End-to-end Deep Learning Models
Seq2seq 는 종단간 딥러닝의 한 유형이다. 그 이전의 모델들로는..
- NLP 로 처리하기
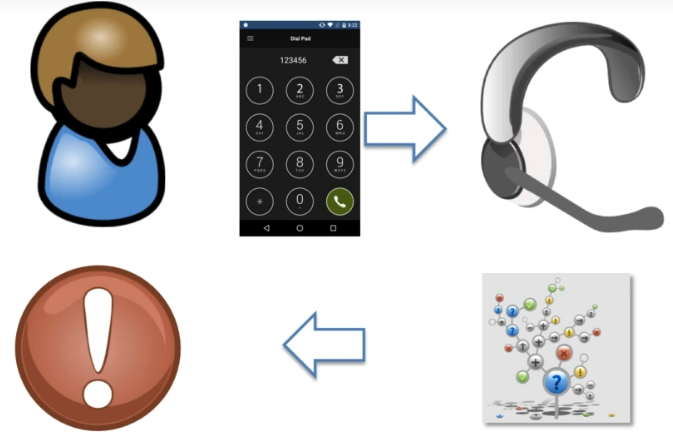
고객이 해당 회사에 관해 문제가 생겨 서비스 센터에 전화를 건다고 해보자. 서비스 센터의 직원은 사람이 아닌 미리 녹음된 음성이다. 어떤 일을 처리해줄지 묻고, 1~5 번을 제시하며 필요한 번호를 누르라고 말한다. 여기에 분류 알고리즘을 더하고 문제를 처리하는 간단한 방식은, 사용자가 처리하고픈 모든 문제를 담아낼 수 없고, 잘못 대답하기 때문에, 문제가 있다.
- 조금 더 DNLP 로 다가간 NLP 로 처리하기
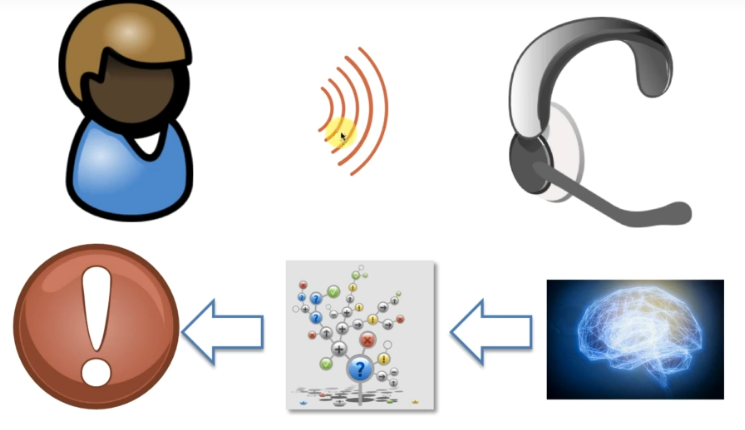
이제 조금더 Deep Learning 을 사용해보자. 이때 사용할 건 음성처리기술이며, 이번엔 번호를 선택하는 것이 아니고 사용자가 어떤 문제가 있는지 말하고 뇌를 닮은 코드로 인식, 분류, 문제를 처리한다. 그러나 여기서 딥러닝을 사용하지 않거나 말을 못알아듣는 경우 문제가 많이 발생한다. 그러나 더 올바른 방향으로 가고 있는 것은 확실하다. (다시 다이얼패드로 돌아온 회사들도 있었지만)
- 딥러닝을 사용, 정확히 무엇을 말하는지 아는 모델
소리를 딥러닝으로 분석하고, 또다시 딥러닝으로 들어온 소리 정보를 텍스트 형식으로 변환하는 딥러닝을 사용하는 것이다. (의미 이해에도 딥러닝 사용) 그리고 답변을 제공하는 것이다. 이건 완전히 DNLP 에 속하는 모델이다. 그러나 문제가 여전히 있다.
문제는 딥러닝 모델을 분리해야 한다는 것이다. 분리 보관에 있어서 문제가 발생하는 것인데, 각각이 연결되지 않고 스스로 훈련을 진행해야 하기 때문이다. (사람이 듣고, 이해하고 말하는 과정을 분리하여 각각 다른 사람이 수행한다고 생각하면 쉽다) 모델이 분리된 것이 문제가 된 것이다!
- 마지막 단계 - 종단간 딥러닝
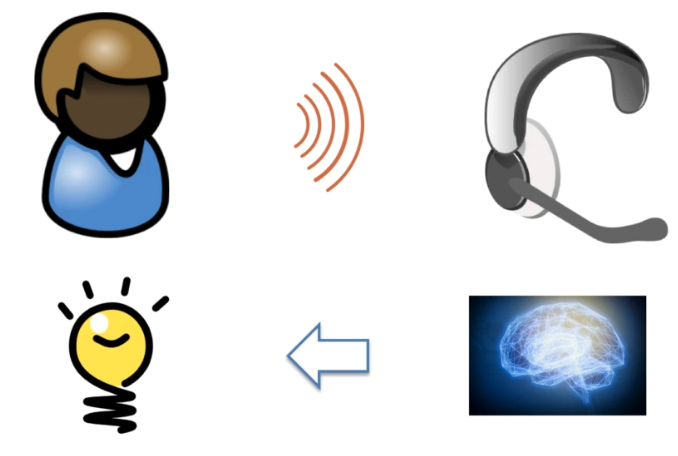
두뇌, 해답만 존재한다. 인간 두뇌 작동 방식과 매우 흡사.
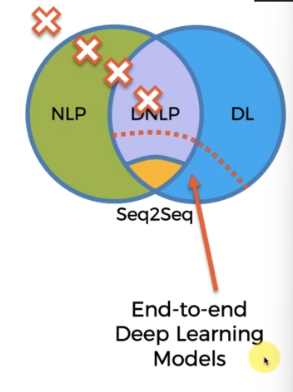
위 그림에서 점선에 해당하는 부분을 뜻하고, 이를 종단간 딥러닝 모델이라 한다. Seq2Seq 는 이 경계에 속하는 것이다. (애매하긴 하지만)
