process
- 간단히 말하면 실행중인 프로그램
- 하나의 프로그램으로 여러개의 프로세스 생성 가능
프로세스 id(unique)
- 하나의 프로그램으로 여러개의 프로세스를 생성가능하기 때문에 이름만으로는 프로세스를 서로 구분할 수 없다.
- 프로세스 id를 이용하여 구분할 수 있다.
시그널
프로세스 ID가 사용되는 대표적인 예로 시그널이 있다.
ctrl c를 눌러 프로그램 실행을 멈출 때 사용되는 기능이 바로 시그널
ctrl c 누르면 커널이 해당 프로세스에 인터럽트 시그널(SIGINT)을 보내 이를 전달받은 프로세스가 자발적으로 종료
process 관련 명령어
ps: 현재 프로세스의 스냅샷 보고
- UNIX 옵션 - 그룹화할 수 있으며 앞에 -(dash)가 있어야 합니다.
- BSD 옵션 - 그룹화할 수 있으며 -와 함께 사용하면 안 됩니다.
- GNU 옵션 - 앞에 두 개의 --가 있습니다.
-
-A: 모든 프로세스 출력
-
-a:
세션리더이거나 터미널과 관련되지 않은 프로세스를 제외한 모든 프로세스에 관한 정보 출력세션리더는 세션 ID == 프로세스 ID
-
-c Clist: Clist 변수에 나열된 작업부하 관리 클래스에 할당된 프로세스에 대한 정보만을 표시
clist 변수: 클래스 이름을 쉼표로 구분한 리스트이거나 하나 이상의 공간 또는 그 두가지로 구분되는 큰 따옴표 안에 있는 클래스 이름의 리스트입니다.
-
-d:
세션리더 제외하고 모든 프로세스 출력 -
-e: 모든 프로세스를 출력, -A와 동일
-
-u: 특정 사용자의 프로세스 정보를 확인할 때 사용, 사용자를 지정하지 않으면 현재 사용자 기준으로 정보 출력
-
-f: full listing, 전체 리스트를 작성
-
-l: long listing, 프로세스의 정보를 길게 보여주는 옵션, 우선순위와 관련된 PRI와 NI값 확인 가능
-
-M: 64bit 프로세스들 조회
-
-m: 프로세스들 뿐만 아니라 커널 스레드들도 조회
프로세스에 대한 출력 행 뒤에는 각각의 커널 스레드에 대한 추가적인 행이 출력됩니다. -
-o [options]: 출력 포맷을 지정하는 옵션으로 값으로는 pid, tty, time, cmd 등을 지정할 수 있음
-
-p [options]: 특정 PID 지정할 때 이용
-
-r: 현재 실행 중인 프로세서 보여줌
-
-x: 로그인 상태에 있는 동안 아직 완료되지 않은 프로세스들을 보여줌, 유닉스 시스템은 사용자가 로그아웃 한 후에도 임의의 프로세스가 계속 동작하게 할 수 있다. 그러면 그 프로세스는 자신을 실행시킨 셸이 없이도 계속 자신의 일을 수행하는데 이러한 프로세스는 일반적인 ps 명령으로 확인할 수 있다. 이 때 -x 옵션을 사용하면 자신의 터미널이 없는 프로세스들을 확인할 수 있다.
-
-G Glist : Glist 변수에 대해 나열된 프로세스 그룹에 있는 프로세스에 대한 정보만 표준 출력에 씁니다.
Glist 변수: 프로세스 그룹 식별자 중 쉼표로 구분된 리스트이거나 큰따옴표로 묶인 프로세스 그룹 식별자의 리스트
쉼표 또는 하나 이상의 공백으로 구분된다. -
-g Glist : 이 flag는 -G Glist와 동일
-
-k: 커널 프로세스를 나열
-
-N: 스레드 통계를 축적하지 않습니다. 이 flag로 ps는 프로세스의 스레드 체인을 통해 순회하지 않고 간단히 얻을 수 있는 통계를 보고합니다.
-
-n Namelist: default를 대신하는 대체 시스템 이름 리스트 파일을 지정, 정보가 커널에 직접 제공되지 않으므로 운영 시스템은 -n 플래그를 사용하지 않습니다.
//BSD 계열
-
a: 터미널들 간의 모든 프로세스에 대한 정보를 표시
일반적으로 사용자의 고유 프로세스만 표시 -
c: 명령 매개변수가 아닌 사용통계의 목적으로 시스템에 내부적으로 보관된 대로 명령이름을 표시하여 이 이름은 프로세스 주소 공간에 보관됩니다.
-
e: 최대 80문자로 명령에 대한 매개변수는 물론 환경을 표시합니다.
-
ew: e flag로부터 표시장치를 하나의 추가 행으로 랩합니다.
-
ewww: e flag로부터 표시장치를 필요한 만큼 여러번 랩합니다.
-
g: 모든 프로세스를 표시
-
l: long listing, 프로세스의 정보를 길게 보여주는 옵션, 우선순위와 관련된 PRI와 NI값 확인 가능
-
n: 숫자 출력을 표시, 긴 리스트에서 WCHAN 필드는 기호가 아닌 숫자로 인쇄된다. 사용자 리스트에서 USER 필드는 UID 필드로 대체
-
s: 각 프로세스의 커널 스택 크기(SSIZ)를 기본 출력 형식으로 표시합니다.
-
u: 프로세스의 소유자를 기준으로 출력
-
v: PGIN, SIZE, RSS, LIM, TSIZ, TRS, %CPU, %MEM 필드를 표시
-
w: 출력을 위한 광범위한 열 형식(80열이 아닌 132열)을 지정합니다. ww 처럼 반복되는 경우 일정 범위의 출력을 사용합니다. 이 정보는 인쇄할 long 명령의 수를 결정하는데 사용됩니다.
-
x: 데몬 프로세스처럼 터미널에 종속되지 않는 프로세스 출력
포그라운드 프로세스
사용자와의 대화창구인 표준 입출력 장치 즉 터미널과 키보드를 통해 대화
백그라운드 프로세스
입력장치에 대해 터미널과의 관계를 끊은 모든 프로세스, 즉 사용자에게 무언가를 키보드를 통해 전달받지 않고 스스로 동작하는 프로세스
데몬 프로세스
백그라운드 프로세스 중에서 부모 프로세스(PPID)가 1(부모프로세스를 가지지 않음) 혹은 다른 데몬프로세스인 프로세스
그렇다면 데몬프로세스도 백그라운드 프로세스 중 하나인데 일반적인 백그라운드 프로세스와 무엇이 다른가?
프로세스를 실행한 bash가 종료되었을 때 bash를 통해 실행한 다른 백그라운드 프로세스가 함께 종료되는가 아닌가가 차이난다.
- -ef|grep
plain-text를 찾아주는 명령어
pggrep으로 유사하게 사용 가능
가상 메모리 : 메모리가 실제 메모리보다 많아 보이게 하는 기술
컴퓨터의 메모리는 8GB 혹은 16GB이다.
리눅스의 경우 하나의 프로세스가 4GB인데, 실제로 각각의 프로세스에 이만큼의 메모리를 할당하기에는 실제 메모리 크기에 한계가 있다.
프로세스를 실행하기 위해서 코드는 반드시 메모리에 있어야 한다.
하나의 프로세스만 실행 가능한 시스템(배치 처리 시스템 등)의 경우 가상 메모리를 필요로 하지 않는다.
- 프로스램을 메모리에 로드(load)
- 프로세스 실행
- 프로세스 종료(메모리 해제)
하지만 여러 프로세스를 동시에 실행하는 시스템의 경우 아래와 같은 이유로 가상 메모리를 필요로 하게 된다.- 메모리 용량 부족 이슈
- 프로세스 메모리 영역 간 침범 이슈
프로세스는 가상 주소를 사용하고, 실제 해당 주소에서 데이터를 읽고 쓸 때만 물리 주소로 바꿔주면 된다.- 가상 주소: 프로세스가 참조하는 주소(0~4GB)
- 물리 주소: 실제 메모리 주소
CPU가 특정 프로세스의 어떤 공간을 참조할 때는 우선 가상 주소를 먼저 참조하고, 가상 주소에 해당하는 실제 물리 주소를 참조하게 된다. 가상 주소를 참조할 때마다 매번 이를 물리 주소로 변환을 하게 되니까 이 시간을 짧게 하려고 MMU라는 하드웨어 칩의 지원을 받는다. MMU는 가상 주소를 물리 주소로 빠르게 변환해주는 역할을 한다.
MMU (Memory Management unit):
CPU에 코드 실행 시, 가상 주소 메모리 접근이 필요할 때 해당 주소를 물리 주소값으로 변환해주는 하드웨어 장치- 가상 메모리와 MMU 관계
CPU는 가상 메모리 주소를 다루고, 실제 해당 주소 접근 시 MMU 하드웨어 장치를 통해 물리 메모리에 접근
하드웨어 장치를 이용해야 주소 변환이 빠르기 때문에 MMU라는 별도의 장치를 두고 있는 것이다.가상메모리의 관리에서 페이지로 나누었을 경우 페이징, 세그먼트 단위로 나누었을 경우 세그멘테이션 시스템이라고 부른다.
실주소 = 페이지 프레임(f) + offset
- 페이징 시스템
하나의 프로세스에서 특정 시간 동안 쓰는 메모리 영역은 4GB중 아주 일부분이기 때문에 일부분만 실제 물리 메모리에 올려놓고 쓰자는 것이 가상 메모리의 컨셉이다.
그럼 어느 정도의 사이즈만큼 메모리에 올릴 지에 대한 결정이 필요한데 이를 page 단위로 다루겠다는 것이 페이징 시스템이다- 페이징
- 크기가 동일한 페이지 단위로 가상 주소 공간과 이에 매칭되는 물리 주소 공간을 관리
- 하드웨어 지원이 필요: Intel x86 system(32bit)에서는 4KB, 2MB, 1GB 지원
- 리눅스에서는 4KB로 paging
- 페이지 번호를 기반으로 가상 주소와 물리 주소의 매핑 정보를 기록하고 사용한다.
- 리눅스의 경우 4GB의 가상 메모리를 4KB 단위로 쪼개서 페이징하고 페이지 번호를 붙임
- 페이지 단위로 물리 메모리에 넣고, 해당 데이터를 찾을 때에도 페이지 번호를 기반으로 주소를 찾게 된다.
- 프로세스의 PCB에 Page Table 구조체를 가리키는 주소가 들어있음
- Page Table에는 가상 주소와 물리 주소 간 매핑 정보가 있음
CPU가 특정 가상 주소를 참조하게 되면, 그 가상 주소가 몇 페이지 인지를 알 수 있고, 이를 통해 Page Table에서 해당 페이지의 실제 물리 메모리 주소를 알아낼 수 있다.
PRI vs NI
PRI는 운영페제에서 참고하는 우선순위로 조작할 수 없다.
NI는 사용자가 조작할 수 있는 우선순위값으로 일반사용자는 우선순위를 낮출 수는 있어도 올릴 수는 없다. root관리자 계정만이 둘다 할 수 있다.
NI값 범위: -20~19, default 0(숫자가 작을수로 우선순위 높음)$ nice -n [N] [프로세스명] //기존 우선순위 값에 N만큼 더한 우선순위로 [프로세스명]을 실행 $ nice [프로세스명] //-n 옵션 없이 사용할 경우 N값은 디폴트로 10을 가짐, 즉 10을 더해 우선순위를 낮춰서 실행시키는 것 //nice는 renice 명령어와는 달리 **새로운 프로세스가 추가**되고, 기존 프로세스의 NI값에서 증가 또는 감소한다. //실행중인 프로세스의 우선순위를 변경하는 명령어 //nice는 프로세스명으로 우선순위를 조정하고, 명령을 실행하면 새로운 프로세스가 발생하지만 //renice는 PID로 우선순위를 조정하고 기존의 프로세스 우선순위 값을 추가없이 바로 수정 $ renice [N] PID //실행 중인 PID 프로세스의 우선순위값 NI를 N만큼 더함 -n: nice와 마찬가지로 우선순위를 조정할 때 사용 -g: 특정 그룹을 지정해서 우선순위를 조정할때 사용 -p (--pid): 디폴트 값이기 때문에 옵션 안붙이고 renice N pid 이렇게 써도 된다. renice N -p pid 와 동일 -u (--user): 특정 사용자를 지정해서 우선순위를 조정
ps 항목
UID: SYSTEM V계열에서 나타나는 항목으로 프로세스 소유자의 이름
PID: 프로세스의 식별변호
PPID: 부모 프로세스 ID
VSZ: K단위 또는 페이지 단위의 가상메모리 사용량
- MMU: 메인 메모리에서 사용되지 않는 메모리 블록 하나를 골라서 할당
20바이트를 할당 요청 했음에도 메모리 블록은 4K 바이트 단위라서 4K를 할당받게 된다.
메모리 블록의 크기는 시스템에 따라서 다양하며 실제 메인 메모리 블록을 페이지 프레임, 가상 메모리 블록을 페이지라 한다. (프레임 크기 = 페이지 크기)
RSS: 실제 메모리 사용량 (Resident Set Size)
실제 프로세스가 물리 메모리에서 점유하고 있는 메모리, 하지만 공유 메모리 등의 방식으로 각 프로세스는 메모리를 공유할 수 있기 때문에 RSS의 총 크기 합은 서버의 물리 메모리보다 클 수 있다. 프로세스가 동작하는 도중 별도의 메모리 할당 없이 RSS는 VSZ까지 증가할 수 있다.
TTY: 프로세스와 연결된(수행되고 있는) 제어 터미널을 표시, ?는 제어 터미널에 연결되어있지 않음을 나타냄
S, STAT: 현재 프로세스의 상태 코드 (S: Sys V, STAT: BSD)
- STAT 코드는 세 개의 필드로 구성되어 프로세스 상태를 보여줍니다. 첫 번째 필드는 D,R,S,T,X,Z 코드가 위치하는 데 이들 코드의 의미는 다음과 같다.
코드분류 의미 D IO 와 같이 중지(interrupt)시킬 수 없는 잠자고 있는(휴지) 프로세스 상태 R 현재 동작중이거나 동작할 수 있는 상태(동작) S 잠자고 있지만 중지시킬 수 있는 상태(대기) T 작업 제어 시그널로 정지되었거나 추적중에 있는 프로세스 상태 X 완전히 죽어 있는 프로세스(가용메모리 위해 대기중) Z 죽어 있는 좀비 프로세스 두번째 세번째 필드 코드
코드분류 의미 < 프로세스의 우선 순위가 높은 상태 N 프로세스의 우선 순위가 낮은 상태 L 실시간이나 기존 IO를 위해 메모리 안에 잠겨진 페이지를 가진 상태 s 세션 리더(주도 프로세스) l 멀티 쓰레드 + 포어그라운드 상태로 동작하는 프로세스 STAT에서 Z로 되어있는 좀비프로세스는 프로세스 작동이 잘못되어 죽어있는 상태로 시스템 관리자는 이러한 불필요한 프로세스를 발견할 때 마다 제거해 줄 필요가 있습니다. 왜냐하면 이러한 고착상태에 있는 불필요한 프로세스들이 시스템 자원을 고갈할 수 있으므로 시스템에 좋지 않은 영향을 줄 수 있기 때문이다.
TIME: 프로세스에 의해 사용된 총 CPU 사용 시간을 '시:분' 형태로 나타냄
COMMAND: 프로세스의 실행 명령행
STIME: 프로세스가 시작된 시간 혹은 날짜
C, CP: 짧은 기간 동안의 CPU 사용률 (C: Sys V, CP: BSD)
F: 프로세스와 연관된 플래그
PRI: 실제 실행 우선순위
NI: nice값으로 정한 프로세스 우선순위 번호, 값이 낮을수록 순위도는 높음
ADDR: 프로세스 메모리 주소
SZ: 크기를 나타내는 필드로 프로세스의 전체 페이지 수, 페이지 사이즈는 하드웨어 플랫폼에 따라 각기 다름
WCHAN: 대기중인 프로세스가 있는 커널 함수의 주소, '-'는 프로세스가 동작중임을 나타냄
//
USER: BSD계열에서 나타나는 항목으로 프로세스 소유자의 이름
%CPU: 마지막 분동안 프로세서가 사용한 CPU시간의 백분율
%MEM: 메모리의 사용 비율의 추정치 (BSD)
메모리에 있는 작업 세그먼트 수와 코드 세그먼트 페이지 수의 합계에 4(RSS값)를 곱하고 머신에서 사용중인 실제 메모리 크기(KB)로 나눈 후 100을 곱해 가장 가까운 전체 백분율 점으로 반올림하여 계산합니다. 이 값은 프로세스에서 사용중인 실제 메모리의 백분율을 전달하려고 합니다. 하지만 RSS와 마찬가지로 다른 프로세스와 프로그램 텍스트를 공유하는 프로셋스의 비용을 과장해 표시하는 경향이 있습니다. 또한 가장 가까운 백분율 점으로 반올림하면 시스템에서 RSS값이 실제 메모리 크기의 0.005배 이하인 모든 프로세스의 %MEM 값이 0.0이 됩니다.
kill: 프로세스 끄는 명령어
kill pid : 프로세스 ID로 끌 수 있음
kill -9 pid: kill 명령어는 여러가지 방식으로 프로세스를 끄는데 그중 9번이 즉시 종료
Kilall: kill은 하나의 프로세스만을 죽이지만 killall은 지정한 이름으로 생성된 모든 프로세스 죽일 수 있음
nice: 일반적으로 프로세스들은 설정된 우선권 순위대로 실행하는데, nice 명령을 사용하게 되면 프로세스의 실행 우선권을 바꿀 수 있다.
nohup: 부모 프로세스가 죽거나 종료되더라도 자식 프로세스는 계속 동작하도록 백그라운드 모드에서 프로세스를 실행하는 명령, 이에 대한 정보는 nohup.out 파일에 기록된다.
$ nohup 명령 & //&: 이 작업을 백그라운드에서 실행하라
jobs, foreground(fg), background(bg), stop: 작업을 백그라운드로 또는 포그라운드로 자유롭게 돌릴 수 있는 방법
$ tail -f source_file & //백그라운드로 실행 $ jobs //백그라운드 실행중 프로세스 출력 //[1]+ Stopped tail -f source_file $ bg %1 //백그라운드로 돌리기 $ fg %1 //포그라운드로 전환하기
pstree: 실행중인 프로세스 상태를 트리 구조로 보여주는 명령으로 이 명령뒤에 사용자 계정을 지정하면 그 사용자가 실행한 프로세스들을 트리 구조로 점검할 수 있다.
top: ps와 유사, 지속적으로 프로세스 현황 살펴볼 수 있음, q로 탈출
PID : 프로세서 아이디
USER : 사용자 아이디 (해당 프로세서를 수행한 사용자 아이디를 말함)
PR : 우선 작업 순위 (-20 ~ 20)
NI : 작업의 nice(작업우선순위) 값. 값이 음수일 경우에는 매우 높은 우선순위를 뜻함
VIRT : 프로세서가 사용한 가상 메모리의 총 크기(kb). VIRT = RES + SWAP
RES : 실제 사용중인 물리 메모리의 총 크기
SHR : 공유 메모리의 총 크기. 쉽게말해 다른 프로세스와 공유할 수 있는 메모리의 총 크기
S : 해당 프로세서의 상태 (D:중단 될 수 없는 유휴(sleep) 상태, R:실행 상태 , S:유휴(sleep) 상태 , T:Trace 또는 중단 된 상태 , Z:좀비 상태)
%CPU : CPU 사용 비율의 추정치(BSD)
CPU의 사용에 대한 상황을 알 수 있다. 사용자가 사용중인 CPU의 사용율(0.6% us), 시스템이 사용하는 CPU의 사용율(0.5% sy), NICE 정책에 의해 사용되는 CPU의 사용율( 0.0% ni), 사용되지 않는 CPU의 미사용율(98.7% id), 입출력 대기상태의 사용율(0.1% wa)등의 상황에 대해 알 수 있다.
%MEM : 메모리 사용량
TIME+ : 프로세스가 CPU를 점유한 누적 시간
COMMAND : 명령어 정보
uptime: top과 같은 무거운 프로그램을 돌리기 보다는 빠르게 프로세스를 체크해야할 필요성이 있을 때 간단하게 알아볼 수 있는 명령어
free: 시스템의 메모리 상태를 간단하게 알아볼 수 있는 명령어
total: 설치된 총 메모리 크기/ 설정된 스왑 총 크기
used: = total-free-buff/cache, 사용중인 메모리, 사용중인 스왑 크기
free: total-used-buff/cache, 실제 사용 가능한 여유 있는 메모리량, 사용되지 않은 스왑 크기
shared: tmpfs(메모리 파일 시스템), ramfs 등으로 사용되는 메모리, 여러 프로세스에서 사용할 수 있는 공유 메모리
buff/cache: 버퍼와 캐시를 더한 사용중인 메모리
available: swapping 없이 새로운 프로세스에서 할당 가능한 메모리의 예상 크기(예전의 -/+ buffers/cache가 사라지고 새로 생긴 컬럼)
- -h : 사람이 읽기 쉬운 단위로 출력
- -b | -k | -m | -g : 바이트, 키비바이트, 메비바이트, 기비바이트 단위로 출력
- --tebi | --pebi : 테비바이트, 페비바이트 단위로 출력
- --kilo | --mega | --giga | --tera | --peta : 킬로바이트, 메가바이트, 기기바이트, 페타바이트 단위로 출력
- -w : 와이드 모드로 cache와 buffers를 따로 출력
- -c '반복' : 지정한 반복 횟수 만큼 free를 연속해서 실행
- -s '초' : 지정한 초 만큼 딜레이를 두고 지속적으로 실행
- -t : 합계가 계산된 total 추가로 출력
- Buffer: 버퍼 캐시로 디바이스 블록에 대한 메타데이터들을 메모리에 캐싱한 크기
블록 디바이스로부터 데이터를 읽어보기 위해 필요한 정보들을 메모리에 저장- Cache: 페이지 캐시와 slab으로 사용중인 메모리 크기
리눅스 커널은 기본적으로 메모리가 유휴 상태로 있는 것을 선호하지 않는다. 프로세스에 할당되어 있지 않은 메모리는 커널이 사용을 하고 커널은 이런 메모리를 주로 캐시용도로 사용한다.
캐시 메모리 종류- page cache: 리눅스는 물리적인 저장/통신 장치와 데이터를 주고 받을 때 먼저 메모리에 적재한 후 데이터를 주고 받는데 나중에 동일한 데이터에 대한 접근을 할 경우 메모리에서 바로 가져오도록 하여 I/O 성능을 높이기 위함이다. 이 때 Page라는 단위로 관리하는데 이를 Page cache라고 한다.
- inode/ dentry cache: 파일의 자료구조를 의미한다. 보다 빠른 데이터 접근을 위해 Slab의 자료구조에 추가되어 사용, dentry는 경로명 탐색을 위한 cache 역할도 수행
slab
Slab Allocator라고 하며 일종의 자원 할당자 중 하나로 4KB의 크기를 가진 Page로 데이터를 저장하고 관리할 경우 발생하는 단편화를 최소화하기 위해 만들어졌다.
리눅스 커널은 자료구조로 Slab을 사용하고 있으며 /proc/meminfo에서 리눅스 커널이 사용하는 cache 크기(Slab: 349364KB)를 의미
리눅스 커널에서 커널과 디바이스 드라이버, 파일시스템 등은 영구적이지 않은 데이터(inode, task 구조체, 장치 구조체 등)들을 저장하기 위한 공간이 필요한데 이것이 Slab 구조하에 관리된다. /proc/meminfo 에서 출력되는 Slab값은 이러한 데이터들의 메모리상 크기를 의미하기 때문에 커널 cache라고 표현
--slab의 크기가 크다면 Slab 자료구조에서 계속해서 cache 데이터로 담고 있다는 것이다. 이는 동작하고 있는 프로세스의 성격과 관련이 높다. 해당 프로세스의 주 작업 패턴이 특정 파일을 대량으로 생성하고 이 데이터를 가공처리하는 작업을 반복하며 작업과정에서 생성, 삭제되는 파일이 많을 경우이다. 리눅스 커널은 파일 시스템의 성능을 나아가 시스템의 성능을 개선하기 위해 inode와 dentry를 메모리에 cache한다. 하지만 파일을 빈번하게 생성/삭제 하거나 대량의 파일을 다루는 시스템의 경우 해당 파일을 자주 재활용하지 않는다면 cache 메모리를 사용하기 보단 I/O를 위한 버퍼 또는 프로세스에 할당되어 활용하는 편이 더 좋다.
$ slabtop
-- /proc/slabinfo directory 또는 file이 없다고 뜬다.
-- 실행시키는 법 찾을것..
vmstat: 가상 메모리의 상태를 체크하는 명령어, 프로세스 정보, 메모리 사용량, 스왑, IO상태 및 CPU 활동 상황에 대한 정보를 보여줌
r: cpu 접근 대기 중인 실행 가능한 프로세스 수
b: I/O 자원을 할당받지 못해 블록된 프로세스의 수/ b의 수치가 높은 경우 i/o 작업을 위해 cpu가 계속 대기 상태로 있다는 뜻이므로 디스크의 i/o 문제를 확인해야한다.
swpd: 현재 메모리가 부족하여 swap을 사용하고 있는 양을 의미한다. 이 값이 높아도 free에 많은 메모리의 여유가 있다면 괜찮다. 사용되 가상 메모리 용량
free: OS에서 실제 남은 메모리의 공간을 의미
buff: 버퍼에 사용된 메모리의 용량
cache: 페이지 캐시에 사용된 메모리의 용량
si: swap-in 된 메모리의 양(kb)/ swap 공간에 있는 데이터를 메모리로 호출한다.
so: swap-out 된 메모리의 양(kb), swap-out가 지속적으로 발생한다면 메모리 부족을 의심, 0인 경우가 좋다.
bi: 초당 블럭 디바이스로 보내는 블럭 수
bo: 초당 블럭 디바이스로 부터 받은 블럭 수(bi/bo가 높다면 하드디스크에 쓰고 읽는 값이 많다는 것)
in: 초당 발생한 interrupts의 수, 양이 많다면 네트워크 쪽 점검 필요
cs: 초당 발생한 context switchs(문맥교환) 수
us: CPU가 사용자 수준(level) 코드를 실행한 시간(단위 %) -> 사용자 영역에서 사용하는 CPU의 비율 us의 CPU가 높을 경우: OS 명령어로 알기 어렵다.
sy: CPU가 시스템 수준(level) 코드를 실행한 시간(단위 %) -> 시스템 콜 호출에 의해 사용되는 CPU 비율 sy의 CPU가 높을 경우: truss 명령어로 어떤 시스템 콜이 수행중인지 확인 가능
id(idel): 사용가능한 CPU의 시간율 id = 100 - (us+sy)
wa: disk 혹은 I/O 작업으로 인해 CPU가 대기하는 시간 비율
st: 가상 머신으로부터 뺏은 시간
- -a: active와 inactive 메모리 사용량에 대한 결과를 출력
- -d: 디스크의 사용량을 보여줌
- reads/writes
total: 성공한 모든 읽기/쓰기 작업 개수
merged: 하나의 I/O로 묽은 읽기/쓰기 작업 수
sectors: 성공적으로 읽은/쓴 섹터 수
ms: 읽기/쓰기 작업을 하는데 소요된 시간(밀리초)- I/O(입출력)
cur: 현재 수행 중인 I/O 수
sec: I/O를 수행하는데 소요된 시간(초)- -t: 시간까지 표시해서 출력
시스템 콜
- fork(2)
pid_t fork(void);
//return 성공시 자식 프로세스의 프로세스ID값, 실패시 -1호출시 커널은 그 프로세스를 복제해서 두 개의 프로세스로 분리
원래 존재하던 프로세스를 부모 프로세스 복제해서 만들어진 쪽을 자식 프로세스
- exec(2)
//유닉스계열 운영체제에서는 execve()만 시스템 콜이고 나머지는 라이브러리 함수
//l(list)이 붙은 경우는 실행할 프로그램의 실행 인자를 함수의 가변 인자로 전달, 배열의 마지막은 NULL
execl(const char *path, const char *arg, .../*NULL*/);
execlp(const char *program, const char *arg, .../*NULL*/);
execle(const char *path, const char *arg, .../*NULL*/ char * const envp[]);
//v(vector)이 붙은 경우는 실행 인자를 문자열 배열로 전달, 배열의 마지막은 NULL
execv(const char *path, const char *arg);
execvp(const char *path, const char *arg);
execve(const char *path, const char *arg, char * const envp[]);프로세스 자기 자신을 새로운 프로그램으로 덮어쓰는 시스템 호출
exec 실행하면 그 시점에서 현재 실행중인 프로그램이 소멸하고, 새로운 프로그램을 로드하여 실행
- wait(2)
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);wait은 자식 프로세스 중 어느 하나가 끝나는 것을 기다린다.
waitpid()는 첫번째 인자로 지정한 pid에 해당하는 프로세스가 끝나는 것을 기다린다.
status: 자식 프로세스의 종료 상태를 얻기 위해 사용(종료 상태=종료 나타내는 flag와 exit() 인자로 전달된 값을 합성한 값
매크로
- WIFEXITED(status): exit로 종료했으면 0이 아닌 값
- WEXITSTATUS(status): exit로 종료한 경우, 종료 코드 반환
- WIFSIGNALED(status): 시그널로 종료했으면 0이 아닌 값
- WTERMSIG(status): 시그널로 종료했으면 시그널 번호를 반환
option
WNOHANG: waitpid()를 실행했을 때, 자식 프로세스가 종료되어 있지 않으면 블록상태가 되지 않고 바로 리턴하게 해준다.
WUNTRACED: pid에 해당하는 자식 프로세스가 멈춤 상태일 경우 그 상태를 리턴한다.
즉 프로세스의 종료뿐 아니라 프로세스의 멈춤상태도 찾아낸다.
파일/디렉토리 관련된 명령어
디렉터리 관리
ls: 디렉터리 및 파일의 정보를 나열
- -a: 숨김파일 포함하여 모든 항목
- -d: 디렉토리 정보만 표시
- -F: 파일이 디렉토리인 경우 /(슬래쉬), 파일이 실행 가능한 경우 *, 소켓인경우 =), FIFO |, 심볼릭링크인경우 @를 각각 파일이름의 뒤에 추가
- -l: 각파일의 모드,링크수, 소유자, 그룹, 크기(바이트), 최종 수정시간을 표시
- -m: 쉼표로 구분해서 보여짐
- -r: 역순으로 보여짐
- -R: 하위의 서브 디렉토리의 내용도 순차적으로 표시
- -s: 킬로바이트 단위로
- -t: 최종 수정 시간 기준
- -u: 최종 수정시간 대신 최종 액세스 시간
- tree: 디렉토리, 파일구조를 트리 형식으로 볼 수 있다.
cd [directory]: 작업 디렉터리 변경
pwd : 현재 작업 디렉터리 절대 경로명 출력
mkdir [directory]: 새로운 디렉터리 생성
rmdir [directory]: 비어있는 디렉터리 삭제시 사용
파일 관리
cat: 파일의 내용을 출력하거나 여러 파일의 내용 병합\
more [file] 파일의 내용을 스크롤하여 출력
head [file]: 파일의 앞부분(디폴트는 앞 열 줄)을 출력
tail [file]: 파일의 뒷부분(디폴트는 마지막 열 줄)을 출력
mv [file1][file2]: 파일과 디렉토리를 이동시키거나 파일 이름을 변경
cp [file1][file2]: 파일의 내용을 복사하고 새로운 이름을 생성
-i : 복사대상 파일이 있을 경우 실행여부를 물어봄
-f : 복사대상 파일이 있을 경우 확인없이 강제로 복사
-r, -R : 디렉토리 복사할 경우 하위 디렉토리와 파일 모두 복사
-v : 복사 진행상태 출력
-d : 복사대상 파일이 심볼릭(기호,상징)파일이면, 심볼릭 정보를 그대로 유지한 상태로 복사
-p : 원본파일의 소유주, 그룹, 권한, 시간정보를 보존하여 복사
-a : 원본파일의 속성, 링크 정보들을 그대로 유지하면서 복사
rm [option][file/directory]: 파일이나 디렉토리를 삭제
- -f, --force : 삭제 여부를 묻지 않고 강제 삭제를 실행
- -i : 삭제 시 일일이 삭제할 것인지 물어봄
- -d, --dir : 디렉토리를 삭제한다. 디렉토리 안에 파일이나 서브 디렉토리가 있을 경우 삭제되지 않음
- -r, -R, --recursive : 하위 디렉토리를 포함한 모든 파일들을 모두 삭제
- -v, --verbose : 삭제 과정을 출력
ln [][]: 하드 링크 또는 심볼릭 링크 생성
파일 권한 관리
chmod: 기존 파일이나 디렉토리의 접근 권한을 변경
chmod [OPTION][MODE] [FILE]
OPTION
-v: 모든 파일에 대해 모드가 적용되는 진단(diagnostic) 메시지 출력.
-f: 에러 메시지 출력하지 않음.
-c: 기존 파일 모드가 변경되는 경우만 진단(diagnostic) 메시지 출력.
-R: 지정한 모드를 파일과 디렉토리에 대해 재귀적으로(recursively) 적용.
MODE
파일에 적용할 모드(mode) 문자열 조합.
u,g,o,a: 소유자(u), 그룹(g), 그 외 사용자(o), 모든 사용자(a) 지정.
+,-,=: 현재 모드에 권한 추가(+), 현재 모드에서 권한 제거(-), 현재 모드로 권한 지정(=)
r,w,x: 읽기 권한(r), 쓰기 권한(w), 실행 권한(x)
X: 권한 지정 대상이 실행(x) 권한을 가져도 괜찮은 경우에만 실행 권한을 지정
-- 즉, 기존에 실행(x) 권한이 없던 파일에는 실행(x) 권한을 주고 싶지 않을 때, x (소문자 x) 대신 X (대문자 X)를 사용하는 것
s: 실행 시 사용자 또는 그룹 ID 지정(s). "setuid", "setgid".
t: 공유모드에서의 제한된 삭제 플래그를 나타내는 sticky(t) bit.
0~7: 8진수(octet) 형식 모드 설정 값.//파일이 속한 그룹이 실행할 수 있는 권한 추가. $ chmod g+x FILE //시스템의 모든 사용자가 읽을 수만 있는 권한 지정. $ chmod a=r FILE //파일을 소유한 그룹과 그 외 사용자의 모든 권한 제거. $ chmod go-rwx FILE $ chmod 000 FILE $ chmod 777 FILE $ chmod -R g+x DIR //DIR 디렉토리 하위 모든 파일 및 디렉토리에 그룹 실행(x) 권한 추가. $ chmod -R o-wx * //현재 디렉토리의 모든 파일에서 그외 사용자의 쓰기, 실행 권한 제거 $ chmod -R a-x,a+X * //현재 디렉토리 기준 모든 파일 읽기 권한 제거, 디렉토리 실행 권한 추가. $ chmod -R a-x+X * //위(chmod -R a-x,a+X *)와 동일.
chown: 파일이나 디렉토리의 소유주나 소속 그룹을 변경
$ chown [OPTIONS] USER[:GROUP] FILE(s) //Group을 root로 변경 $ sudo chown :root file1.txt //Owner와 Group을 동시에 변경 $ sudo chown js:js file1.txt //root와 같은 유저 이름(문자열) 대신 유저 아이디(숫자)를 입력 가능 $ chown 1000:1000 file1.txt //-R 사용하면 하위파일들의 소유자들도 함께 변경
chgrp: 파일이나 디렉토리의 소유 그룹을 변경
chown은 소유자와 소유그룹을 한꺼번에 변경할 수 있지만, chgrp는 특정파일이나 디렉터리의 소유 그룹만을 변경할 수가 있다.
touch: 0byte 파일 생성 또는 파일의 시간을 변경
umask: 파일 생성 시 접근권한에 영향을 미침$ umask -- 0022
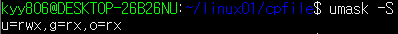
파일 응용
wc: 파일 내 행, 단어, 문자의 수를 출력
$ wc [-clmw][file ....]
기본형식 : wc 옵션 파일이름
파일이름을 입력하지 않으면 표준 입력으로 부터 정보를 받아들여 계산한다.
-l 행
-w 단어
-c 문자
cut: 파일의 행으로부터 특정 바이트나 필드를 추출
$ cut [option][file]
paste: 파일 내 행을 병합할 때 사용
tr: 파일 내 지정 문자를 치환 또는 삭제할 때 사용
sort: 파일을 정렬할 때 사용
split: 파일을 분할할 때 사용
uniq: 파일에서 인접하는 행의 내용을 비교
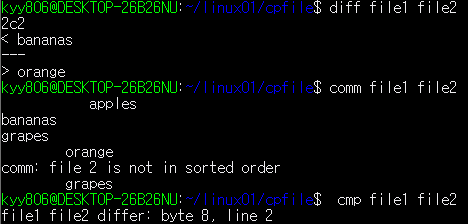
cmp [file][file]: 파일을 비교할 때 사용(다르면 처음 발견한 라인번호와 offset 출력)
몇번째 줄에서 문자열이 서로 다르다고 알려줌
--file1 file2 differ: char 16, line 3
comm [file][file]: 파일을 비교할 때 사용(한쪽에만 있거나 양쪽 모두에 있는 행 출력)
옵션에서 -1, -2, -3을 줄 수 있는데 다음과 같이 사용한다.
-1 : 두 파일을 비교하여 첫번째 파일과 다른 두번째 파일의 내용과 공통 부분
-2 : 두번째 파일과 다른 부분의 첫번째 파일내용과 공통 부분
-3 : 두 파일의 공통된 부분 제외한 나머지 즉 차이 부분
diff [file][file]: 파일이 동일한지 여부를 검사
실행결과 차이점이 없다면 0, 차이점이 있다면 1, 실행시 에러 상황이라면 2 이상의 값을 반환
diff3 [file][file] [file]: 세개의 파일의 차이점을 비교할 수 있다.
grep [option][찾을 문자열 정규 표현식] [file]: 파일 내 특정 패턴이나 문자열을 검색
-c, --count : 파일의 내용 대신 문자열이 들어있는 라인의 수를 출력(3개의 라인에서 매칭된다면 3출력)
-n, --line-number : 문자열이 들어있는 라인과 문두에 라인번호를 출력
-i, --ignore-case : 문자열의 대소문자 구분하지 않음
-l(소문자 L), --files-with-matches : 문자열 을 포함하는 파일의 이름만 출력
-r, --recursive : 서브 디렉토리의 파일까지 모두 출력
-v, --invert-match : 문자열이 제외된, 즉 문자열이 포함되어 있지 않은 라인을 출력
-e PATTERN, --regexp=PATTERN : pattern 에서 찾을 문자열 명시, 패턴으로 PATTERN을 사용("-으로 시작하는 패턴"을 보호하는데 유용)
-w, --word-regexp : pattern 이 전체 단어와 일치하는 줄만 출력, 단어의 일부로써 일치하는 경우가 아닌, 하나의 단어로써 일치하는 줄이 출력.
-x, --line-regexp : pattern 이 전체 줄과 일치하는 줄만 출력
-a, --text : 기본적으로 grep는 바이너리 파일을 처리할 수없다. 그런데 바이너리파일을 텍스트파일처럼 처리할 수있는 옵션이 -a 옵션이다
-A NUM, --after-context=NUM : 패턴매칭라인 이후의 라인을 NUM수만큼 출력
-B NUM, --before-context=NUM : 패턴매칭라인 이전의 내용을 NUM수만큼 출력.
-C NUM, -NUM, --context=NUM : 출력물 앞뒤 전후의 주어진 라인만큼 출력(패턴매칭 라인은 포함하지 않고 기본 2라인)
-b, --byte-offset : 패턴매칭되기전 라인의 바이트수를 출력
///
- $ grep 'app*' [file]
파일에서 app로 시작하는 모든 단어를 찾는다. - $ grep 'a.....e' 파일명
파일에서 a로 시작하고 e로 끝나는 7자리 단어를 찾는다. - $ grep [a-d][file]
파일에서 a,b,c,d로 시작하는 단어를 모두 찾는다. - $ grep [aA]pple [file]
파일에서 apple 또는 Apple로 시작하는 단어를 모두 찾는다. - $ grep 'apple' d*
d로 시작하는 모든 파일에서 apple을 포함하는 모든 행을 찾는다. - $ grep 'apple' [file1][file2]
지정된 두개의 파일에서 apple을 포함하는 모든 행을 찾는다. - $ grep '^[ab]' [file]
파일에서 a나 b로 시작되는 모든 행을 찾는다.
egrep: 정규 표현식 패턴을 검색한다 (grep -E와 동일)
여러개의 문자열을 동시에 찾을 수 있음, grep에서 활용할 수 있는 메타문자 이외에 추가 정규 표현식 메타 문자 지원
fgrep: 단순 패턴을 검색한다 (grep -F와 동일)
문자열로만 검색, 즉 정규표현식의 메타문자도 일반문자로 취급
= 문자열로만 검색하기 때문에 검색 속도가 빠르다는 장점
find [option][path] [표현식]: 파일을 검색할 때 사용
option
-P: 심볼릭 링크를 따라가지 않고, 심볼릭 링크 자체 정보 사용
-L: 심볼릭 링크에 연결된 파일 정보 사용
-H: 심볼릭 링크를 따라가지 않으나, Command Line Argument를 처리할 땐 예외
-D: 디버그 메시지 출력
path
상대 경로 및 절대 경로 모두 가능
표현식
-name : 해당 이름의 파일을 찾음, 해당 이름에는 정규 표현식을 활용할 수 있음
-user : 해당 유저에게 속한 파일을 찾음
-atime : n일 이내에 액세스된 파일을 찾음
-ctime : n일 이내에 만들어진 파일을 찾음
-mtime : n일 이내에 수정된 파일을 찾음
-cnewer file : 해당 파일보다 최근에 수정된 파일을 찾음
-empty: 빈 디렉토리 또는 크기가 0인 파일 검색.
-delete: 검색된 파일 또는 디렉토리 삭제.
-exec: 검색된 파일에 대해 지정된 명령 실행.
-path: 지정된 문자열 패턴에 해당하는 경로에서 검색.
-print: 검색 결과를 출력. 검색 항목은 newline으로 구분. (기본 값)
-print0: 검색 결과를 출력. 검색 항목은 null로 구분.
-size: 파일 크기를 사용하여 파일 검색.
-type: 지정된 파일 타입에 해당하는 파일 검색.
-mindepth: 검색을 시작할 하위 디렉토리 최소 깊이 지정.
-maxdepth: 검색할 하위 디렉토리의 최대 깊이 지정.
//현재 디렉토리에 있는 파일 및 디렉토리 리스트 표
$ find
//대상 디렉토리에 있는 파일 및 디렉토리 리스트 표시
$ find [PATH]
//현재 디렉토리 아래 모든 파일 및 하위 디렉토리에서 파일 검색
$ find . -name [FILE]
//전체 시스템(루트 디렉토리)에서 파일 검색
$ find / -name [FILE]
//파일 이름이 특정 문자열로 시작하는 파일 검색
$ find . -name "STR*"
//파일 이름에 특정 문자열이 포함된 파일 검색
$ find . -name "*STR*"
//파일 이름이 특정 문자열로 끝나는 파일 검색
$ find . -name "*STR"
//빈 디렉토리 또는 크기가 0인 파일 검색
$ find . -empty
//특정 확장자를 가진 모든 파일 검색 후 삭제
$ find . -name "*.EXT" -delete
//검색된 파일 리스트를 줄 바꿈 없이 이어서 출력하기
$ find . -name [FILE] -print0
//파일 또는 디렉토리만 검색하기
$ find . -name [FILE] -type f
//파일 크기를 사용하여 파일 검색
$ find . -size +[N]c -and -size -[M]c
//검색된 파일에 대한 상세 정보 출력. (find + ls)
$ find . -name [FILE] -exec ls -l {} \;
//검색된 파일의 라인 수 출력. (find + wc)
$ find . -name [FILE] -exec wc-l {} \;
//검색된 파일에서 문자열 찾기. (find + grep)
$ find . -name [FILE] -exec grep "STR" {} \;
//검색 결과를 파일로 저장. (find, redirection)
$ find . -name [FILE] > [SAVE_FILE]
//검색 중 에러 메시지 출력하지 않기 (find, redirection)
$ find . -name [FILE] 2> /dev/null
//하위 디렉토리 검색하지 않기
$ find . -maxdepth 1 -name [FILE]
//검색된 파일 복사. (find + cp)
$ find . -name [FILE] -exec cp {} [PATH] \;