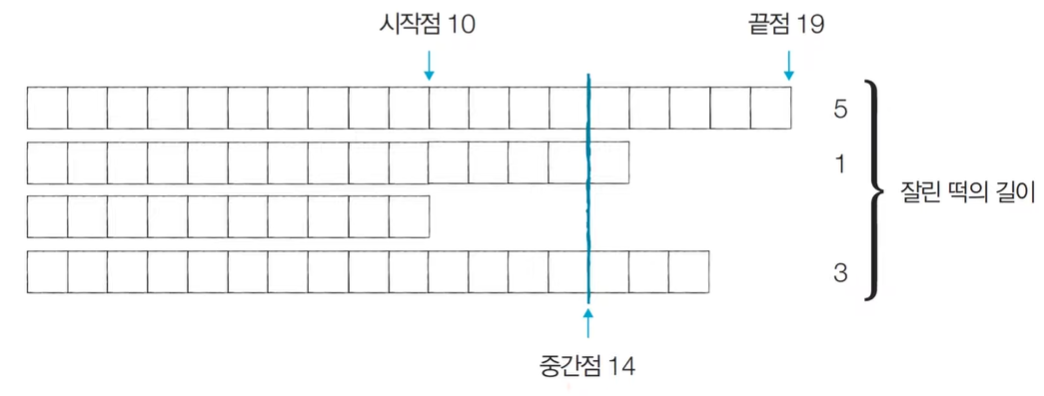
[Step 3] 시작점: 15, 끝점: 19, 중간점: 17, 잘린 떡의 총 길이: 2 (M=6)
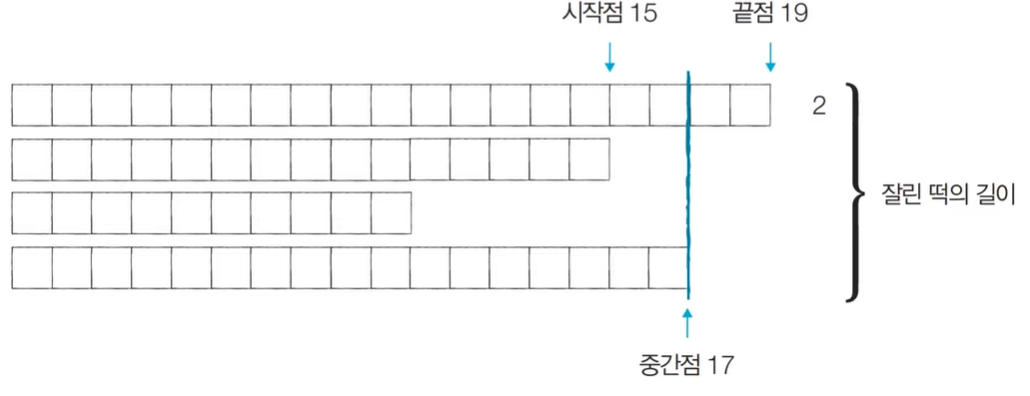
[Step 4] 시작점: 15, 끝점: 16, 중간점: 15, 잘린 떡의 총 길이: 6 (M=6)
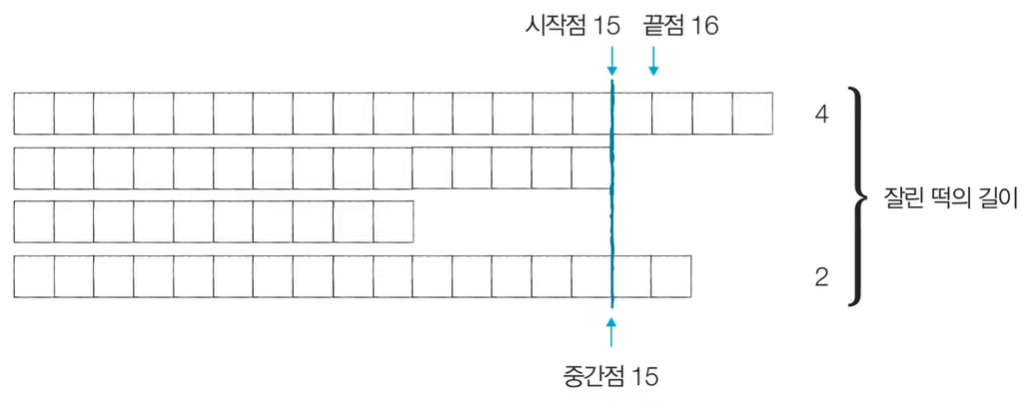
이와 같이 이진탐색을 통해서 탐색범위를 지속적으로 좁히면서 시작점과 끝점의 위치를 조정하며 높이값(중간점=H)를 매번 바꾸며 해당 높이에서 잘랐을때 떡의 총 길이가 적합한지 체크한다.
코드 구현
# 떡의 개수(N)와 요청한 떡의 길이(M)을 입력
n, m = list(map(int, input().split(' ')))
# 각 떡의 개별 높이 정보를 입력
array = list(map(int, input().split()))
# 이진 탐색을 위한 시작점과 끝점 설정
start = 0
end = max(array)
'''
max = array[0]
for i in range(1, len(array)):
if max < array[i]:
max = array[i]
end = max
'''
# 이진 탐색 수행 (반복문 방식)
result = 0
while(start <= end):
total = 0 # 잘린 떡의 총 길이 저장
mid = (start + end) // 2
for x in array:
# 잘랐을 때의 떡볶이 양 계산
if x > mid:
total += x - mid
# 떡볶이 양이 부족한 경우 더 많이 자르기 (오른쪽 부분 탐색)
if total < m:
end = mid - 1
# 떡볶이 양이 충분한 경우 덜 자르기 (왼쪽 부분 탐색)
else:
result = mid # 최대한 덜 잘랐을 때가 정답이므로, 여기에서 result에 기록
start = mid + 1
# 정답 출력
print(result)문제2) 정렬된 배열에서 특정 수의 개수 구하기
문제설명
- N개의 원소를 포함하고 있는 수열이 오름차순으로 정렬되어 있습니다. 이때 이 수열에서 x가 등장하는 횟수를 계산하세요. 예를 들어 수열 [1, 1, 2, 2, 2, 2, 3]이 있을 때 x=2라면, 현재 수열에서 값이 2인 원소가 4개이므로 4를 출력합니다.
- 단, 이 문제는 시간 복잡도 O()으로 알고리즘을 설계할 것
제한 사항
- 첫 줄에 N과 x가 정수 형태로 공백으로 구분되어 입력됩니다. (1 <= N <= 1,000,000), ()
- 둘째 줄에 N개의 원소가 정수 형태로 공백으로 구분되어 입력됩니다. ( 각 원소의 값 )
- 수열의 원소중에서 값이 x인 원소의 개수를 출력합니다. 만약 값이 x인 원소가 하나도 없다면 -1을 출력합니다.
입력
7 2
1 1 2 2 2 2 3
출력
4
문제 해결 아이디어
- 시간 복잡도 O()으로 동작하는알고리즘을 요구하고 있습니다.
- 데이터가 정렬되어 있기 때문에 이진 탐색을 수행할 수 있습니다.
- 특정 값이 등장하는 첫 번째 위치와 마지막 위치를 찾아 위치 차이를 계산해 문제를 해결할 수 있습니다.
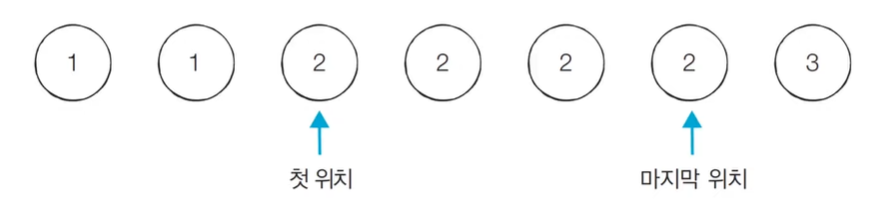
- 이진탐색을 동시에 두 번 진행해서 양쪽으로 x값을 계속 찾아간 다음 서로 최종값을 빼준다.
count_by_range는 많이 사용되는 함수이므로 알아두면 좋음
코드 구현
'''binsect 라이브러리 사용'''
from binsect import binsect_left, binsect_right
# 값이 [left_value, right_value]인 데이터의 개수를 반환하는 함수
def count_by_range(A, left_value, right_value):
right_index = binsect_right(A, right_value)
left_index = binsect_left(A, left_value)
return right_index - left_index
# 데이터의 개수 N, 찾고자 하는 값 x 입력받기
n, x = map(int, input().split())
# 전체 데이터 입력받기
A = list(map(int, input().split()))
count = count_by_range(A, x, x)
#값이 x인 원소가 존재하지 않는다면
if count == 0:
print(-1)
else:
print(count)'''라이브러리 사용x'''
# 데이터의 개수 N, 찾고자 하는 값 x 입력받기
N, x = map(int, input().split())
# 전체 데이터 입력받기
data = list(map(int, input().split()))
start = 0
end = len(data) - 1
total = 0
while start <= end:
mid = (start + end) // 2
if x == data[mid]:
for i in range(mid, -1, -1):
if data[i] == x:
total += 1
else:
break
for j in range(mid + 1, len(data)):
if data[j] == x:
total += 1
else:
break
break
elif x < data[mid]:
end = mid - 1
else:
start = mid + 1
#값이 x인 원소가 존재하지 않는다면
if total == 0:
print(-1)
else:
print(total)
부족한 부분을 인지하는 것부터가 배움의 시작이다.