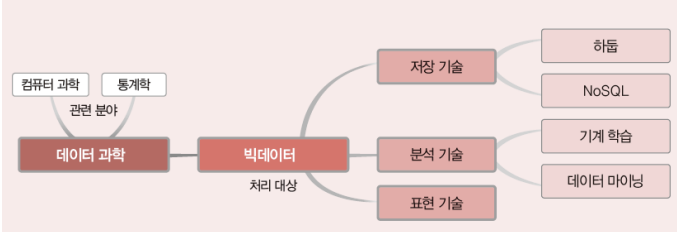
- 저장 기술 : 어떻게 저장
- 분석 기술 : 새로운 정보 획득 (기계학습, 데이터마이닝)
- 표현 기술 : 시각, 전달
1. Data Science
4차 산업혁명서 방대해진 데이터들을 저장하고 관리하기 위해 등장하였다.
- 데이터의 포맷이 정해지지 않은 비정형 데이터가 대부분
- 분류와 검색을 넘어 다양한 활용
여기서는 데이터 과학의 개념을 주어진 데이터에서 새로운 지식을 발견하고, 넓게는 수집하고 저장, 분석, 표현의 과정이라 보았다. 결과적으로 목표는 지식과 지혜를 추출하는 것!
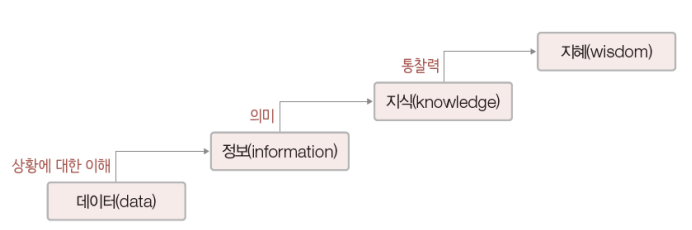
✅ DIKW 계층 구조
-
Data
가장 하단에 속하는 데이터는 관측을 통해 추출한 값을 말한다. (최근 3년간 매월 책 판매량) -
Information
데이터를 목적에 맞게 한 번 가공한 것. (ex. 연간 분기별 책 판매량) -
Knowledge
의미 있고 유용한 정보 (ex. 3분기에 책의 판매량이 증가하는 원인 찾기) -
Wisdom
지식에 통찰력을 더해 새롭고 창의적인 아이디어를 도출 (3분기에 출간할 책을 기획하고, 홍보 전략을 세우는 것)
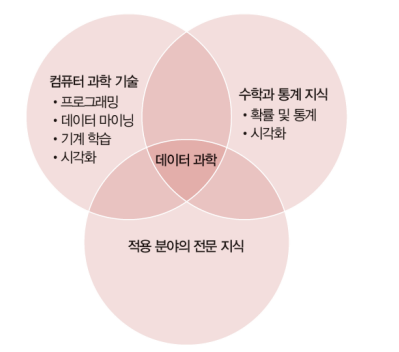
✅ 특징?
2. 빅데이터
-
좁은 정의
대규모의 다양한 데이터 -
넓은 정의
대규모 데이터를 저장, 관리하는 기술과 분석하는 기술까지 포함.
✅ 빅데이터 활용 사례
-
아마존 닷컴
추천 서비스 처음 사용 -
구글
검색 기능, 사용자에게 맞춤형 글과 광고 제시하는데 빅데이터 활용 -
페이스북
-
정치 분야
✅ 빅데이터의 특징
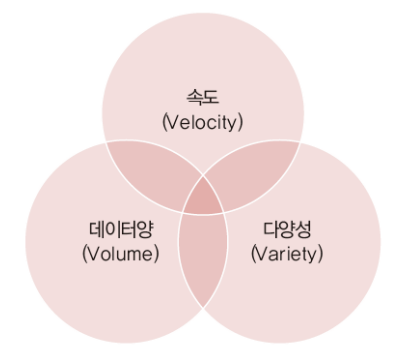
-
Volume: 대량 데이터를 의미
-
Velocity: 정해진 시간 내에, 실시간으로 처리 되어야 한다.
-
Variety: 데이터의 형태, 종류가 다양한 성질 (정형/비정형)
✅ 빅데이터 기술
- 저장 기술
- 하둡(hadoop)
- 대용량 데이터를 분산 처리하는 자바 기반의 오픈 소스 프레임워크
- 분산 파일 시스템인 HDFS에 데이터 저장, MapReduce 를 이용하여 데이터처리
- 기존 시스템보다 비용이 적게 듦, 데이터를 분산 저장하여 처리 빠름
- NoSQL
- 일관성보다는 가용성, 확장성
- 비정형 데이터 저장 > 유연한 모델 지원, 분산처리, 병렬처리
- 분석 기술
- text mining
- opinion mining
- social network analysis
- cluster analysis: 기계학습의 방법론 중 하나이나 빅데이터에도 사용.
- 표현
- R
- 통계 계산과 시각화를 위한 언어, 개발 환경 제공
- 다양한 프로그래밍 언어+ 운영체제에서 동작, 분산처리 지원 라이브러리
3. 빅데이터 저장 기술 : NoSQL
관계형, SQL이 아닌 NoSQL (Not only SQL 이라는 뜻!)
- 관계형 DB 대신할 새로운 대안을 필요성
- 대안으로 NoSQL 등장
대량의 비정형 데이터를 저장, 처리하기 위해 ACID 위한 기능은 제공하지 않고, 분산 저장, 처리 가능하도록 함.
- 스키마가 없음(비정형 데이터라) / 구조를 미리 정의 X / 구조를 융통성 있게 바꿈
- 오픈 소스로 제공
✅ Relational DB vs. NoSQL
Relational DB
- 일관성 유지, 외래키, 질의 처리 가능
- 확장성 측면에서 비효율
NoSQL
- 자유롭게 구조를 바꾸면서 비정형 데이터 저장, 처리
- SQL 대신 별도의 기술을 이용한다는 점.
그러나 경쟁자가 아니다! 독립적으로 작업, 독립적인 도메인에서 사용되는 기술.
형태와 목적에 따라 적절한 것을 선택
4. 빅데이터 분석 기술: 데이터 마이닝
분석 기술 중 그 중에서도 기본이 되는 데이터 마이닝을 알아보자.
일반적인 데이터 분석은 데이터에서 정보, 지식을 찾아내기 위해 가공하는 역할을 담당한다.
빅데이터 분석 기술은 기존의 데이터 분석에 + 빅데이터의 특성을 고려한다. (비정형 + 방대한 양!) , 대표적으로 데이터 마이닝, 기계 학습이 있다.
데이터 마이닝과 기계 학습은 어떻게 다른가?
데이터 마이닝은 발견, 기계 학습은 예측에 가깝다!
- 데이터 마이닝
규칙과 패턴을 찾아내는 기술 / 최근에는 데이터 분석까지 영역을 넓힘
classification, cluster, association analysis 가 있다.
