2.5 머신러닝 알고리즘을 위한 데이터 준비
strat_train_set 의 median_house_value 는 여기서 label 역할을 하는 목표변수이다. 따라서 housing 훈련세트에는 이를 제외하고, housing_labels 에는 이것만 가져오면 된다.
housing = strat_train_set.drop("median_house_value", axis=1) # 훈련 세트를 위해 레이블 삭제
housing_labels = strat_train_set["median_house_value"].copy()2.5.1 데이터 정제
앞서 다른 값은 아니었으나 total_bedrooms 에 행 개수에 맞지 않는 수의 값이 들어있었다. 이를 채워넣는 방법은
- 해당 행 삭제
- 해당 열 삭제
- 어떤 값으로 채우기
housing.dropna(subset=["total_bedrooms"]) # 옵션 1
housing.drop("total_bedrooms", axis=1) # 옵션 2
median = housing["total_bedrooms"].median() # 옵션 3
housing["total_bedrooms"].fillna(median, inplace=True)다음과 같은 옵션이 있다. 참고로 subset 은 어떤 열을 탐색할지 적어주는 것이다. 리스트 안에 있는 NaN 만 탐색하여 발견이 된다면 해당 열을 삭제하는 식이다.
- SimpleImputer
사이킷런의 SimpleImputer 을 이용하는 방법도 있다. 누락된 값을 중간값으로 대체하고 싶다고 가정하자.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")imputer 객체를 만들 때 파라미터로 strategy = median 을 넣어준다. 중간값으로 넣으라는 말이다.
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
imputer.statistics_ocean_proximity 는 숫자형 피처가 아니므로 삭제해주고 나머지 정보를 housing_num 에 넣고 훈련시켰다. 이제 imputer 객체엔 다음과 같은 정보가 들어있다.

훈련된 imputer 를 hosing_num 의 빈 값에 전달한다. 그 다음 데이터 프레임을 만든다. 코드는 다음과 같다.
X = imputer.transform(housing_num)
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing_num.index)성공적으로 housing_tr 에 중간값으로 정보가 들어간 것을 확인할 수 있다.
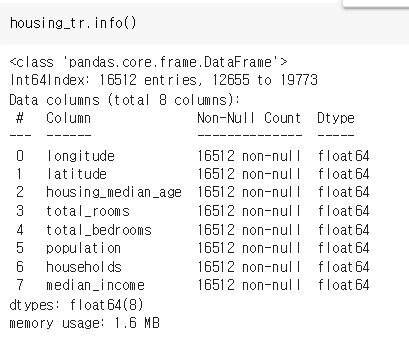
(빈 값이 433으로 바뀌었을 것)
2.5.2 텍스트와 범주형 특성 다루기
또다른 중요한 포인트는 숫자형이 아닌 범주형 피처들을 다루는 것이다. 범주형 특성을 처리하는 방법에 대해 알아보자. 이 데이터 세트에서 범주형 특성은 ocean_proximity 이다.
먼저 ocean_proximity 만 담아 housing_cat 데이터세트를 만들어보자.
housing_cat = housing[["ocean_proximity"]]
housing_cat.head(10)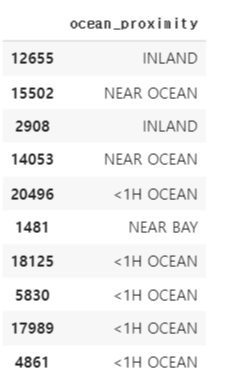
이 카테고리를 텍스트에서 숫자로 변환하려면 두 가지 방법이 있다.
✅ OrdinalEncoder 클래스
#사이킷런에서 OrdinalEncoder 가져오기
from sklearn.preprocessing import OrdinalEncoder
#ordinal_encoder 객체 생성
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) #.fit_trainsform 을 이용하면 인코딩 된 데이터세트를 완성할 수 있다.
housing_cat_encoded[:10] # 10개 출력
✅ OneHotEncoder 클래스
위 OrdinalEncoder 와 다르게 0과1로만 인코딩을 수행하는 것이다. 이 데이터 세트에선 '<1HOCEN' 이면 1이 되고 'INLAND' 이면 0이 되는 식이다.
#사이킷런에서 OneHotEncoder 가져오기
from sklearn.preprocessing import OneHotEncoder
# cat_encoder 객체 생성
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat) # 역시나 fit_transform 이용
housing_cat_1hot.toarray() # 다음과 같이 출력
2.5.3 나만의 변환기
- 특별한 정제 작업을 위해 나만의 변환기를 만들 수도 있음
- fit(), transform(), fit_transform() 을 이용하자.
2.5.4 특성 스케일링
머신러닝 알고리즘을 돌리는데 여러 특성들의 스케일이 많이 다르면 잘 동작하지 않는다. 예컨대 방 개수는 6에서 39320 까지 범위인 반면 중간 소득은 0에서 15까지이다.
✅ 정규화 (min-max 스케일링)
- (해당 데이터 - 최솟값) / (최대 - 최소) 로 계산
- 사이킷런에선 MinMaxScaler 변환기 제공
- feature_range 매개변수로 0-1 이 아닌 다른 범위를 지정할 수도
✅ 표준화
- (데이터 - 평균) / 표준편차
- 분포의 분산이 1이 되도록 함
- 범위에 상한과 하한이 없어 문제가 되지만 이상치에 영향을 덜 받는다.
- 사이킷런의 StandardScaler 이용
2.5.5 변환 파이프라인
✅ 숫자 특성만 처리하는 파이프라인
# 연속된 변환을 순차 처리하게 도와주는 Pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# SimpleImputer, CombineAttributeAdder, StandardScaler 사용
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
# fit_transform
housing_num_tr = num_pipeline.fit_transform(housing_num)- 마지막 단계에는 변환기와 추정기를 모두 사용할 수 있고 그 외에는 모두 변환기어야 함
- 모든 변환기의 fit_transform 메서드를 순서대로 호출하면서 한 단계의 출력을 다음 단게로 전달
- 파이프라인 객체는 마지막 추정기와 동일한 메서드 지원. (StandardScaler 의 메서드 fit_transform)
✅ 숫자 아닌 특성도 함께 처리하는 파이프라인
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs), #이름, 변환기, 변환기 적용 열
("cat", OneHotEncoder(), cat_attribs), #이름, 변환기, 변환기 적용 열
])
housing_prepared = full_pipeline.fit_transform(housing)숫자 아닌 특성을 함께 처리하려면 ColumnTransformer 와 그 객체가 필요하다.
- 객체는 튜플의 리스트를 받음
- 각 튜플은 이름, 변환기, 변환기가 적용될 열 이름으로 구성
- num_pipeline 은 밀집행렬, OneHotEncoder 은 희소행렬을 반환하고, 최종 행렬의 밀집 정도를 추정
- 밀집도가 임곗값(기본 0.3)보다 높으면 밀집 행렬 반환.
2.6 모델 선택과 훈련
2.6.1 훈련 세트에서 훈련하고 평가하기
✅ 선형 회귀 모델 훈련시키기
fit(훈련 세트, 라벨) 을 넣어준다.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)✅ 예측하기
진짜 프로젝트가 아니므로 5개씩만 가져오자.
# 훈련 샘플 몇 개를 사용해 전체 파이프라인을 적용해 보겠습니다
some_data = housing.iloc[:5] #입력변수
some_labels = housing_labels.iloc[:5] #목표변수
some_data_prepared = full_pipeline.transform(some_data) #입력 훈련 세트로 훈련
print("예측:", lin_reg.predict(some_data_prepared))
print("레이블:", list(some_labels))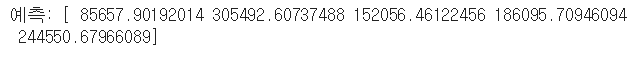

꽤나 많이 어긋났지만 정상적으로 동작은 한다!
✅ 평가하기
MSE 를 사용하여 평가를 진행하자. 전체 훈련 세트에 대한 RMSE 이다.
#MSE 임포트
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared) #전체 훈련 세트
lin_mse = mean_squared_error(housing_labels, housing_predictions) #라벨과 예측 오차
lin_rmse = np.sqrt(lin_mse) #루트 구해줌
lin_rmse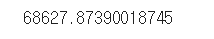
✅ 결정 트리 훈련 시키기
모델만 조금 바꿔보자!
#DecisionTree 임포트
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42) #객체 생성
tree_reg.fit(housing_prepared, housing_labels) #전체 훈련세트, 라벨로 훈련
housing_predictions = tree_reg.predict(housing_prepared) #예측수행
tree_mse = mean_squared_error(housing_labels, housing_predictions) #라벨과 예측 오차
tree_rmse = np.sqrt(tree_mse)2.6.2 교차 검증을 사용한 평가
훈련세트를 훈련세트와 검증세트로 나누고, 하나로 훈련시키고 다른 하나로 평가하는 방법이 있다.
이러한 방법의 대안으로 k-겹 교차검증을 사용할 수도 있다.
폴드라 불리는 서브셋으로 훈련세트를 무작위 분할한다. 결정 트리 모델을 k번 훈련하고 평가하며, 10개의 평가 점수가 담긴 배열이 결과가 된다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)def display_scores(scores):
print("점수:", scores)
print("평균:", scores.mean())
print("표준 편차:", scores.std())
display_scores(tree_rmse_scores)
2.7 모델 세부 튜닝
모델을 세부 튜닝하는 방법을 알아보자.
2.7.1 그리드 탐색
- 사이킷런의 GridSearch 를 이용한 방법
- 탐색하고자 하는 파라미터와 시도해볼 값을 지정
- 가능한 모든 조합에 대해 교차 검증을 사용해 평가
RandomForestRegressor 에 대한 최적의 하이퍼파라미터 조합 탐색하는 코드를 보자.
from sklearn.model_selection import GridSearchCV
param_grid = [
# 12(=3×4)개의 하이퍼파라미터 조합을 시도합니다.
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# bootstrap은 False로 하고 6(=2×3)개의 조합을 시도합니다.
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# 다섯 개의 폴드로 훈련하면 총 (12+6)*5=90번의 훈련이 일어납니다.
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)최종적으로 3 X 4 + 2 X 3 = 18 개 조합을 탐색. 5겹 교차 검증이므로 X5 = 90 번 훈련하게 된다.
.best_params_ 로 최적의 조합을 찾을 수 있다.

2.7.2 랜덤 탐색
탐색 공간이 커지면 RandomizedSearchCV 를 사용하는 편이 좋음. 반복마다 임의의 수를 대입, 지정된 횟수만큼 평가. (컴퓨팅 자원 제어 가능)
2.7.3 앙상블 방법
모델을 연결해서 튜닝하는 방법.
2.7.4 최상의 모델과 오차 분석
feature_importance 를 이용하는 방법. 중요도를 찍어보고 덜 중요한 특성은 제외한다.
2.7.5 테스트 세트로 시스템 평가하기
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse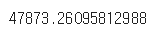
2.8 론칭, 모니터링, 시스템 유지보수
웹 사이트 내에서 모델을 사용한다고 하자.
- 사용자가 가격 예측하기 버튼을 누른다
- 쿠커리가 웹서버로 전송되어 애플리케이션으로 전달된다.
- predict() 메서드를 호출한다.
- REST API 를 통해 질의할 수 있는 전용 웹 서비스로 모델을 감쌀 수도.
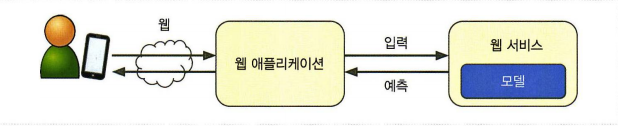
또는
- 구글 클라우드 AI 플랫폼에 배포할 수도 있다.
- 배포가 끝이 아니라 실시간 성능을 체크하고 성능이 떨어지면 알람을 통지하는 모니터링 코드가 필요하다.
- 데이터가 변화하면 데이터셋을 업데이트하고 모델을 다시 훈련해야 함.
- 모델의 입력 데이터 품질 평가
- 모든 모델 백업
연습문제 2.
from sklearn.model_selection import RandomizedSearchCV
param = {
'n_estimators': range(3, 30),
'max_leaf_nodes': range(2,8)
}
forest_reg = RandomForestRegressor(random_state = 42)
n_iter = 30
randomized_search = RandomizedSearchCV(forest_reg,
param_distributions = param,
n_iter = n_iter,
cv = 5,
random_state = 42)
randomized_search.fit(housing_prepared, housing_labels)
randomized_search.best_estimator_
