

OpenAI 의 GPT-4 의 Technical report 를 보자.
🤔 GPT-4 는 멀티모달이다.
GPT-4, a large multimodal model capable of processing image and text inputs and producing text outputs
텍스트 입력 - 텍스트 생성의 기존 GPT 와 다르게, 이미지 입력이 가능한 멀티모달을 강조했다.
- transformer 스타일 모델, 학습은 문장의 다음 토큰을 예측하는 방식으로 학습
- fine-tuning 은 Reinforcement Learning from Human Feedback (RLHF) 으로.
RLHF 란 생성된 텍스트를 사람이 피드백, 강화학습을 통해 모델 파라미터를 조절하는 것이다. - 모델 구조, 하드웨어, 데이터셋 구성, 학습 방법은 공개하지 않음
GPT-4 scaling
모델 크기와 학습 데이터가 커질수록 모델의 성능은 좋아지고, 학습 데이터가 작아질수록 모델의 성능은 나빠진다. (학습 데이터셋의 크기와 모델 손실의 그래프)
-
다음과 같이 우하향하는 지수함수이다!
-
GPT-3 에서 파라미터는 1750억, GPT-4는 그보다 많을 것이지만 공개하지 않았다.
-
따라서 튜닝을 한 번 하려면 시간, 비용이 굉장히 많이 듬
-
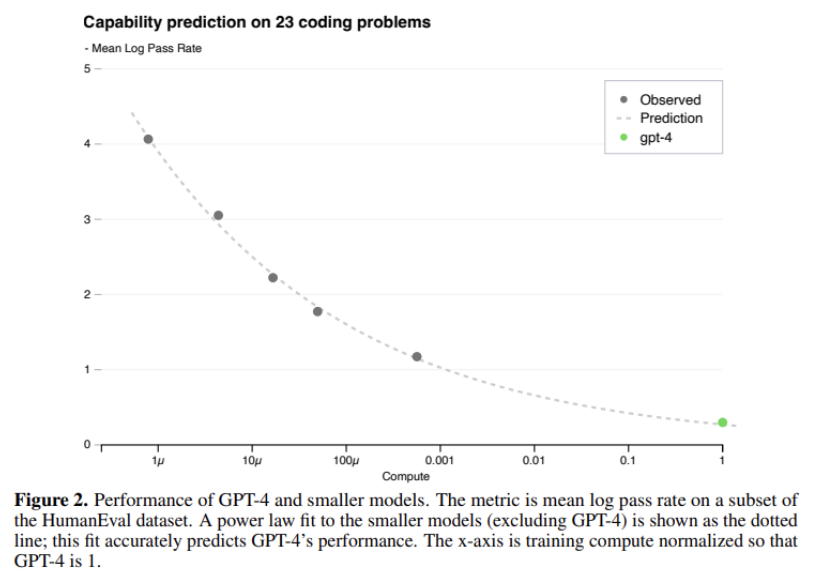
scaling 이 잘 되는 모델 구현. (작은 모델의 성능 데이터로 GPT-4 성능 정확하게 예측)
작은 모델의 손실 값으로부터 GPT-4 의 성능을 에측. (위의 그래프가 그것을 표현한 것이다.)
GPT-4 의 성능
-
GPT-4 의 중요한 목표 중 하나는 더 복잡한 상황에서 텍스트 이해와 선택
-
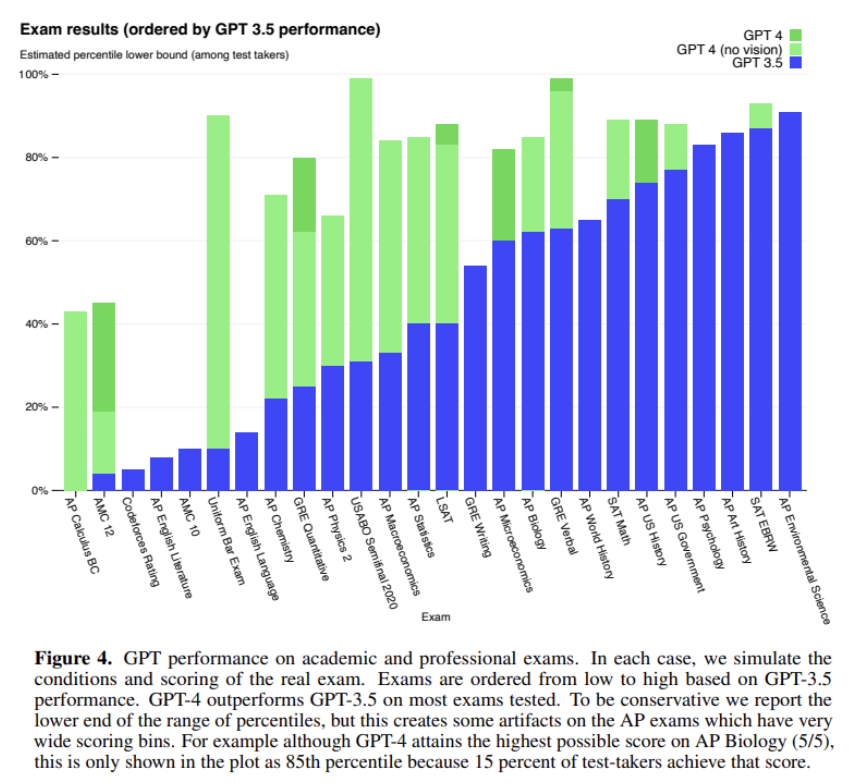
성능 테스트를 위해 선택한 방법은 사람을 위해 만들어진 시험 문제를 풀게 하는 것.
-
객관식과 주관식 모두 포함, 이미지도 input 으로 줌.
-
사람과 이미 비슷한 점수를 얻음.
-
미국 변호사 시험에서 상위 10%
-
시험문제를 푸는 능력은 파라미터 조절보다도 훈련 자체에서 비롯되었을 거라 예상
-
여러 benchmark 데이터 이용, base GPT-4 의 성능 평가 진행.
-
텍스트와 이미지 혼합된 프롬프트도 처리 가능
GPT-4 의 한계
- hallucination 환강 현상
- 주어진 프롬프트를 바탕으로 확률 기반 문장을 생성할 뿐, 이게 맞는 말인지 검증하지는 못함.
- GPT-4 에는 이러한 환각 현상이 많이 줄어들었다고 함. (여전히 확률기반임.)
- 2021년 9월 이후의 정보는 알지 못함.
위험성

'전문지식이 있다면 위험한 답변을 줄 수 있는 프롬프트'를 구별.
- RLHF 학습에 안정성과 관련된 더 많은 프롬프트 포함.
- Rule-Based Reward Model 기법 도입
- 여러 개의 zero-shot GPT-4 분류기로 구성, 무해한 내용을 걸러내지 않았을 때 Policy model 에 reward signal 을 제공.
- 이후 사람이 만든 평가 지표까지 합쳐 답변에 적절하지 않은 내용이 포함되면 거절 답변 생성.
- RealToxicityPrompts 데이터셋으로 실험한 결과 GPT-4는 0.73%의 경우에서만 적절하지 않은 텍스트를 생성
