Object Detection 개념
2012년 AlexNet 이 Image Classification 에서 우승하면서 딥러닝 기반 기술이 발전하기 시작했다. 이후 Image Classificatoin 에서 사용된 기술들이 Object Detection 분야로 옮겨오면서 발전하기 시작, 역시나 딥러닝 기술들이 흥행하기 시작했다.
Classification: 이미지에 담긴 내용이 무엇인지 하나로 분류하는 것.
아래는 Object 의 위치를 찾아내는 것들이다.
Localization: 하나의 이미지 안에서 하나의 내용물(Object)이 어디있는지 확인하는 것
Detection: 하나의 이미지 안에 여러 Object 를 bounding box 로 잡아내는 것.
Segmentation: 여러 Object 를 박스가 아닌 개별 픽셀값으로 잡아내는 것.
따라서
- Localization/Detection 은 해당 Object 의 위치를 bounding box 로 찾고, bounding box 내의 오브젝트를 판별하는 것이다.
- 위 두가지는 bounding box + classification 이다.

✅ (참고) Object Detection History
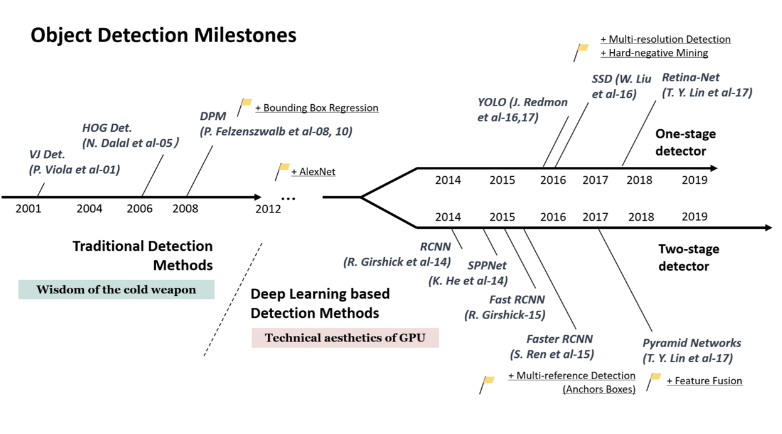
- Two stage detector: 실시간 적용이 어렵다는 문제 (RNN, SPPNet, Fast RCNN, Faster RCNN, Pyramid Networks)
- One stage detector: YOLO, SSD, YOLO2, Retina-Net, EfficientDet(D0), YOLO4,5..
Object Detection 주요 구성요소 이해
- 영역추정: 오브젝트가 있을만한 위치에 힌트를 주는 것이다, Region Proposal
- Detectoin 위한 DeepLearning 네트워크 구성: Feature Extraction & FPN & Network Prediction
- Detection 구성하는 기타요소: IOU, NMS, mAP, Anchor box
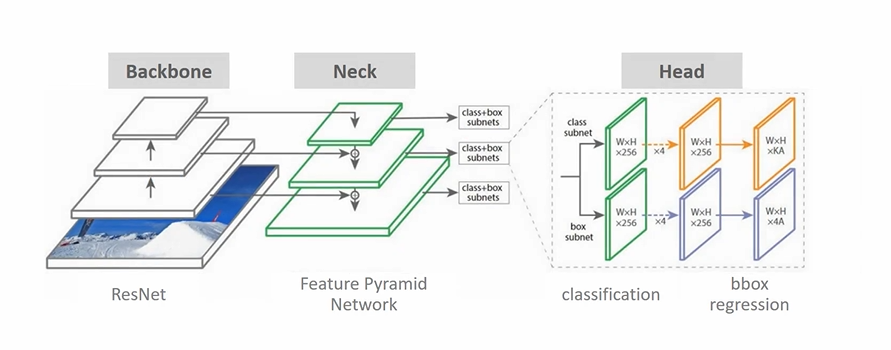
- Backbone 이 Feature Extractor 에 해당하는 부분이다.
- FPN을 Neck으로 차용
- Head: classification 과 Regression 을 수행하게 된다.
따라서 Detection 의 문제는 Classificatoin 분류와 Regression 회귀 문제를 동시에 풀어야한다는 점, 다양한 크기와 유형의 물체들이 항상 섞여있다는 점(bounding box 의 모양), 성능과 시간의 균형 문제 등으로 해결하기 어려운 문제이다.
Object Localization 개요
원본 이미지에서 하나의 물체만 잡아내는 Localization 개요를 보자.
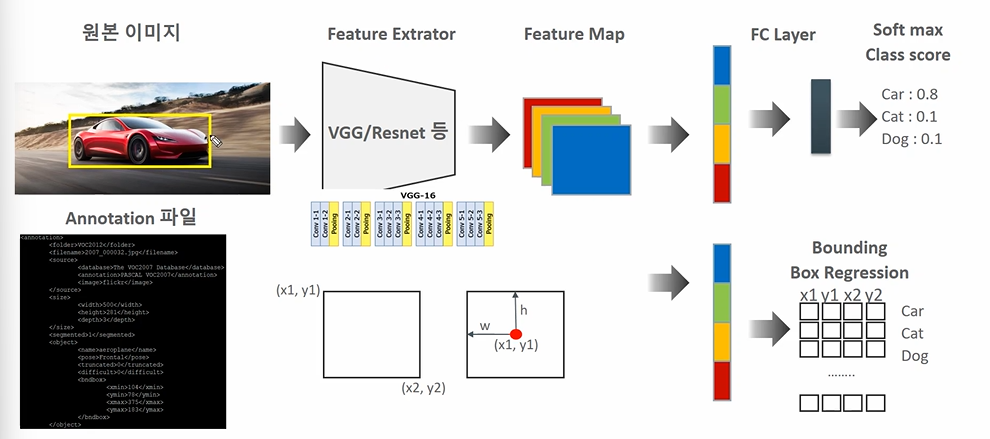
- 원본이미지를 224 X 224 라 하자.
- VGG/Resnet 등 Feature Extractor 를 통해 중요한 피처를 뽑아낸다
- 7 X 7 Feature Map 4개를 512개를 뽑아낸다고 하자 (추상화된 이미지)
- 레이어 하나를 지나 Softmax 로 분류한다. (차인지, 고양이인지, 강아지인지)
- Annotation 파일에는 바운딩박스에 대한 좌표값이 있다. (Center 좌표로 잡을수도)
- Feature map 에서 regression layer 가 따로 존재하고, x1, y1, x2, y2를 예측한다.
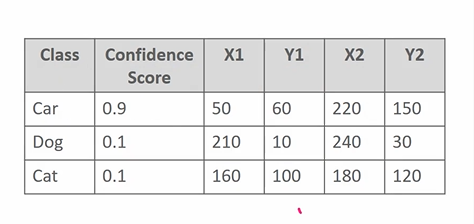
따라서 원본 이미지의 bounding box 가 있고, 예측오류를 줄여나가는 식으로 바운딩 박스의 위치도 확정하는 것이다. confidence score 은 자동차일 확률을 말하고(0.9) 좌표상의 바운딩 박스의 위치를 모두 예측한다.
✅ Detection 같은 경우에는 2개 이상의 오브젝트를 검출해야하는데, 여러 바운딩박스에 대해 inference 하기가 어려워지는 문제가 발생한다. 따라서 'object 가 있을만한 위치를 찾아주는 것'이 중요하다. 이를 Region Proposal 을 학습한다고 하고, 여기에 따라 네트워크도 학습하고, 예측할 땐 Resion proposal 에 기반하여 예측하는 방식을 사용한다.
다시 Object Detect로.. Sliding Window 방식
✅ Slicing Window 방식이란 해당 윈도우 영역을 이동시키면서 윈도우 안에서 Object 를 찾고, 학습된 영역과 매핑하여 bounding box를 찾는 방식이다.
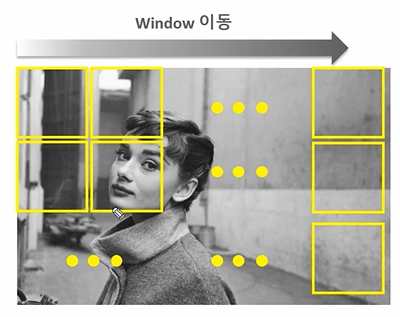
어떤 문제가 있을까? 윈도우 크기, 위치가 오브젝트와 정확히 맞기가 힘들다. 이때문에 1. 다양한 형태의 Window 를 슬라이딩시키거나, 2. 윈도우는 고정하고 원본이미지를 변경한 여러 이미지를 사용할 수 있다.
결국은 Object Detection 의 초기기법 방식일 뿐이다. 오브젝트 없는 경우도 무조건 슬라이딩 하여야 하고, 성능이 낮다는 문제로 현재는 많이 쓰이지 않지만 토대를 제공하는데 역할을 했다! 이제는 방법이 Region Proposal 로 넘어왔다.
Region Proposal 방식
Object 가 있을만한 후보 영역을 찾자라는 방법이다.
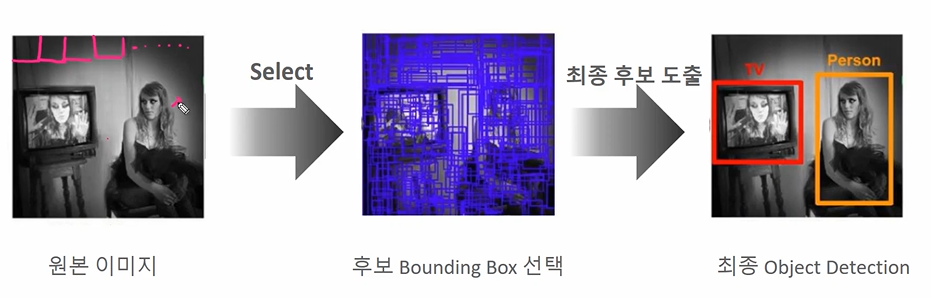
Selective Search 라는 방식으로 후보 바운딩박스를 먼저 선택한 후, 최종 후보를 도출한다.
그렇다면 Selective Search, 즉 후보 영역은 어떻게 찾는가?
- 빠른 Detection 과 높은 Recall 예측 성능을 동시에 만족한다
- 해당 영역의 공유되는 비슷한 픽셀 영역들을 마스킹한다. (Over Segmentation)
- 컬러, Texture, Size, Shape 에 따라 유사한 Region 을 계층적 그룹핑 방법(그룹과 그룹을 합쳐나가며 확장하는 방식)으로 계산한다.
- 비슷한 Segment 를 계속 그룹핑하며 Region Proposal 을 수행한다.

- 비슷한 Segment 를 계속 그룹핑하며 Region Proposal 을 수행한다.
Selective Search 실습
먼저 Selectivesearch 를 설치하고 이미지를 로드한다.
!pip install selectivesearch
import selectivesearch
import cv2
import matplotlib.pyplot as plt
import os
%matplotlib inline
### 오드리헵번 이미지를 cv2로 로드하고 matplotlib으로 시각화
img = cv2.imread('./data/audrey01.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print('img shape:', img.shape)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb)
plt.show()
이미지에서 Region Proposal 을 제시해주는 메서드를 사용한다. 메서드는 selective_search
import selectivesearch
#selectivesearch.selective_search()는 이미지의 Region Proposal정보를 반환
_, regions = selectivesearch.selective_search(img_rgb, scale=100, min_size=2000)
print(type(regions), len(regions))scale 은 스케일 사이즈만큼 건너뛰어가며 proposal 을 검사하는 것이고, min_size 는 반환된 전체 사각형의 최소 사이즈이다. 따라서 두 가지를 늘려보면 regions 의 개수가 줄어든다.
만들어진 region 을 확인해보면 다음과 같다.
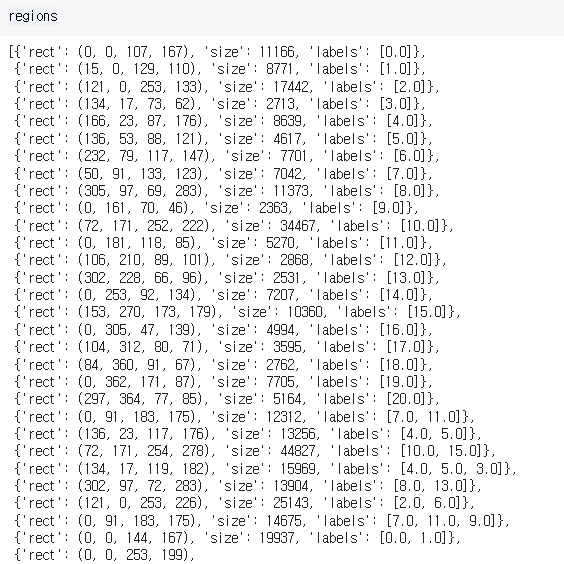
- rect 키 값은 좌상단, 우하단의 값이다. (bounding box)
- size 는 골라진 object 의 크기이다. (바운딩박스 내)
- label 은 고유 ID이며, 아래로 내려가면 7번 라벨과 11번 라벨이 합쳐져서 더 큰 바운딩박스를 만든 것을 확인할 수 있다. (계층적 그룹핑)
여기서는 region 에서 'rect' 가 중요하므로 이들만 따로 모아서 사용한다.
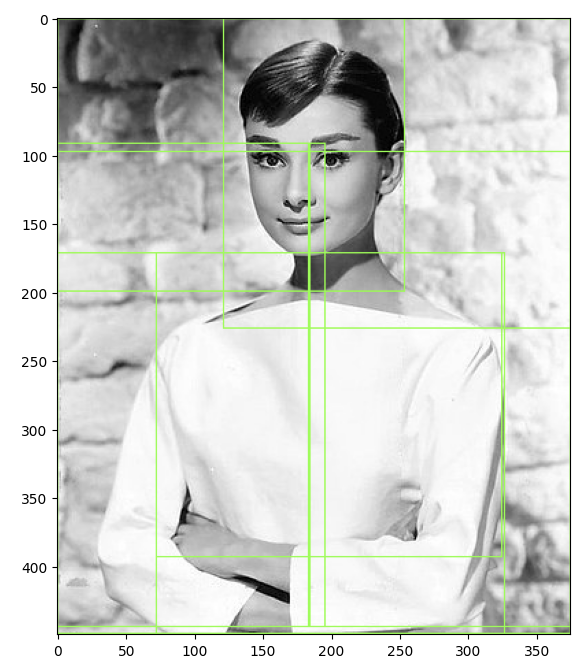
bounding box 시각화
# rect정보만 출력해서 보기
cand_rects = [cand['rect'] for cand in regions]
# opencv의 rectangle()을 이용하여 시각화
# rectangle()은 이미지와 좌상단 좌표, 우하단 좌표, box컬러색, 두께등을 인자로 입력하면 원본 이미지에 box를 그려줌.
green_rgb = (125, 255, 51)
img_rgb_copy = img_rgb.copy()
for rect in cand_rects:
left = rect[0] # 좌
top = rect[1] # 상단
# rect[2], rect[3]은 너비와 높이이므로 우하단 좌표를 구하기 위해 좌상단 좌표에 각각을 더함.
right = left + rect[2] # 우
bottom = top + rect[3] # 하단
img_rgb_copy = cv2.rectangle(img_rgb_copy, (left, top), (right, bottom), color=green_rgb, thickness=1)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb_copy)
plt.show()'우'는 좌에 rect[2] 를 더한 값, '하단'은 상단에 rect[3] 을 더한 값을 사용한다.
cv2.rectangle 에 이미지와 (좌, 상단), (우, 하단) 값과 색, 두께를 인자로 전달하면 이미지에 바운딩박스 후보를 그릴 수 있다.

상단에 위의 코드를 추가하면 바운딩박스 사이즈가 만이상인 것만 추출하여 그릴 수 있다.
cand_rects = [cand['rect'] for cand in regions if cand['size'] > 10000]