오버피팅
오버피팅이란 머신러닝에서 모델이 훈련 데이터에 지나치게 잘 맞춰져 있어, 새로운 또는 보이지 않는 데이터에 대해 일반화 하는 능력이 떨어지는 현상을 말한다. 모델이 훈련 데이터의 패턴 뿐만 아니라 노이즈까지 학습해버려, 실제 세계의 복잡성과 변동성을 반영하는 데 실패하는 상태이다. 오버피팅은 머신러닝 모델의 성능을 저하시키는 주요 원인 중 하나이다.
모델이 너무 복잡하거나 훈련 데이터가 너무 적을 때 자주 발생한다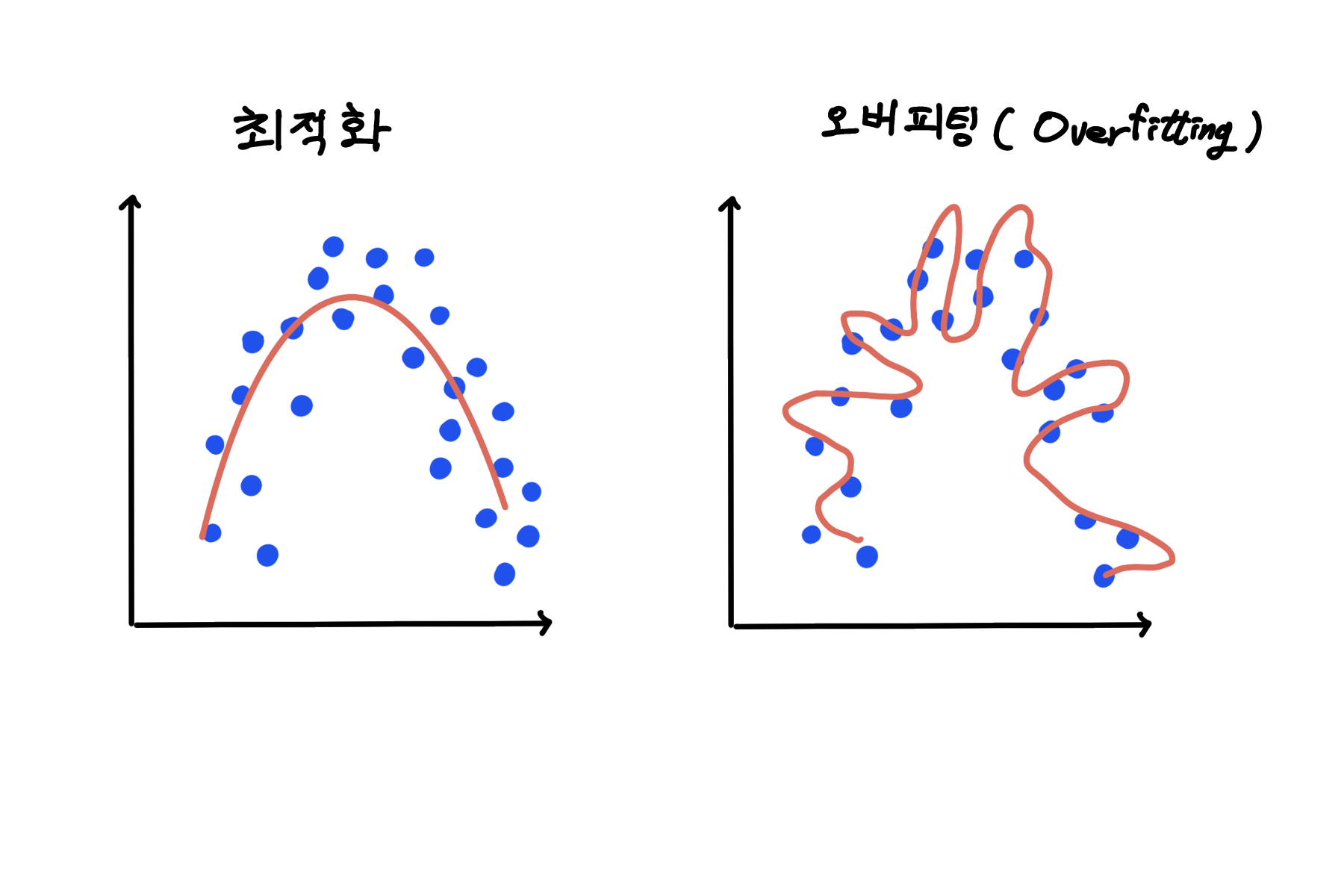
교차검증
머신러닝 모델을 개발할 때 모델의 성능을 평가하고 하이퍼파라미터를 조정하는 데 사용되는 데이터 세트를 말한다. 일반적으로 전체 데이터 세트를 훈련데이터 검증 데이터, 테스트데이터로 나누게 된다.
-
훈련데이터 : 모델을 훈련시키기 위해 사용되는 데이터 세트. 이 데이터를 기반으로 모델은 패턴을 학습하고, 매개변수를 조정한다.
-
검증데이터 : 훈련 과정 중 모델의 성능을 평가하고, 하이퍼파라미터를 조정하기 위해 사용되는 데이터세트. 검증 데이터를 사용하여 모델의 성능을 평가함으로써, 훈련 데이터에 과적합되는 것을 방지할 수 있다. 또한, 다양한 모델 구성을 실험하고 최적의 하이퍼파라미터 세트를 찾는 데 도움을 준다
-
테스트 테이터 : 모델의 일반화 능력을 최종적으로 평가하기 위해 사용되는 데이터 세트. 훈련과정에서 모델에 전혀 노출되지 않으며, 모델 개발이 완료된 후에만 단 한번 사용된다.
K-겹 교차검증
다양한 유형의 교차검증 방법이 있지만, 가장 일반적인 방법은 k-겹 교차검증이다. 데이터를 K개의 동일한 크기의 부분집합으로 나눠, 한번씩 돌아가면서 검증 데이터로 사용한다.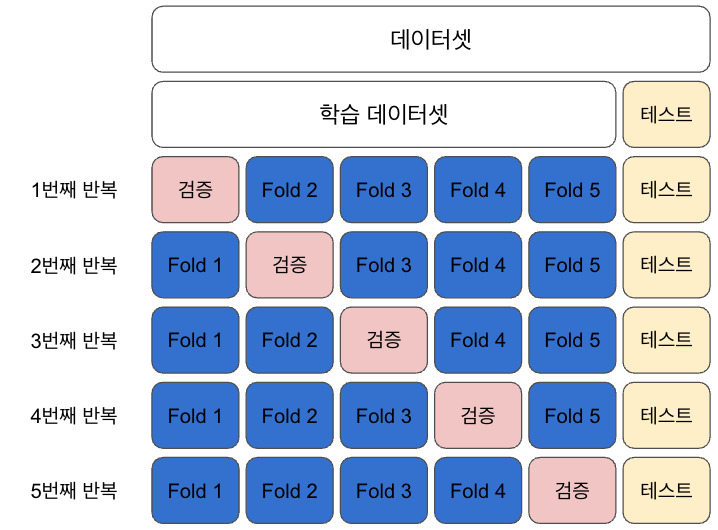
- 데이터 수가 적을 때 사용
검증방법
- 테스트 데이터 분할
전체 데이터 세트에서 일정 비율을 테스트 데이터로 분리 - 남은 데이터 세트를 K개의 동일한 크기를 갖는 폴드로 나눈다. K는 사용자가 정하는 파라미터로, 일반적인 선택은 5 또는 10
- 모델 훈련 및 검증
- K개의 폴드 중 하나를 검증 데이터 세트로 선택한다
- 남은 K-1개의 폴드를 결합하여 훈련 데이터 세트를 형성한다
- 모델을 훈련 데이터 세트에 적합시킨다
- 적합된 모델을 검증 데이터 세트에 적용하여 성능을 평가한다
- 테스트 데이터
K-겹 교차검증 과정과는 별개로 처음에 분리해둔 테스트 데이터 세트는 모델 개발 과정이 완료된 후, 최종적으로 모델의 성능을 평가하는 데 사용된다. 이 데이터는 모델 훈련이나 검증 과정에서는 전혀 사용되지 않으며, 오직 최종 모델의 일반화 능력을 평가하는데만 사용
K-겹 교차검증의 장점
- 데이터 활용 극대화
테스트를 제외한 전체 데이터 세트를 훈련과 검증에 모두 사용함으로써, 제한된 양의 데이터를 최대한 활용할 수 있다. 이는 특히 데이터 양이 제한적인 경우에 유리 - 모델의 일반화 능력 평가
다양한 훈련과 검증 세트 조합을 사용하여 모델을 평가함으로써, 모델의 일반화 능력에 대한 보다 신뢰할 수 있는 추정치를 얻을 수 있다. 이는 단일 훈련/검증 분할에 비해 모델 성능의 신뢰도를 향상시킨다 - 오버피팅 감소
모델이 다양한 훈련세트에 대해 일관된 성능을 보여야 하므로 특정 훈련 세트에 과적합 되는 것을 방지할 수 있다. 이는 모델의 오버피팅 위험을 줄이는데 도움이 된다 - 하이퍼파라미터 튜닝의 용이성
다양한 하이퍼파라미터 설정에 대해 K-겹 교차검증을 반복적으로 수행함으로써, 최적의 모델 구성을 찾는 데 도움이 된다. 이는 효과적인 하이퍼파라미터 탐색 과정을 가능하게 한다.
예제코드
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import numpy as np
# iris 데이터셋 로드
iris = load_iris()
X, y = iris.data, iris.target
# KFold 분할기 인스턴스 생성 (5-겹 교차 검증)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
kfKFold(n_splits=5, random_state=42, shuffle=True)
# 정확도 점수를 저장할 리스트
accuracy_scores = []
# KFold로 데이터를 분할
for train_index, test_index in kf.split(X):
# 분할된 훈련 및 테스트 데이터 생성
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 모델 생성 및 훈련
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 예측 및 정확도 계산
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
# 정확도 점수를 리스트에 추가
accuracy_scores.append(accuracy)
# 각 폴드에서의 정확도 출력
print("각 폴드에서의 정확도:", accuracy_scores)
# 평균 정확도 계산 및 출력
print("평균 정확도:", np.mean(accuracy_scores))각 폴드에서의 정확도: [1.0, 0.9666666666666667, 0.9333333333333333, 0.9333333333333333, 0.9666666666666667]
평균 정확도: 0.9600000000000002
