Dynamic I/O queue allocation techniques for improving CPU utilization of multi-queue network block device drivers
배경지식
NVM Express(NVMe)는 다수의 queue를 생성해 SSD 내부의 병렬성을 최대한 활용할 수 있는 PCI-express 기반의 최신 storage interface이다. 그러나, PCIe에는 물리적 및 시스템 구조적인 요소로 인한 확장성의 한계점이 있다. 이를 위해, 최근 데이터센터에서 NVMe interface를 network로 확장할 수 있는 NVMe-over-TCP와 같은 기술이 주목받고 있다. 이는 별도의 network hardware의 추가없이 datacenter에서 기존에 구축된 TCP/IP network를 활용해 구축이 가능하다는 장점이 있다.
문제점
- 기존의 NVMe-over-TCP는 비효율적인 core 별 I/O queue 할당 방식으로 인해 multi-core를 제대로 활용하지 못한다는 문제점이 있다. Linux의 multi-queue block layer에서는 core 별 입출력 software queue를 지원하고 이것은 device driver hardware queue와 1:1 또는 N:1로 정적 매핑이 되어있다.
아래 그림은 NVMe device driver 구조이다.즉, 특정 core에서만 입출력 요청이 발생할 경우 입출력 요청이 하나의 입출력 큐에 편중되어 bottleneck이 발생해 입출력 성능이 저하된다.
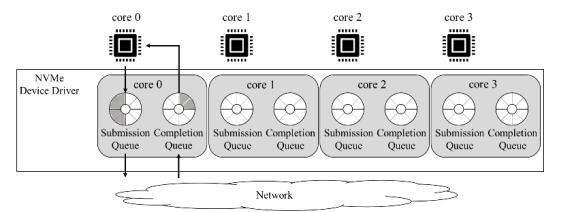
- 추가로 blk-switch와 같은 연구도 있었지만 입출력 요청을 부하가 작은 다른 core로 보내어 처리량을 향상시키는 방식인데, 이 방식은 모든 입출력 요청에 대해 매번 부하가 작은 core를 찾아야 하기 때문에 CPU overhead와 latency가 늘어난다는 단점이 존재한다.
DMMQ(Dynamic Mapped Multi-Queue)
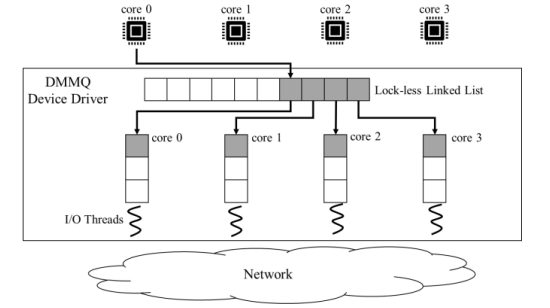
본 논문에서는 Lock-free queue를 이용해 추가적인 latency 없이 host의 multi-core를 충분히 활용할 수 있는 DMMQ를 제안한다. DMMQ device driver는 multi-queue block later의 입출력 queue에서 전달받은 입출력 요청들을 하나의 lock-free queue에 넣고, 다수의 thread가 lock-free queue로부터 삽입된 요청을 가져와서 전용 tcp socket을 통해 처리한다.
아래의 그림은 DMMQ block device driver의 구조이다.
성능평가
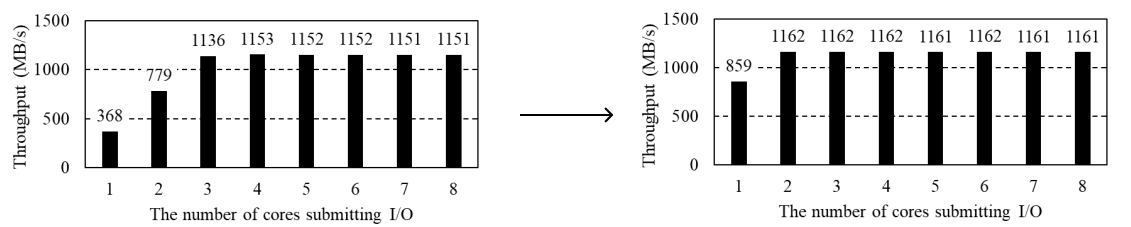
아래의 그림은 Linux kernel 5.4.0 version에서 FIO benchmark tool을 사용해 rand-write를 통해 core utilization을 측정해본 결과이다. Controller에서 Null block device를 생성하고 NVMe-over-TCP/DMMQ를 통해 host에서 rand-write workload로 8개의 FIO process를 실행했을 때, FIO가 사용하는 core 개수를 1-8개까지 변경하며 측정한 처리량을 보여주고 있다.
먼저, 왼쪽의 NVMe-over-TCP에서는 사용하는 core의 수가 2개 이하일 때는 CPU 성능에 bottleneck이 발생해 I/O throughput이 충분히 나오지 않지만 core 수가 증가하면서 4개 이상에서 Performance Saturation이 일어나는 것을 확인하였다.
반면 DMMQ에서는 core 2개에서부터 성능 포화현상이 보이는 것이 확인 가능하다.
References
[1]. 멀티-큐 네트워크 블록 디바이스 드라이버의 CPU 사용률 개선을 위한 동적 입출력 큐 할당 기법 - 손수호O , 오기준, 최영인, 안성용 부산대학교 정보융합공학과
