1. 머신러닝이란?
머신러닝은 데이터에서부터 학습하도록 컴퓨터를 프로그래밍하는 과학이다.
어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P라 할 때, 경험 E 로 인해 성능이 향상되었다면, 컴퓨터 프로그램은 작업 T와 성능 P에 대해 경험 E로 학습한 것이다.
훈련 세트: 학습 시 사용하는 샘플
훈련 사례: 훈련 데이터 (샘플)
스팸 필터를 구현한다고 했을 때, 작업 T 는 스팸인지 구분하는 것, 경험 E는 훈련 데이터, 성능 P는 직접 정의(정확히 분류된 메일의 비율, 정확도)
1.2 왜 머신러닝을 사용하는가?
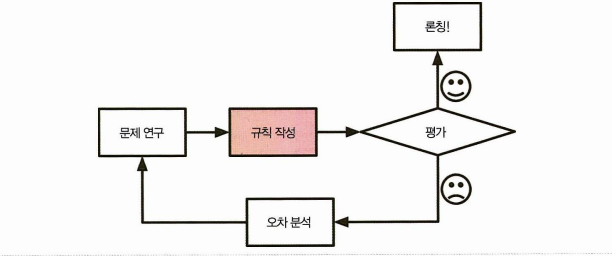
전통적인 접근 방법이다.
머신러닝을 사용하면 필터가 스팸의 패턴을 감지하여 기준을 자동으로 학습한다.
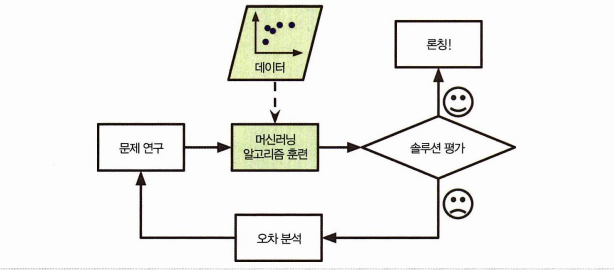
- 유지 보수가 쉽고 정확도가 더 높아진다
- 자동으로 변화에 적응한다 (새로운 데이터에 적응)
- 머신러닝을 통해 배울 수 있다 (필터가 학습한 기준을 확인할 수 있다) : 데이터마이닝!
1.3 애플리케이션 사례
- CNN 을 이용한 이미지 분류
- RNN, CNN ,Transformer 을 이용한 자연어처리
- linear regression, polynomial regression, SVM, random forest, ANN 등을 이용한 다양한 예측
- 차원 축소를 이용해 고차원의 복잡한 데이터셋을 그래프로 표현하기
- 강화학습을 이용해 게임 봇 만들기
1.4 머신러닝 시스템의 종류
✅ 지도, 비지도, 준지도, 강화 학습
✅ 온라인 학습과 배치 학습
✅ 사례 기반 학습과 모델 기반 학습
1.4.1 지도 학습과 비지도 학습
지도와 비지도는 학습하는 공안의 감독 형태나 정보량에 따라 분류한다.
지도, 비지도, 준지도, 강화학습의 네 가지 범주가 있다.
지도 학습
알고리즘에 주입하는 훈련 데이터에 레이블이라는 원하는 값을 준다.
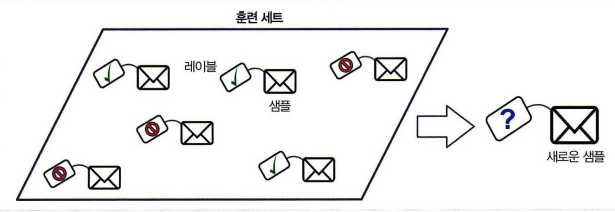
위와 같이 샘플에 레이블을 달아놓고, 새로운 샘플에 대한 예측을 진행하는 것이다.
- 분류에 많이 사용된다.
- 예측변수(특성)을 사용해 타깃 수치를 예측한다 : 회귀
- 일부 회귀 알고리즘이 분류에 사용될 수도, 분류 알고리즘을 회귀에 사용할 수도 있다. (연관이 깊다!)
중요한 지도 학습 알고리즘들 🔽
- k-최근접 이웃
- 선형 회귀
- 로지스틱 회귀
- SVM
- 결정 트리, 랜덤 포레스트
- 신경망
비지도 학습
훈련 데이터에 레이블 없이 학습하는 것을 비지도 학습이라 한다.
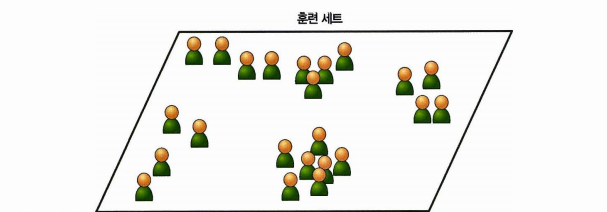
중요한 비지도 학습 알고리즘들 🔽
- 군집 (k평균, DBSCAN, HCA)
- 이상치 탐지와 특이치 탐지 (원-클래스, 아이솔레이션 포레스트)
- 시각화, 차원축소 (PCA, 커널 PCA, LLE, t-SNE)
- 연관 규칙 학습 (어프라이어리, 이클렛)
계층 군집 알고리즘을 사용하면 각 그룹을 작은 그룹으로 세분화 할 수 있다.
시각화를 통해 데이터 조직과 예상치 못한 패턴을 발견한다
차원축소는 정보를 유지하면서 데이를 간소화 하는 것이다. (상관관계가 있는 특성을 하나로 합친다, 특성추출)
이상치탐지는 알고리즘을 학습시키기 전에 데이터셋에서 이상한 값을 자동으로 제거하는 것이다.
특이치탐지는 훈련 세트에 있는 모든 샘플과 달라 보이는 새로운 샘플을 탐지한다. (훈련 세트에 들어있으면 탐지하지 않는다)
연관 규칙 학습은 대량의 데이터에서 특성 간의 관계를 찾는 것이다.
준지도 학습*
일부만 레이블이 있는 데이터를 준지도 학습이라고 한다.
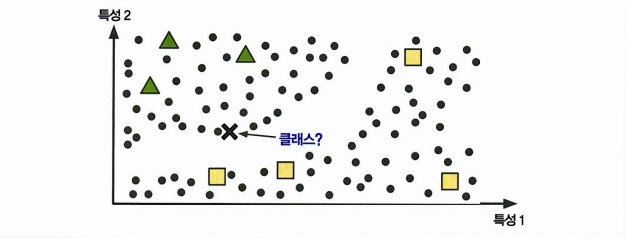
사진과 같은 경우 레이블이 있는 사각형 클래스에 X가 가깝지만 오히려 레이블이 없는 샘플 원이 샘플을 삼각형으로 분류하는데 도움을 준다.
지도 학습과 비지도 학습의 조합으로 이루어져 있으며, 심층 신뢰 신경망 DBN 은 여러 겹으로 쌓은 제한된 볼트만 머신이라 불리는 비지도 학습에 기초한다.
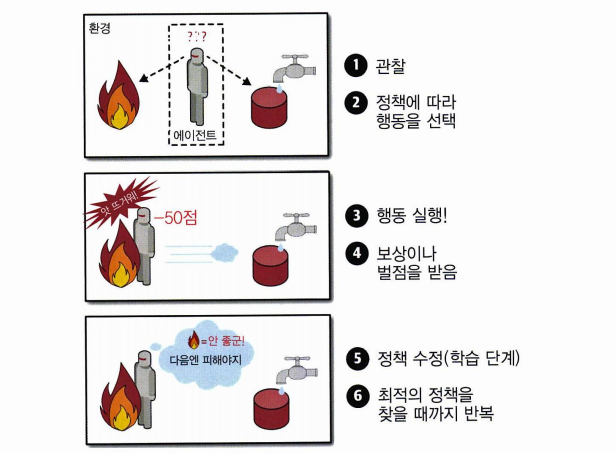
강화학습
학습하는 시스템을 에이전트라 한다. 환경을 관찰해서 행동하고, 결과로 보상을 받는다. 보상을 얻기위해 정책이라고 부르는 최상의 전략을 스스로 학습하는 것이 강화학습이다.
1.4.2 배치 학습과 온라인 학습
또 다른 기준은 입력데이터의 스트림으로부터 점진적으로 학습할 수 있는지 여부이다.
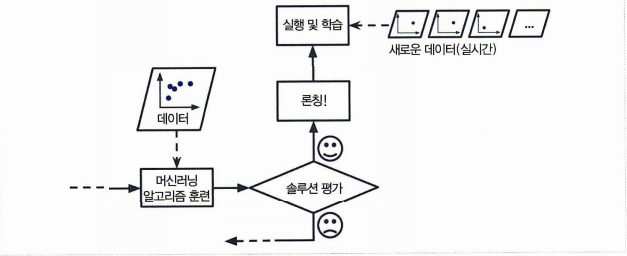
배치 학습(오프라인 학습)
배치 학습은 시스템이 점진적으로 학습할 수 없다. 가용한 데이터를 모두 사용해 룬련 시켜야 하고, 제품에 적용하면 더이상의 학습은 없으므로 오프라인 학습이라 한다. (학습이나 실행 모두 오프라인에서 한다.)
- 새로운 데이터에 대해 학습하려면 시스템의 새로운 버전을 처음부터 다시 훈련해야 한다.
- 전체 데이터셋을 사용해 훈련하는데 몇 시간이 걸린다.
- 많은 컴퓨팅 자원이 필요!
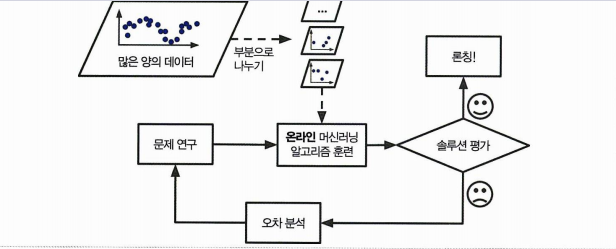
온라인 학습
온라인 학습은 데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 훈련시킨다. 데이터가 도악하는 대로 즉시 학습할 수 있다.
- 론칭 뒤에도 새로운 데이터에 대해 학습한다
- 빠른 변화에 적응해야 하는 시스템에 적합
- 메인 메모리에 들어갈 수 없느 큰 데이터셋을 학습하는 시스템에도 사용가능 (외부메모리 학습)
학습률 : 온라인 학습 시스템에서 변화하는 데이터에 대해 얼마나 빠르게 적응할 것인지를 나타내는 파라미터.
- 높게 하면 데이터에 빠르게 적응, 잊어버리는 것도 많음.
- 학습률이 낮으면 (시스템 관성이 커져) 느리게 학습
- 나쁜 데이터 주입시 성능이 점진적으로 감소
1.4.3 사례 기반 학습과 모델 기반 학습
어떻게 일반화 되는가에 따른 분류이다. 이때 일반화란 학습 과정을 거치고 새로운 데이터에 대해 좋은 예측을 만드는 과정을 뜻한다.
일반화를 위한 두 가지 접근법이다!
사례 기반 학습
단순히 기억하는 학습! 추가적으로 유사도 측정을 사용해 새로운 데이터와 학습한 샘플을 비교할 수 있다.
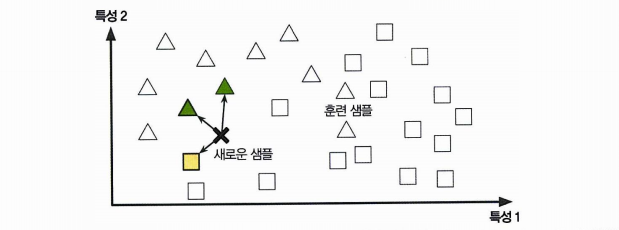
사용자가 스팸이라고 지정한 메일과 동일한 모든 메일을 스팸이라 분류하는 것이다.
- 메일 사이의 유사도 측정이 필요
- 공통으로 포함한 단어의 수를 센다.
- 비슷하다고 분류된 샘플의 클래스를 보고 따라간다.
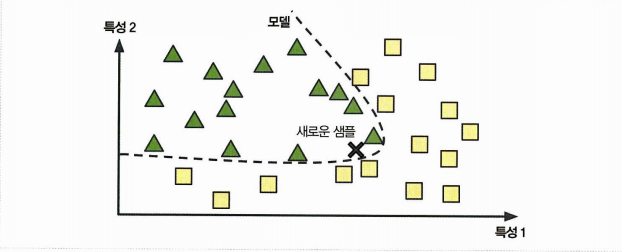
모델 기반 학습
샘플들의 모델을 만들어 예측에 사용하는 것!
다음과 같은 GDP 에 따른 삶의 만족도 그래프를 보자.
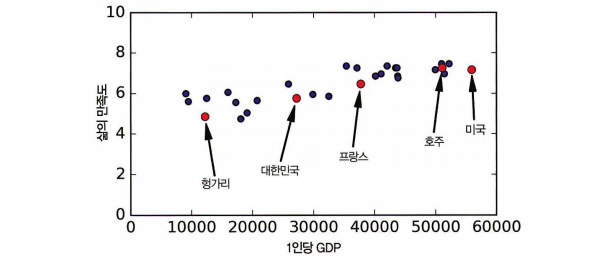
이러한 흩어진 데이터를 보고 모델을 선택하는 것이 모델 기반 학습이다. 여기선 GDP 가 증가할 수록 리니어하게 만족도도 증가하는 선형 모델을 선택할 수 있다.
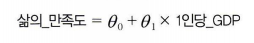
- 모델 파라미터 : 두 세타
- 효용 함수 : 모델이 얼마나 좋은지 정의
- 비용함수 : 모델이 얼마나 나쁜지 정의 (모델의 예측 - 훈련 데이터)
결국 이 거리의 비용함수를 최소화하는 것이 목표! - 훈련 : 알고리즘에 훈련 데이터를 공급하면 데이터에 가장 잘 맞는 선형 모델의 파라미터를 찾는 것.
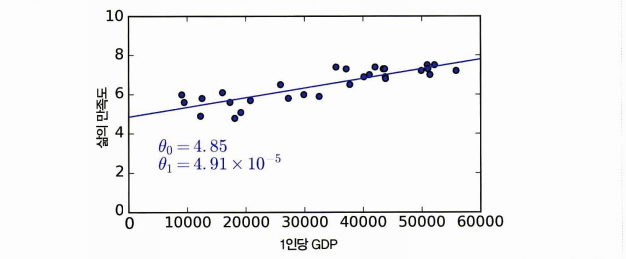
데이터셋에 맞는 비용을 최소화하는 모델을 훈련을 통해 찾았다고 할 수 있다. 이제 모델을 사용해 예측을 수행할 수 있다.
# 예제 코드
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn.linear_model
# 데이터 적재
oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# 데이터 준비
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# 데이터 시각화
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# 선형 모델 선택
model = sklearn.linear_model.LinearRegression()
# 모델 훈련
model.fit(X, y)
# 키프로스에 대한 예측
X_new = [[22587]] # 키프로스 1인당 GDP
print(model.predict(X_new)) # 출력 [[ 5.96242338]]만약 k- 최근접 이웃 모델을 사용하고 싶다면 두 줄만 바꾸면 된다.
import sklearn.linear_model
model = sklearn.linear_model.LinearRegression
import sklearn.neighbors
model = sklearn.neighbors.KNeighborsRegressor(n_neighbors = 3) 머신러닝 프로젝트 형태 🔽
- 데이터 분석
- 모델 선택
- 모델 훈련(파라미터 찾기)
- 모델 적용, 예측(추론)
1.5 머신러닝 주요 도전 과제
나쁜 데이터, 나쁜 알고리즘?
나쁜 데이터의 예🔽
1.5.1 충분하지 않은 양의 훈련 데이터
아주 간단한 문제에서조차 수천 개의 데이터가 필요.
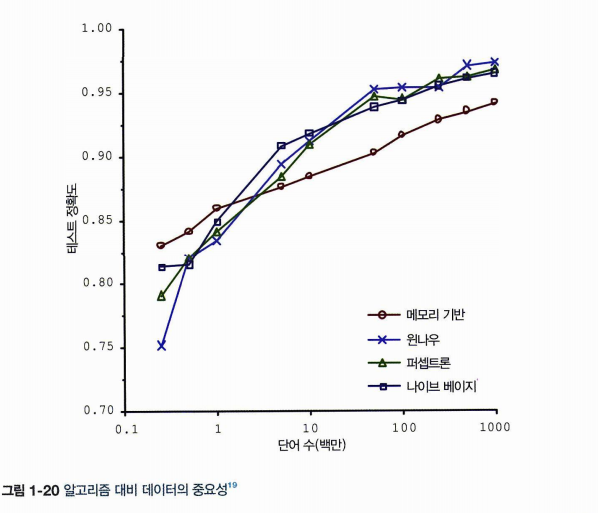
어느정도 충분한 데이터셋이 확보되어야 테스트 정확도를 높일 수 있다.
1.5.2 대표성 없는 훈련 데이터
새로운 사례가 들어왔을 때 훈련 데이터가 이를 충분히 대표할만 해야한다. 샘플이 작으면 샘플링 노이즈가 생기고, 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수 있다. (샘플링 편향)
1.5.3 낮은 품질의 데이터
훈련 데이터가 에러, 이상치, 잡음으로 가득한 경우.
- 정제에 시간 투자 필요
- 이상치가 명확할 땐 무시하거나 수동으로 고치는 작업
- 샘플에 특성 몇 개가 빠져있다면 특성을 모두 무시할지, 샘플을 무시할지, 빠진 값을 채울지, 따로 훈련시킬 지 결정.
1.5.4 관련 엇는 특성
FE: 훈련에 사용할 좋은 특성들을 찾는 것.
feature selection : 특성 중 가장 유용한 특성들만 선택.
feature extraction : 특성을 결합하여 유용한 특성 만들기
나쁜 알고리즘의 예🔽
1.5.5 훈련 데이터 과대적합
과대적합, 오버피팅이란 모델이 훈련 데이터에만 너무 잘 맞고 일반성이 떨어지는 거을 뜻한다.
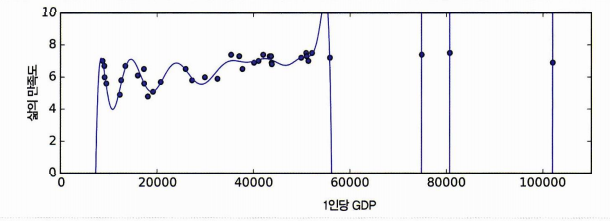
오버피팅을 해결 방법은 다음과 같다.
- 파라미터 수가 적은 모델 선택, 특성 수 줄이기, 모델 제약 가하기
- 훈련 데이터 양 증가
- 훈련 데이터 잡음 제거
규제: 오버피팅의 위험을 감소시키기 위해 모델에 제약을 가하는 것.
파라미터 세타는 자유도를 학습 알고리즘에 부여한다. 세타가 두 개일 때, 하나를 0으로 고정시킨다면 한 개의 자유도만 남고 데이터에 적절하게 맞춰지기 힘들다.
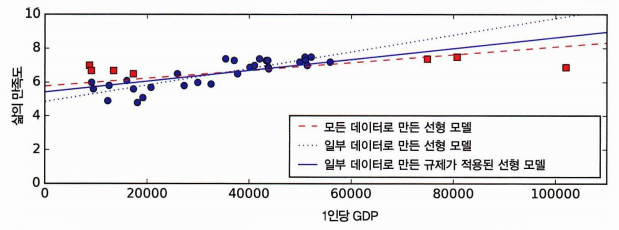
따라서 세타1을 작은 값으로 유지시키면 자유도를 적절히 조절하면서 오버피팅도 방지할 수 있다.
하이퍼파라미터: 학습 시 적용할 규제의 양. 값이 커질수록 거의 평편한 모델, 과적합은 방지할 수 있으나 좋은 모델을 찾지 못한다.
1.5.6 과소적합.
과대적합의 반대의 경우이다.
- 모델 파라피터 개수 늘리기
- 더 좋은 특성 제공
- 모델 제약 줄이기 (하이퍼파라미터 감소)
1.6 테스트와 검증
중요한 방법 중 하나가 훈련 데이터를 훈련 세트와 테스트 세트로 분리하는 것이다. 왜? 새로운 샘플에 대해 얼마나 잘 동작하는지 알기 위해서!
이때 새로운 샘플에 대한 오류 비율을 일반화 오차(외부샘플오차) 라 한다.
1.6.1 하이퍼파라미터 튜닝, 모델 선택
모델과 하이퍼파라미터가 테스트 세트에만 최적화된 모델(새로운 데이터 X)을 만들었다면 어떻게 해야할까?
홀드아웃 검증을 통해 해결한다! 훈련 세트의 일부를 떼어내어(검증 세트) 여러 후보 모델을 평가하고 가장 좋은 하나를 선택하는 것이다.
전체 훈련 세트 = 훈련 세트 + 검증 세트
- 훈련 세트에서 다양한 하이퍼 파라미터 값으로 여러 모델을 훈련시킨 후,
- 검증 세트에서 가장 높은 성능을 내는 모델을 선택
- 전체 훈련 세트에서 다시 훈련, 최종 모델 완성
- 테스트 세트에서 평가.
- 일반화 오차 추정
검증 세트가 너무 작거나 클 경우 문제가 발생, 교차 검증으로 해결할 수 있다. 교차 검증: 작은 검증 세트를 여러 개를 사용해 반복적으로 검증 세트 역할 부여.
데이터 불일치
