결정트리는 분류, 회귀, 다중출력 작업이 가능한 다재다능한 머신러닝 알고리즘이다. 결정트리의 훈련, 시각화, 예측에 대해 알아보고 / CART 훈련 알고리즘과 규제, 회귀 문제의 적용에 대해 알아보자.
6.1 결정 트리 학습과 시각화
결정트리의 학습 코드를 보자. 이제 코드는 익숙하다!
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # 꽃잎 길이와 너비
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X, y)X 변수 중 길이와 너비를 가져왔고, 결정트리를 임포트할 땐 DecisionTreeClassifier 를 가져온다는 것 정도를 알아보자.
훈련된 결정 트리 코드는 다음과 같이 시각화할 수 있다. 이런 게 있다 정도만 알아두자.
from graphviz import Source
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=os.path.join(IMAGES_PATH, "iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
Source.from_file(os.path.join(IMAGES_PATH, "iris_tree.dot"))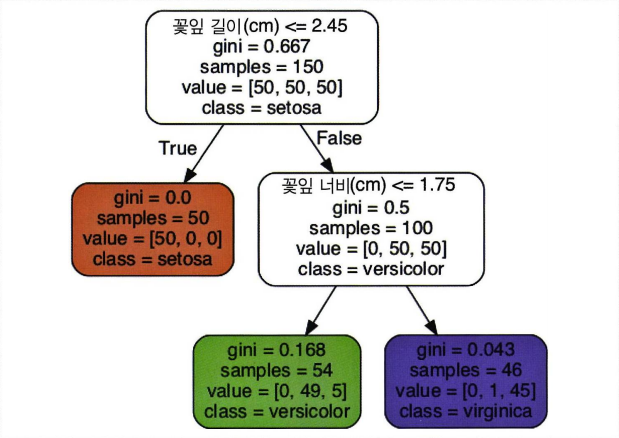
6.2 예측
훈련을 했으니 이제 예측을 하는 방법을 알아보자. (새로 발견한 붓꽃에 대해, 품종을)
예측은 루트 노드에서부터 시작한다. (위의 사진을 참고하자) 길이가 2.45cm 보다 짧은지 검사한다. 짧다면 왼쪽 자식노드로 이동한다. 여기서는 추가적인 분류를 하지 않고 Setosa 로 분류하고 있다.
길이가 2.45cm 보다 길다면 오른쪽 자식노드로 가서 또다시 너비가 1.75cm 보다 작은지 검사한다. 그러다면 이 꽃은 Versicolor, 그렇지 않다면 Virginica 로 분류한다.
노도의 sample 속성 은 해당 노드로 얼마나 많은 샘플이 분류되었는지 나타내는 숫자다. 노드의 value 속성은 각 해당 노드에 최종 클래스로 분류된 샘플이 각각 얼마인지 나타내는 숫자다. 노드의 gini속성은 불순도를 말한다. 불순도란 한 노드의 샘플이 같은 샘플이 있는 정도를 표시한다. (다른 샘플이 섞일 수록 높아진다.) 위의 사진에서 versicolor 예측의 노드의 gini 점수는 1 - (0/54)^2 - (49/54)^2 - (5/54)^2 = 0.168 이다.
지니불순도 표현식

P는 i 번째 노드에 있는 훈련 샘플 중 클래스k에 속한 샘플의 비율이다.
이제 결정경계를 보자. 수직, 수평선으로 그어진다.
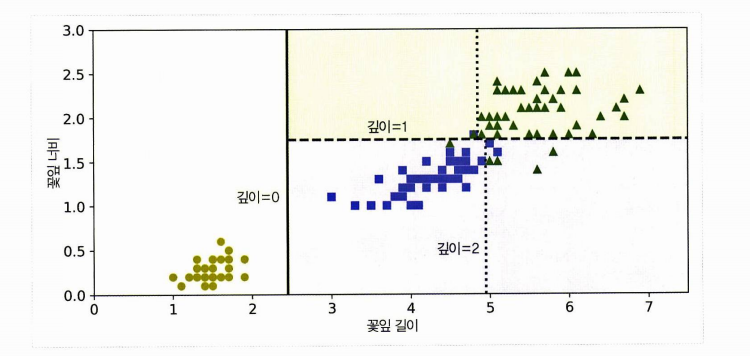
굵은 수직선은 루트 노드의 결정 경계를 나타낸다. 또 오른쪽에서 너비 = 1.75 에서 한 번 더 나누어진다.
🤔화이트박스와 블랙박스
화이트박스 모델: 직관적이고 결정 방식을 이해하기 쉬운 모델
블랙박스 모델: 성능이 뛰어나고 연산 과정 확인이 가능하지만 예측을 만드는 이유는 설명하기 어려운 모델. 랜덤 포레스트, 신경망
결정 트리는 필요하다면 따라해볼 수 있는 간단하고 명확한 방법을 사용!
6.3 클래스 확률 추정
결정 트리의 경우 한 샘플이 특정 클래스 k에 속할 확률을 추정할 수도 있다. 길이가 5cm 이고 너비가 1.5인 다음 꽃잎에 대한 각 확률 추정과 (더하면 1이된다) 하나의 클래스 예측을 다음 두 개로 알아볼 수 있다.
- predict_proba: 클래스에 속할 확률
- predict: 최종적으로 예측하는 하나의 클래스

6.4 CART 훈련 알고리즘
CART 알고리즘이란 사이킷런 내에서 결정 트리를 훈련시키기 위해 사용하는 알고리즘이다. 작동 순서는 다음과 같다.
-
훈련 세트를 특성 k의 임곗값 를 사용해 두 개의 서브셋으로 나눈다. (위에서 했던 꽃잎 길이 <= 2.45 의 과정이다.)
-
이때 특징 k와 임곗값 는 가장 순수한 서브셋으로 나눌 수 있는 짝을 찾는다.
-
CART 알고리즘의 비용함수는 따라서 왼쪽과 오른쪽 서브셋 각각의 불순도 * 샘플 수와 같다.

-
아래 서브셋을 점진적으로 계속 만든다
-
max_depth 매개변수에서 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 멈춘다.
-
다른 중지조건에 관여하는 매개변수들이 있다: min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_leaf_nodes
🤔 CART 알고리즘은 그리디 알고리즘으로 각 단계에서 최적의 분할을 찾지만 이것이 전체 불순도를 낮추는 방향으로 이어질지는 알 수 없다.
🤔 최적의 트리를 찾는 것은 NP 완전 문제로 O(exp(m)) 필요하다. 따라서 CART 정도의 납득할만한 알고리즘 정도면 충분하다고 보는 것이다.
6.5 계산 복잡도
결정 트리에서 예측 = 루트노드에서 리프노드까지 탐색 과정과 같다. (자식 노드 둘 중 하나를 선택하면서 따라가는 것.) 따라서 샘플 수가 m개라면 O(logm) 의 예측시간이 걸린다.
훈련 알고리즘은 모든 특성에 대해 모든 샘플이 예측의 과정을 수행하는 것이라 생각하면 쉽다. 따라서 하나의 샘플에 logm 의 시간이 걸렸다면 특성 수가 n일 때 훈련 복잡도는 O(n m logm) 이 된다.
사이킷런 (presort = True) 로 지정하면 미리 데이터 정렬이 되어 훈련 세트가 작을 경우 속도를 높이는 데에 도움이 된다.
6.5 지니 불순도 or 엔트로피?
DecisionTreeClassifier 의 criterion 매개변수 기본값은 gini 이다. 기본적으론 이렇게 지니 불순도를 사용하지만 criterion 을 entropy 로 주게된다면 엔트로피 불순도를 사용할 수 있다.
엔트로피는 말그대로 무질서함의 정도로 숫자가 높아지면 데이터에서 무질서함, 여기서는 불순도가 높다는 의미이므로 결정 트리에서 사용하기에 적합하다.
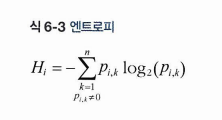
역시나 x * (-logx) 꼴로 이해를 할 수 있다.
만약 해당 노드의 샘플 수가 54이고 [0, 49, 5] 와 같이 분류되었을 때, 49를 정답과 같이 보는 것이다. 이제 확률 x를 내려가면서 그보다 더 기하급수적으로 증가하는 -logx 을 곱한 것을 불순도라고 정하는 것이다. 다음 분류의 경우
49/54 -log(49/54) + 5/54 -log(5/54) 처럼 계산한다.
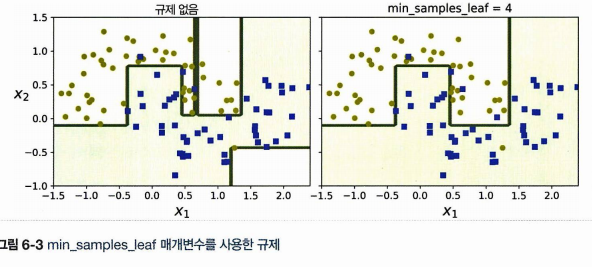
6.7 규제 매개변수
결정 트리는 모델 파라미터가 훈련되기 전에 결정되지 않는데, 이런 모델을 비파라미터 모델이라고 한다. (선형 모델 같은 파라미터 모델은 미리 정의된 모델 파라미터 수를 가지므로 과대적합의 위험이 없지만) 이러한 비파라미터 모델은 과대적합의 위험이 있어 트리의 자유도를 제한할 필요가 있다.
- 보통 트리의 최대 깊이를 제어하고, 이를 max_depth 로 조절할 수 있다.
- min_samples_split: 노드가 가져야 하는 최소 샘플 수(이만큼은 가지고 있어야 함)
- min_smaples_leaf: 리프 노드가 가지고 있어야 하는 최소 샘플 수
- min_weight_fraction_leaf: 가중치가 부여된 샘플 수에서의 비율
- max_leaf_nodes: 리프 노드 최대 수
- max_features: 하나의 노드에서 분할에 사용할 특성의 최대 수
따라서 min 을 증가시키거나 max 를 감소시키면 규제가 커진다고 이해하자.
6.8 회귀
번외와 같이 결정 트리를 통한 회귀 문제의 해결을 살펴보자.
- DecisionTreeRegressor 사용
- max_depth = 2 설정
- 2차함수 형태 데이터셋에서 회귀

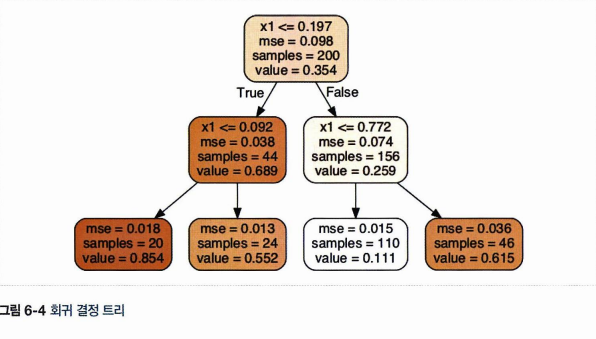
각 노드에서는 클래스를 예측하는 것이 아니라 값을 예측한다.
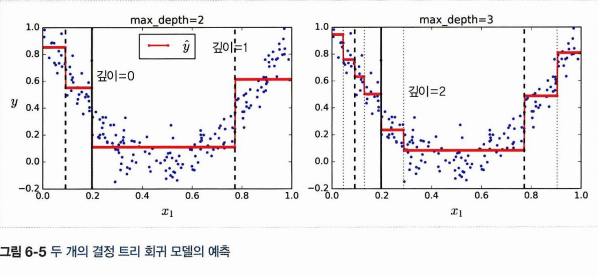
x = 0.6 인 샘플을 에측한다고 했을 때, value = 0.111 인 리프노드에 도달한다. 만약 max_depth = 3 이라면 8개의 리프노드가, max_depth = 2라면 2^2 = 4개의 리프노드가 존재하는 결정트리가 될 것이며, 해당 구간의 평균으로 예측할 것이다.
회귀에서의 CART 알고리즘은 왼쪽, 오른쪽 각각에 MSE 를 최소화하는 비용함수를 가진다.
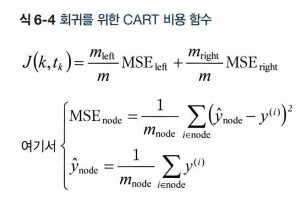
MSE 를 측정할 땐 각 회귀클래스의 예측값 y' node 에서 각 클래스에 속하는 실제 y값을 뺀 것을 오차로 보아 계산한다. 역시나 결정 트리는 과적합되기 쉬우므로, min_samples_leaf = 10 을 주자.
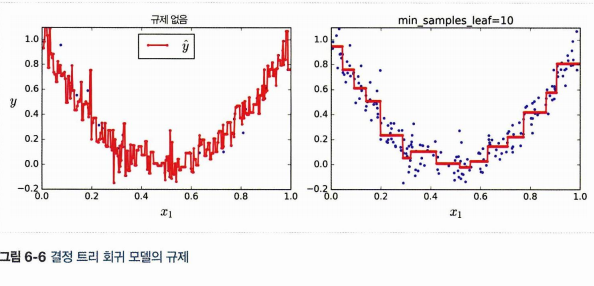
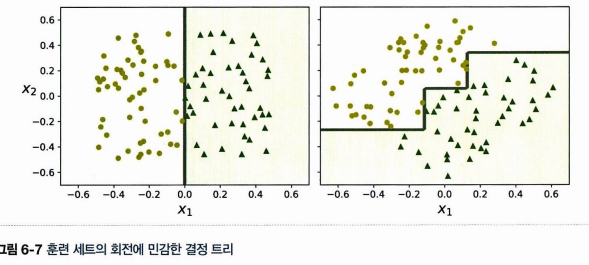
6.9 불안정성
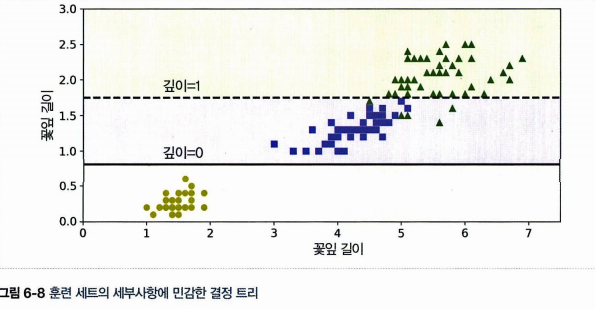
✅ 결정 트리는 축에 수직인 계단 모양의 결정 경계를 만들기 때문에 훈련 세트의 회전에 민감하다. 같은 데이터셋을 45도 기울인 오른쪽에 대해선 불필요하게 경게가 많아진 것을 확인할 수 있다.
✅ 훈련 데이터에 있는 작은 변화에도 민감하다. Versicolor 을 제거하고 훈련시키면 다음과 같은 모델을 얻ㄱ되고, 훈련 알고리즘 역시 확률적이어서 다른 모델을 얻게 될 수 있다.