01 데이터 클리닝 : 완결성
완결성은 결측값이 없는 상태 와 동일하다고 볼 수 있겠다. 다음 데이터는 완결적이지 못하다.
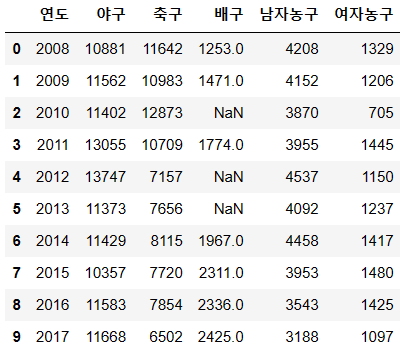
데이터프레임의 NaN 이라고 표시되어 있는 것은 값에 치명적인 영향을 준다. 특히나 평균에 영향을 많이 주므로 꼭 처리해야 하는데, 데이터 프레임에서 어떻게 이러한 null 값이 있는 것을 알까?
df.isnull() 을 이용한다.
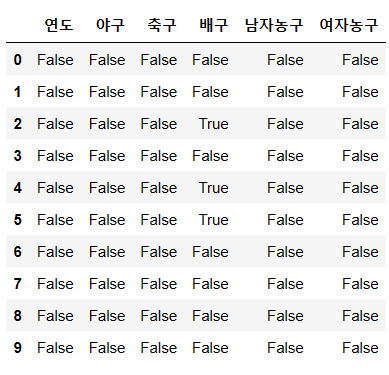
다음과 같이 출력이 된 것인데, 값이 없을때만 True 로 표기가 된다. 그러나 보기가 좀 어렵다. 더해보자.
df.isnull().sum()

배구에만 null 값이 3개 존재한다는 것을 좀 더 쉽게 알았다.
02 데이터 클리닝 : 완결성 (2)
완결성을 만족하기 위해 처리하는 방법은 크게 두 가지이며, 세부적으로 또 쪼갤 수 있다. 크게 지우기 와 채우기 가 있다.
✅ 1-1 빈 값이 포함된 row 지우기
첫번째로는 row 를 지우는 것이다. 결측값이 있는 row 를 통째로 지우는 코드는 다음과 같다.
df.dropna()
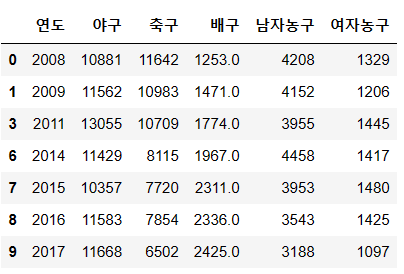
결측값이 있던 2010, 2012, 2013 의 정보가 지워지면서 배구 뿐 아니라 다른 종목의 row 들도 함께 삭제되었다.
✅ 1-2 빈 값이 포함된 column 지우기
두번째로는 column 을 지우는 것이다. 아예 배구 컬럼을 프레임에서 삭제하는 것이다.
df.dropna(axis = 'columns')
결측값이 포함된 열을 아예 삭제한다. 다음과 같은 결과가 나온다.
✅ 2-1 빈 값이 포함된 값 0으로 채우기
열이나 행을 지우지 않고 채우는 방법도 있다. 0으로 채우고 싶다면, 코드는 다음과 같다.
df.fillna(0)
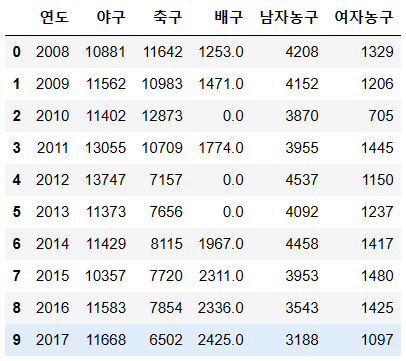
✅ 2-2 빈 값이 포함된 곳에 0이 아닌 다른 의미있는 값으로 채우기
평균이나 중앙값 등으로 채우고 싶다.
df.fillna(df.mean())
df.fillna(df.median())
기억해야 될 것은 df.mean() 의 평균은 결측값이 발생한 그 컬럼의 평균 을 집어넣는 것임을 알아두자. 똑똑하게 알아서 잘 넣는다는 것이다! 평균으로 채운 결과를 보자.
03 스팀 게임 데이터 정리하기
import pandas as pd
df = pd.read_csv('data/steam_1.csv')
# 여기에 코드를 작성하세요
df.dropna(inplace = True)
# 테스트 코드
df04 데이터 클리닝: 유일성 처리
데이터의 행과 열을 유일한 값으로 유지해야 하는 것도 중요한 문제이다.
아까 전엔 빈 값 을 어떻게 지우고 채우냐 하는 문제였다면,
지금은 중복되는 값 에 대한 처리인데, 당연히 중복되는 값은 지우기만 해야 할 것이다.
✅ 중복되는 행 지우기
행은 row 이자 index 이므로 다음과 같이 확인할 수 있다.
df.index.value_counts()
07월 31일의 행이 두 개다. 지우는 코드는 다음과 같다.
df.drop_duplicates(inplace = True)
07월 31이 하나만 남은 것을 확인할 수 있었다.
✅ 중복되는 열 지우기
열을 지우는 메서드는 따로 존재하지 않는다. 따라서 열을 잠깐 행으로 가져와서 지우고, 다시 열로 옮겨놔야 한다. 이때 .T 메서드를 사용한다. 열을 지우는 메서드는 다음과 같다.
df = df.T.drop_duplicates().T
여기서는 inplace 메서드가 동작되지 않아 새로운 변수에 할당했다. 확인해보니 중복되는 열 역시 지워져 있었는데, 열 이름이 완전히 같지 않아도 해당 열에 모든 값이 같으면 삭제시켰다.
05 데이터 클리닝 : 정확성 (1)
정확성은 이상점에 대한 처리 를 다룰 수 있다.
outlier 는 pandas 의 box plot 에서 기준으로,
IQR 이 위로 1.5 IQR, 아래로 1.5 IQR 멀리 벗어나 있으면 이상점이라 간주한다.
이상점에 대한 처리는 어떻게 할까?
이상점이 잘못 조사된 데이터라면 삭제하거나 고쳐주면 되지만,
잘못 조사되지 않았는데 이상점이라면 특별한 인사이트를 가져다 줄 수 있으므로 놔두는 방법도 있다.
06 데이터 클리닝 : 정확성 (2)
이상점을 확인하는 condition 은 다음과 같다.
q1 = df['abv'].quantile(0.25)
q3 = df['abv'].quantile(0.75)
iqr = q3 - q1
condition = (df['abv'] < q1 -1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)
'abv' 는 이상점이 있는 컬럼을 말한다. condition 을 보면, 행에서 iqr 에서 1.5 배 떨어진 값으로 잘 찾을 수 있다. | 은 또는 이라는 의미이다. quantile() 통해 그 분위수에서의 값을 알 수 있다.
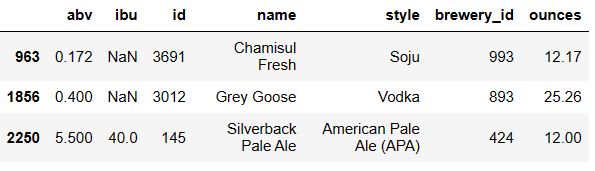
현재 의심중인 값은 세 개인데, 마지막 값은 고치고, 1,2 번째 값은 없애보자.
df.loc[2250, 'abv'] = 0.055
condition = (df['abv'] < q1 -1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)
df[condition]고치기를 먼저 하고 확인하면 더이상 3번째 값은 확인되지 않는다. 마지막으로 없애기다.
df.drop(df[condition].index, inplace = True)필터링한 값에 인덱스를 붙이고, 그것을 drop 해주기만 하면 된다.
07 데이터 클리닝 : 정확성 (3)
이상점엔 관계적 이상점이란 것도 존재한다. (relational outlier)
예컨대 수학 읽기 점수와 쓰기 점수가 매우 많이 차이가 나는 것을 뜻한다. 이를 condition 으로 잡아내보고 없애보자.
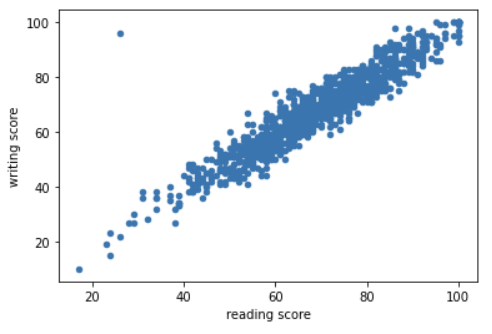
읽기 점수는 40 점이 안되는데, 쓰기 점수만 80점이 넘어가는 이상점이다. 코드로 잡아내자.
condition = (df['reading score'] < 40) & (df['writing score'] > 80)
df[condition] 잘 잡아냈다면, 인덱스 번호를 보고 drop 해버리자.
df.drop(373, inplace = True)df.plot(kind = 'scatter', x = 'reading score', y = 'writing score')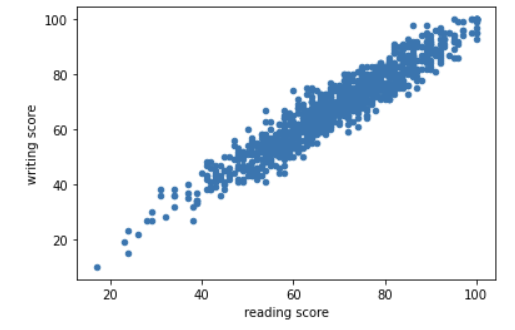
이상점을 제거하는 데 성공했다.
08 영화 평점 분석하기 1
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/movie_metadata.csv')
# 여기에 코드를 작성하세요
q3 = df['budget'].quantile(0.75)
q1 = df['budget'].quantile(0.25)
iqr = q3 - q1
condition = (df['budget'] > q3 + 5 * iqr)
df.drop(df[condition].index, inplace = True)
df.plot(kind = 'scatter', x = 'budget', y = 'imdb_score')인덱스를 찍어주는 코드에서 약간 실수가 있었다. 처음에는 df.drop(condition.index) 라 했는데, 이렇게 하면 데이터프레임이 찍이지 않으므로 의미가 없다. 따라서 프레임 안에서 인덱스를 찍어줘야 하고, [ ] 안에 넣어줘야 한다.
09 영화 평점 분석하기 2
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/movie_metadata.csv')
# 여기에 코드를 작성하세요
df_index = df['budget'].sort_values(ascending = False).head(15).index
df.drop(df_index, inplace = True)
df.plot(kind = 'scatter', x = 'budget', y = 'imdb_score')아직 코드 작성이 익숙하지 않아서인지 치면서 자잘한 오류가 너무 많이 난다.. 내일은 여기부터 다시 시작해야겠다.
하나 알아간 것은
.head() 나
.index 가 저렇게 끝에 올 수 있다는 것이다.
헤드가 올 경우 상위 단어를 몇 개 출력할 지 지정할 수 있고, 인덱스는 그 단어들의 인덱스만 받아올 수 있다. 조심해야 할 것은 sort_values 하더라도 본래 데이터 값이 변하는 아니라서 index 를 찍어온다는 점이다.
