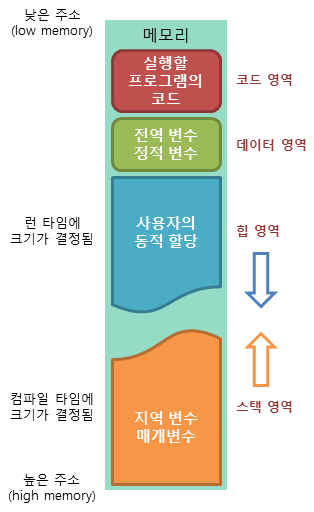
페이지와 페이징
메모리는 비트로 표현하며 보통 1byte가 8bit
워드는 byte로 구성, 페이지는 워드로 구성
페이지: 메모리 관리 유닛에서 관리할 수 있는 최소 단위
가상주소공간은 페이지로 구성
32bit에서는 4KB, 64bit에서는 8KB
유효한 페이지는 물리메모리 또는 스왑 파티션이나 디스크에 저장된 파일과 같은 2차 저장소에 있는 실제 페이지와 연관된다.
-
유효하지 않은 페이지는 실제 물리 메모리와 연관되지 않은, 사용되지 않은 주소일 뿐, 유효하지않은 페이지 접근시 세그멘테이션 폴트 일으킴
-
어떤 유효한 페이지가 2차 저장장치와 연결되어 있다면 그 페이지가 실제 메모리에 올라오기 전에는 프로세스에 접근할 수 없다.(접근시 페이지 폴트 발생)
이 경우 커널은 2차 저장장치에 있는 데이터를 물리 메모리로 페이징
물리 메모리가 가상 메모리보다 훨씬 작기 때문에 커널은 메모리에서 데이터를 페이징 아웃하여 새로운 데이터를 위한 공간을 만들어내야 함
페이징 아웃: 물리 메모리에 저장된 데이터를 2차 저장장치로 옮기는 작업
커널은 페이징에 따른 성능 부하를 줄이기 위해 가까운 미래에 쓰임이 덜 할 것으로 예상되는 데이터를 페이징 아웃함
메모리 영역
커널은 접근 권한과 같은 특정 속성을 공유하는 블록 내부에 페이지를 배열
-
텍스트 세그먼트: 프로세스의 프로그램 코드, 문자열 상수, 상수 변수, 읽기 전용 데이터
리눅스에서 이 세그먼트는 읽기 전용이며 실행 파일이나 라이브러리 오브젝트 파일에서 직접 매핑된다. -
스택 영역: 프로세스의 실행 스택으로 구성, 실행스택은 스택 깊이가 깊어지고 얕아짐에 따라 동적으로 크기가 바뀐다. 실행 스택에는 지역 변수와 함수의 반환 데이터로 구성, 멀티 스레드 프로세스에서는 스레드당 하나의 스택이 존재
-
힙: 프로세스의 동적 메모리로 구성, 이 세그먼트는 쓰기가 가능하고 크기 변경이 가능하다.
-
bss 세그먼트: 초기화되지 않은 잔여 변수 담음
리눅스는 두단계로 변수 최적화
1. 초기화하지 않은 데이터는 전용 공간인 bss 세그먼트에 할당되므로 링커(ld)는 오브젝트 파일에 특수값을 저장하지 않으며 이렇게 해서 바이너리의 크기를 줄인다.
2. 그리고 이 세그먼트가 적재되면 커널은 단순히 이 세그먼트를 copy-on-write 기법을 통해 0으로 채워진 페이지에 맵핑해서 효율적으로 변수에 기본값을 설정한다.
데이터 정렬
데이터 정렬은 메모리에 데이터를 나열하는 방식을 말함
변수가 자신의 크기의 배수가 되는 메모리 주소에 저장되면 이를 자연스럽게 정렬된 상태라고 한다.
ex) 32bit, 즉 4byte 크기의 변수는 4의 배수인 메모리 주소에 위치할 경우 자연스럽게 정렬된 상태
따라서 크기가 2n byte인 타입은 주소에서 최하위 n bit가 0이 되어야한다.
최하위 비트는 이진 정수에서 짝수인지 홀수인지를 결정하는 단위값이 되는 bit 위치
0이면 짝수, 1이면 홀수
흔히 프로그래머는 페이지 같은 더 큰 단위로 정렬된 동적 메모리를 요구
(malloc, calloc, realloc같은 함수는 32bit는 8byte 64bit는 16byte로 정렬됨)
가장 흔한 이유는 직접 블록 입출력이나 소프트웨어와 하드웨어 간의 통신을 위한 버퍼를 적절히 정렬해야 하는 경우
이런 용도에 맞게 POSIX 1003.1d는 posix_memalign()이라는 함수 제공
//둘 중 아무거나 하나만 정의해도 상관없다
#define _XOPEN_SOURCE 600
#define _GNU_SOURCE
#include <stdlib.h>
int posix_memalign(void **memptr, size_t alignment, size_t size);성공시 동적 메모리를 size 바이트만큼 할당하고 alignment의 배수인 메모리 주소에 맞춰 정렬한다.
alignment: 는 2의 거듭제곱이고 void 포인터 크기의 배수여야한다.
할당된 메모리 주소는 memptr에 저장되며 0반환
char *buf;
int ret;
//256바이트에 맞춰 1KB를 할당한다.
ret = posix_memalign(&buf, 256, 1024);
if(ret){
fprintf(stderr, "posix_memalign: %s\n", strerror(ret));
return -1;
}
//buf를 사용
free(buf);valloc, memalign
POSIX에서 posix_memalign() 제공전에 BSD와 SunOS에서 각각 다음 인터페이스 제공했음
#include <malloc.h>
void *valloc(size_t size);
void *memalign(size_t boundary, size_t size);valloc()은 할당된 메모리가 페이지 단위로 정렬된다는 점만 제외하면 malloc과 동작이 같다.
(p가 4k라면, 1k 할당을 요청하면 4k를 할당해주고, 5k를 요청하면 8k를 할당해줌)
(시스템 페이지 크기 가져오기: getpagesize())
memalign()함수는 posix_memalign()함수와 비슷
할당된 메모리가 2의 거듭제곱인 boundary 바이트에 맞춰 정렬
이 두 함수는 예전 시스템과의 이식성을 목적으로만 사용해야한다. 지금까지 소개한 세개의 인터페이스 모두 malloc()이 제공하는 정렬보다 더 큰 정렬이 필요한 경우에만 사용
다른 정렬 고려사항
정렬 고려사항은 표준 타입과 동적 메모리 할당의 자연스러운 정렬을 넘어선다.
예를 들어 비표준이나 복잡한 타입은 표준 타입보다 좀 더 복잡한 요구사항이 존재
또한 정렬 고려사항은 다양한 타입의 포인터 사이에 값을 대입하거나 타입 변환을 사용할 경우 더욱 중요
- 구조체의 정렬 요구사항은 가장 큰 멤버의 타입을 따름
- 구조체는 각 멤버가 그 타입의 요구사항에 맞게 적절히 정렬될 수 있도록 패딩이 필요
- 유니언의 정렬 요구사항은 유니언에 속한 가장 큰 타입을 따름
- 배열의 정렬 요구사항은 기본 타입을 따름
포인터 타입과 관련된 정렬 문제
포인터를 통해 데이터에 접근할 때, 정렬 크기가 작은 블록에서 큰 블록으로 데이터를 읽어오면 프로세스가 제대로 정렬되지 않은 데이터를 더 큰 타입으로 읽어들일 수 있다.char greeting[] = "Ahoy Matey"; char *c =greeting[1]; unsigned long badnews = *(unsigned long *)c;badnews에 c의 값을 대입하면 c를 unsigned long으로 읽으려고 시도한다.
unsigned long은 4byte 혹은 8byte 단위로 정렬된다.
변수 c는 그렇게 정렬되어있지 않다. 따라서 c를 타입 변환하면 정렬이 틀어진다.
-- 아키텍처에 따라 미세한 성능하락에서부터 프로그램이 비정상적으로 종료되는 심각한 현상까지 다양한 결과를 초래한다.
이런 정렬 위반을 감지는 하지만 제대로 다루지 못하는 아키텍처라면 커널은 이 프로세스에 SIGBUS 시그널을 보내서 프로세스를 종료하게 만든다.
엄격한 앨리어싱
객체가 실제 그 객체의 타입, 타입 한정자(const, volatile), 부호(signed, unsigned), 실제 그 타입의 구조체나 유니언 멤버 또는 char 포인터를 통해서만 접근해야한다는 요구사항이다.
예를 들어 uint16_t 포인터를 통해 uint32_t 값에 접근하는 방식은 엄격한 앨리어싱의 위반을 보여주는 흔한 예
요약하면 다른 타입으로 변환한 포인터를 통해 접근하는 방식은 엄격한 앨리어싱 규칙에 어긋난다
데이터 세그먼트 관리하기
유닉스 시스템은 전통적으로 데이터 세그먼트를 직접 관리할 수 있는 인터페이스를 제공하지만 대부분의 프로그램이 이런 인터페이스를 직접 사용하지 않는 이유는 malloc()이나 다른 할당 함수가 더 사용하기 쉽고 강력하기 때문이다.
#include <unistd.h>
int brk(void *end);
void *sbrk(intptr_t inrement);이 함수들의 이름은 힙과 스택이 같은 세그먼트에 존재했었던 옛날 유닉스 시스템을 따라 지어졌다.
힙에서 동적 메모리 할당은 세그먼트의 아래에서 위로 올라가고
스택은 세그먼트의 위에서 힙 위까지 내려간다.
양쪽의 경계선을 break 또는 break point라고 한다.
데이터 세그먼트가 독자적인 메모리 맵핑이 존재하는 최신 시스템에서도 맵핑의 마지막 주소를 브레이크 포인트라고 부른다.
brk() 호출시 데이터 세그먼트의 마지막인 브레이크 포인트를 end로 지정한 주소로 설정함
성공시 0, 실패시 -1/errno=ENOMEM
sbrk() 호출시 데이터 세그먼트를 increment만큼 늘림(양수나 음수도 가능)
sbrk()는 새로 갱신된 브레이크 포인트를 반환
따라서 increment에 0을 넘기면 현재 브레이크 포인트를 출력
참고
익명 메모리 맵핑
malloc()구현 전통적 방법
- 데이터 세그먼트를 2의 배수만큼의 구역으로 나눈 다음에 요청하는 크기에 가장 가까운 크기의 구역을 반환하는 것
- 메모리 해제는 이 구역을 '비어있음'으로 표시하면 됨
- 인접한 구역이 비어 있을 경우 하나로 합쳐서 좀 더 큰 구역을 확보할 수 있다.
- 힙의 윗 부분이 완전히 비어있다면 brk()를 사용해서 브레이크 포인트를 낮춰 힙을 줄이고 메모리를 커널에게 반환함
이런 알고리즘을 buddy 메모리 할당 기법이라고 함 - 속도와 명료함이라는 장점, 두종류의 파편화(fragmentaiton)가 발생하는 단점
메모리 단편화
RAM에서 메모리의 공간이 작은 조각으로 나뉘어져 사용가능한 메모리가 충분히 존재하지만 할당이 불가능한 상태
내부 파편화
메모리 할당 요청을 충족시키기 위해 요청보다 더 많은 메모리를 반환할 때 일어남 => 비효율적
ex) 4kb 할당해줬는데 1kb만큼만 사용하고 있을 때 내부 파편화가 3kb만큼 생긴 것
외부 파편화
요청을 충족시킬만한 메모리가 남아있지만 인접하지 않은 둘 이상의 구역으로 떨어져 있을 때 발생 => 더 큰 메모리를 할당하기 떄문에 비효율적, 다른 대안 없을 경우 메모리 할당 실패 가능
ex) 메모리 처음 주소에 8mb짜리 프로세스가 할당되었고 바로 이어서 16mb짜리 프로세스가 할당되었다고 가정했을 때 8mb짜리 프로세스를 종료시키면 메모리 처음 주소부터 8mb만큼 공간이 생긴다. 이런식으로 계속해서 빈 메모리가 쌓이는데 예를 들어서 빈 메모리의 공간중에 제일 큰 빈 메모리가 8mb라고 한다면 9mb짜리 프로세스를 할당해야할 때 마땅한 공간은 없지만 전체적으로 메모리 여유는 있을 때 외부파편화가 생겼다고 한다. - 더욱이 이런 방법은 한 번의 메모리 할당이 다른 메모리 할당을 고정시켜서 c라이브러리가 커널에 해제된 메모리를 반환하지 못하도록 방해
ex) 메모리 블록 A와 B가 할당되어 있을 때
블록 A는 브레이크 포인트 바로 아래에 위치, 블록 B는 블록 A 바로 아래에 위치
프로그램이 B를 해제해도 c라이브러리는 A가 해제되기 전까지는 브레이크 포인트를 변경할 수 없다.(이런식으로 오래 남아있는 블록은 메모리 내에서 다른 블록을 고정시킨다.)
일반적으로 힙은 매번 해제가 일어날 때마다 줄어들지 않는다. 대신 malloc()구현은 연이은 할당을 위해 해제된 메모리를 보존한다. 힙 크기가 할당된 메모리의 총합보다 훨씬 더 큰 경우에만 malloc()은 데이터 세그먼트를 줄인다. 하지만 대규모 메모리 할당은 이렇게 데이터 세그먼트를 줄이지 못하도록 방지할 수 있다.
따라서 대규모 메모리 할당에서 glibc는 힙을 사용하지 않는다.
그 대신 glibc는 익명 메모리 맵핑을 사용해서 메모리 할당 요청에 대응한다. 익명 메모리 할당은 4장에서 설명한 파일 기반 맵핑과 유사하지만 파일과 연관되지 않기 때문에 '익명'이라고 한다.
익명 메모리 맵핑은 그저 사용하기 위해 준비된 크고 0으로 채워진 메모리 블록이다,
익명 메모리 맵핑을 단일 할당만을 위한 새로운 힙이라고 생각하자. 이런 맵핑은 힙 영역 밖에 위치하기 때문에 데이터 세그먼트의 파편화를 일으키지 않는다.
장점
- 파편화 신경쓰지 않아도 된다. 프로그램에서 더 이상 익명 메모리 맵핑을 필요로 하지 않는다면 맵핑을 해제하면 메모리는 즉시 시스템으로 반환된다.
- 익명 메모리 맵핑은 크기 조정이 가능하고 권한 설정이 가능하며 일반 맵핑과 마찬가지로 힌트를 사용할 수 있다.
- 개별 메모리 할당이 독립된 메모리 맵핑에 존재. 전역 힙을 관리할 필요가 없다.
단점
- 각 메모리 맵핑의 크기는 시스템 페이지 크기의 정수배가 된다. 이 때문에 페이지 크기의 정수배로 떨어지지 않는 할당 요청은 공간을 낭비한다.
- 힙에서 메모리를 할당받는 것은 커널의 개입이 전혀 없으므로 새로운 메모리 맵핑을 생성하는 데 드는 부하가 더 많이 걸린다. 역시 할당 크기가 작을수록 이런 부하가 더 두드러진다.
stack heap 높은주소 -> 낮은 주소 낮은 주소 -> 높은 주소 지역 변수 전역 변수 정적 메모리 동적 메모리 컴파일 시 할당 런타임 시 할당 자동으로 할당/해제 사용자가 직접 관리
스택 영역: 메모리의 높은 주소에서 낮은 주소의 방향으로 할당
멀티스레드 프로세스에서는 스레드 당 하나의 스택이 존재
힙 영역: 메모리의 낮은 주소에서 높은 주소의 방향으로 할당
프로세스의 동적 메모리로 구성
이 세그먼트는 쓰기가 가능하고 크기 변경이 가능, malloc()은 이 영역에 메모리를 할당
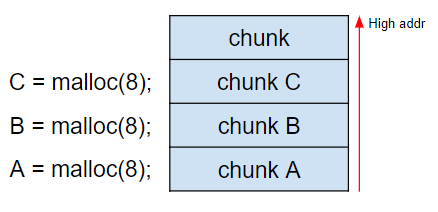
<chunk>
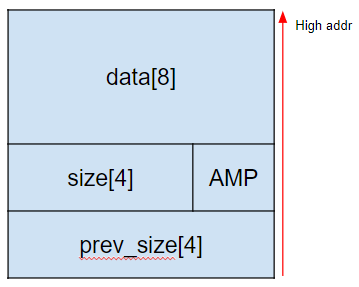
변수를 malloc()하게 되면 힙 메모리에는 |prev_size size data|로 나타나는데 이 묶음을 chunk라고 부른다.
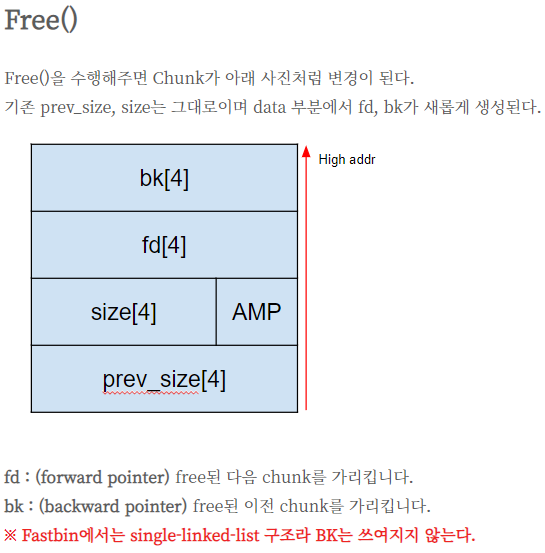
prev_size: 이전 chunk의 크기를 나타내주며 free() 시에 생성됨 (당연히 첫 chunk는 이전 chunk가 없기에 0이 들어가있음)
size: 현재 chunk의 크기를 담고 있으며 malloc() 시에 생성됨
AMP: 플래그 필드이며 각 플래그는 아래와 같습니다.
- A : NON_MAIN_ARENA multi thread application에서 각 thread 마다 다른 heap 영역을 사용하는 경우 현재 chunk가 main heap(arena)에 속하는지 여부를 나타냅니다.
(main heap = 0 / mmap’d memory = 1)- M : IS_MMAPPED chunk 자체가 단일 mmap() 시스템 콜을 통해 할당되었을 때 셋팅된다
- P : PREV_INUSE 이전 chunk의 상태를 나타내줌
(chunk using = 1 / chunk free = 0)
data: 실제로 데이터가 들어가는 영역
익명 메모리 맵핑 생성하기
#include <sys/mman.h>
void *mmap(void *start,
size_t length,
int prot,
int flags,
int fd,
off_t offset);
int munmap(void *start, size_t length);익명 메모리 맵핑은 파일을 열고 관리할 필요가 없기 때문에 파일 기반 맵핑보다 더 생성하기 쉽다. 둘의 가장 큰 차이점은 익명 맵핑이라는 것을 알려주기 위한 특수한 플래그의 유무다.
void *mmap(NULL, //위치는 신경쓰지 않는다.
512 * 1024, //512KB
PROT_READ|PROT_WRITE, //읽기/쓰기
MAP_ANONYMOUS|MAP_PRIVATE, //익명, 공유하지 않음
-1,
0);
if (p == MAP_FAILED)
perror("mmap");
else
//p는 512KB의 익명 메모리를 가리킨다.
int ret;
ret = munmap(p, 512 * 1024);
if(ret)
perror("munmap");- 첫번째 인자 start: 는 익명 맵핑이 커널이 바라는 메모리 위치 어디서든 시작할 수 있음을 나타내는 NULL로 설정, NULL이 아니어도 되지만 이식성이 떨어진다.
- prot인자: 는 일반적으로 읽고 쓰지 못할 때 비어있는 맵핑은 쓸모가 없다. 반면에 익명 맵핑에서 코드를 실행하는 경우는 바람직하지 않으며 코드를 실행하도록 허용한다면 공격자가 공격할 수 있는 허점을 제공한다.
- flags 인자는 MAP_ANONYMOUS 비트를 설정해서 익명으로 맵핑을 생성하도록하며 MAP_PRIAVTE비트를 설정해서 공유되지 않도록 한다.
- MAP_ANONYMOUS 비트가 설정되면 fd와 offset 인자는 무시된다. 하지만 일부 오래된 시스템에서는 fd값을 -1로 기대하므로 이식성을 고려하여 -1 넘김
0으로 이미 채워져 있는 페이지로 맵핑하여 추가적인 memset() 수행 필요 없음
/dev/zero 맵핑하기
BSD같은 다른 유닉스 시스템에는 MAP_ANONYMOUS 플래그가 없다. 대신 /dev/zero 파일을 맵핑하는 방법으로 유사한 해법을 구현한다.
이 특수 디바이스 파일은 익명메모리와 의미가 같다.(0으로 채워진 메모리로 맵핑하는 기능)
#include <sys/mman.h>
#include <stddef.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
int main(){
void *p;
int fd;
// /dev/zero 파일을 읽기 쓰기 모드로 연다
fd = open("/dev/zero", O_RDWR);
if(fd < 0){
perror("open");
return -1;
}
// /dev/zero를 [0, 페이지 크기)로 맵핑함
p = mmap(NULL, getpagesize(), PROT_READ|PROT_WRITE, MAP_PRIVATE, fd, 0);
if(p == MAP_FAILED){
perror("mmap");
if(close(fd))
perror("close");
return -1;
}
if(close(fd))
perror("close");
int ret;
ret = munmap(p, getpagesize());
if(ret)
perror("munmap");
}이런 접근 방식은 디바이스 파일을 열고 닫기 위한 추가적인 시스템 호출이 필요하다.
따라서 익명 메모리 맵핑이 더 빠른 해법이다.
고급 메모리 할당
#include <malloc.h>
int mallopt(int param, int value);호출시 param으로 지정한 메모리 관리와 관련된 인자를 value로 설정한다.
성공시 0이 아닌 값, 실패시 0(errno 설정x)
mallopt()는 반드시 malloc()이나 다른 메모리 할당 인터페이스를 사용하기 전에 호출해야한다.
param
- M_CHECK_ACTION
MALLOCCHECK 환경변수 값: 힙 데이터 구조 일관성 검사를 시행
0: 아무것도 수행 하지 않고, 프로그램이 동작(무시)
1: 에러 메시지가 출력(stderr), 프로그램은 계속 동작
2: 아무런 메시지 없이 프로그램이 종료(abort(): 즉시 종료)
3: 에러 메시지를 출력하고 프로그램이 종료
- M_MMAP_MAX
시스템이 동적 메모리 요청을 위해 생성할 수 있는 최대 맵핑 개수
이 한계에 도달하면 맵핑 중 하나를 해제하기 전까지는 데이터 세그먼트를 사용하여 할당을 처리
이 값이 0이면 동적 메모리 할당을 위해 익명 맵핑을 사용하지 않는다.- M_MMAP_THRESHOLD
데이터 세그먼트를 대신해서 익명 맵핑으로 처리할 할당 요청의 임계 크기를 바이트 단위로 지정한다.
이 임계값보다 작은 할당 요청은 맵핑을 사용한다.
이 값으로 0을 설정하면 동적 메모리 할당을 위해 익명 맵핑을 사용하여 결과적으로 데이터 세그먼트를 사용하지 않는다.- M_MXFAST
fast bin의 최대 크기
값으로 0을 넘기면 패스트 빈을 사용하지 않는다.
패스트 빈
힙에 존재하는 특수한 메모리 영역으로 인접한 메모리 블록과 합쳐지지 않으며 시스템에 반환되지도 않기 때문에 파편화가 늘어나지만 빠른 할당이 가능하다.
청크의 크기가 16~80 byte인 경우, fast chunk라고 부릅니다. fast chunk를 수용한 bin을 fast bin이라고 부릅니다. 모든 bin들 중 가운데, fast bin은 메모리 할당과 해제가 빠릅니다.- M_PERTURB
메모리 관리 에러를 탐지하는 데 도움이 되는 메모리 포이즈닝을 활성화한다.
값으로 0이 아닌 값이 설정되면 glibc는 calloc()으로 할당된 영역을 제외한 모든 바이트를 value 값의 최소 유효 비트의 논리 보수로 설정한다.
또한 glibc는 해제된 모든 바이트를 value 값의 최소 유효 비트로 설정한다.
이는 해제된 메모리를 사용하는 에러를 찾는데 도움을 준다.
메모리 포이즈닝
메모리 영역을 특정 값으로 미리 저의한 쓰레기 값으로 채워 메모리 오류나 잘못된 접근을 탐지하기 위해 사용되는 기법- M_TOP_PAD
데이터 세그먼트 크기를 조정할 때 사용되는 패딩의 크기(바이트)다. glibc가 brk()를 사용해서 데이터 세그먼트의 크기를 키울 때 마다 추가적인 brk() 호출이 일어나질 않기를 바라면서 필요한 것 보다 더 많은 메모리를 요청한다.
유사하게 glibc가 데이터 세그먼트의 크기를 줄일 경우에는 실제보다 조금 덜 반환하는 방법으로 여분의 메모리를 유지한다. 이런 여분의 바이트가 패딩이다. 값으로 0 넘기면 패딩 비활성화- M_TRIM_THRESHOLD
glibc가 sbrk() 호출해서 메모리 커널에 반환하기 전에 데이터 세그먼트의 빈 메모리의 최소크기(바이트)
malloc_usable_size()와 malloc_trim()으로 튜닝하기
size_t malloc_usable_size(void *ptr);호출 성공시 ptr이 가리키는 메모리 영역의 실제 할당 크기를 return
glibc는 기존의 블록이나 익명 맵핑에 맞도록 할당 크기를 올림처리하므로 할당 영역에서 사용 가능한 공간은 요청한 크기보다 더 클 수 있다.당연히 할당 크기가 요청 크기보다 작은 경우는 없다.
size_t len = 21;
size_t size;
char *buf;
buf = malloc(len);
if(!buf){
perror("malloc");
return -1;
}
size = malloc_usable_size(buf);
//실제로는 buf에서 size 바이트만큼 사용할 수 있다
printf("len: %ld, real malloc: %ld\n", len, size);
//len: 21, real malloc: 24int malloc_trim(size_t padding);호출 성공시 유지되어야 하는 패딩 바이트를 제외한, 가능한 많은 데이터 세그먼트를 줄이고 1을 반환, 실패시 0
M_TRIM_TRESHOLD바이트에 도달하면 자동으로 데이터 세그먼트를 줄이는 작업을 수행한다. 패딩 값으로는 M_TOP_PAD값 사용
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <malloc.h>
void Insert(){
char szBuf[1024];
FILE * fd = fopen("test", "r");
if(fd == NULL){
printf("fopen error\n");
return;
}
fclose(fd);
}
int main( int argc, char * argv[] ){
Insert();
printf("before malloc trim\n");
malloc_stats();
malloc_trim(0);
printf("after malloc trim\n");
malloc_stats();
}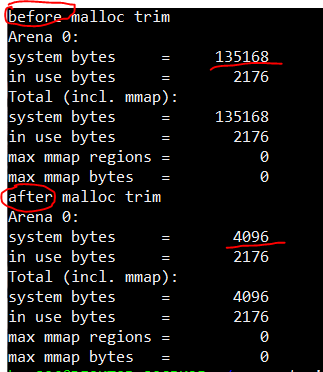
유지되어야 하는 패딩 바이트를 제외한 가능한 많은 데이터 세그먼트를 줄임
-- 디버깅하거나 공부목적 아니면 두 함수 쓸일 없다. 이식성 떨어지며 glibc의 메모리 할당 시스템의 세부 내용을 프로그램에 저수준까지 노출하기 때문
메모리 할당 디버깅
MALLOCCHECK 환경변수를 설정해서 메모리 서브 시스템의 고급 디버깅 기능을 활성화할 수 있다
환경 변수로 디버깅을 제어하므로 프로그램을 다시 컴파일할 필요는 없다
$ MALLOC_CHECK_=1 ./rudderMALLOCCHECK를
0: 아무것도 수행 하지 않고, 프로그램이 동작(무시)
1: 에러 메시지가 출력(stderr), 프로그램은 계속 동작
2: 아무런 메시지 없이 프로그램이 종료(abort(): 즉시 종료)
3: 에러 메시지를 출력하고 프로그램이 종료
통계 수집하기
struct mallinfo mallinfo(void);mallinfo()를 호출하면 mallinfo 구조체에 통계를 담아 반환
struct mallinfo {
int arena; //malloc이 사용하는 데이터 세그먼트의 크기
int ordblks; //비어 있는 메모리 블록 수
int smblks; //패스트 빈 수
int hblks; //익명 맵핑 수
int hblkhd; //익명 맵핑 크기
int usmblks; //전체 할당 최대 크기
int fsmblks; //사용 가능한 패스트 빈의 크기
int uordblks; //전체 할당 공간의 크기
int fordblks; //사용 가능한 메모리 블록의 크기
int keepcost; //정리가 가능한 공간의 크기
};void malloc_stats(void);메모리를 많이 쓰는 프로그램에서 malloc_stats()를 호출하면 큰 수를 출력
스택 기반 할당
void *alloca(size_t size);호출 성공시 size 바이트 크기만큼 할당한 메모리에 대한 포인터를 반환한다.
이 메모리는 스택에 위치하며 실행 중인 함수라 반환될 때 자동으로 해제된다.
실패시 NULL 반환(스택 오버플로우 일으킴)(대부분의 alloca() 구현은 실패하지 않거나 실패를 알리지 못함)
int open_sysconf(const char *file, int flags, int mode){
const char *etc = SYSCONF_DIR; //etc
char *name;
//alloca()로 할당한 메모리는 스택이 실행 중인 함수로 되돌아가면서 자동적으로 해제된다.
//이는 alloca()를 호출한 함수가 반환되면 이 메모리를 사용할 수 없다는 뜻
name = alloca(strlen(etc) + strlen(file) + 1);
strcpy(name, etc);
strcat(name, file);
return open(name, flags, mode);
}//malloc으로 구현한 같은 함수
int open_sysconf(const char *file, int flags, int mode){
const char *etc = SYSCONF_DIR; //etc
char *name;
int fd;
name = malloc(strlen(etc) + strlen(file) + 1);
if(!name){
perror("malloc");
return -1;
}
strcpy(name, etc);
strcat(name, file);
fd = open(name, flags, mode);
free(name);
return fd;
}alloca()로 할당한 메모리를 함수 호출 시 인자로 넘기면 안된다는 사실을 기억하자
ex) ret = foo(x, alloca(10)); //금지!
- 작고 고정된 크기의 스택을 가지는 시스템에서 alloca()사용시 스택 오버플로 발생시켜 프로그램 쉽게 죽임
- 버그 많고 일관성 없는 구현
- 프로그램 호환성위해 사용하지 않는 편이 좋다.
- 그러나 작은 메모리 할당이 필요하다면 alloca() 사용해서 놀라운 성능 향상을 얻을 수 있다.
스택에서 문자열 복사
char *dup;
dup = alloca(strlen(song) + 1);
strcpy(dup, song);
//dup은 자동 해제
return;alloca()를 통해 얻을 수 있는 속도상 이점 때문에 리눅스 시스템은 스택에 문자열을 복사하는 strdup()함수군을 제공하고 있다.
//문자열 s를 복사한 다음 반환
char *strdupa(const char *s);
//문자열 s의 처음 n자까지 복사, s가 n보다 더 길면 n까지만 복사 후 마지막에 NULL 바이트 하나 추가
char *strndupa(const char *s, size_t n);
//복사된 문자열은 호출하는 함수가 반환될 때 자동으로 해제가변 길이 배열
c99는 컴파일 시점이 아니라 실행중에 배열의 크기를 결정하느 가변 길이 배열을 도입함
for(i=0; i<n; ++i){
char foo[i+1];
//i+1크기의 배열
//매 루프마다 foo를 동적으로 생성하며 스코프를 벗어나면 자동적으로 해제
}int open_sysconf(const char *file, int flags, int mode){
const char *etc; = SYSCONF_DIR; //etc
char name[strlen(etc) + strlen(file) + 1];
strcpy(name, etc);
strcat(name, file);
return open(name, flags, mode);
}- alloca()와 가변 길이 배열의 주된 차이점 alloca()로 얻은 메모리는 함수 주기 동안 유지되지만 가변 길이 배열로 얻은 메모리는 함수가 끝나는 시점이 아니라 변수가 스코프를 벗어날 때까지만 유지된다는 점
장점: 루프 돌 때마다 메모리 회수하여 메모리 낭비 없음
단점: 단일 루프 주기보다 더 오랫동안 메모리를 유지해야할 경우 alloca()가 더 합리적
메모리 조작하기
strcmp()나 strcpy() 같은 문자열 조작 인터페이스와 여러가지로 유사하게 동작하지만 문자열이 NULL로 끝난다고 가정하는 대신 사용자가 제공한 버퍼크기에 의존
바이트 설정하기
#include <string.h>
void *memset(void *s, int c, size_t n);s에서 시작해서 n바이트만큼 c바이트로 채운 다음 s를 반환
주로 메모리 블록을 0으로 채울 때 많이 사용
//[s, s+256) 영역을 0으로 채운다
memset(s, '\0', 256);#include <strings.h>
//BSD에서 memset과 같은 역할, 이식성을 위해 남겨둔거
void bzero(void *s, size_t n);
bzero(s, 256);바이트 비교하기
int memcmp(const void *s1, const void *s2, size_t n);이 함수를 호출하면 s1과 s2의 처음 n바이트를 비교하고 두 영역이 동일하면 0을 반환
s1 < s2 음수, s1 > s2 양수
//BSD에서 memcmp와 같은 역할
int bcmp(const void *s1, const void *s2, size_t n);동일하면 0, 아니면 0이 아닌 값
구조체 패딩 때문에 memcmp(), bcmp()로 두 구조체가 동일한지 비교하는 것은 신뢰할 수 없다.
패딩에 초기화되지 않은 값이 들어 있어서 실제로 두 구조체의 멤버가 같을지라도 다르다고 판단할 수 있다.int compare_dinghies(struct dinghy *a, struct dinghy *b){ return memcmp(a, b, sizeof(struct dinghy)); }대신 구조체를 비교하고 싶다면 그 구조체의 개별 멤버끼리 비교
안전하지 않은 memcmp()를 그냥 사용하는 것보다 확실히 더 많은 코드를 필요로함int compare_dinghies(struct dinghy *a, struct dinghy *b){ int ret; // if(a->nr_oars < b->nroars) return -1; if(a->nr_oars < b->nroars) return 1; // ret = strcmp(a->boat_name, b->boat_name); if(ret) return ret; // //다른 멤버 계속 비교 }
바이트 옮기기
📌memcpy()는 어디 거치지 않고 그 위치에 복사해서 붙여넣음
memmove()는 그것보다는 안전하게, 복사할 것을 버퍼에 복사하고 해당 위치에 가서 버퍼에 복사된 것을 붙여넣는 식으로 동작이 구현되어있음
void *memmove(void *dst, const void *src, size_t n);src의 처음 n바이트를 dst로 복사하고 dst 반환
//BSD에서 memmove 같은 역할
void bcopy(const void *src, void *dst, size_t n);두 함수는 같은 인자를 받긴하지만 그 순서가 다른 점 주의
bcopy(), memmove() 모두 중첩되는 메모리 영역을 안전하게 다룬다.
메모리 바이트를 특정 영역 안에서 위나 아래로 이동할 수 있게 만듬
이런 경우는 흔치 않지만, 이런 동작 방식을 피해야할 때 사용하는
중첩된 메모리 영역을 지원하지 않는
void memcpy(void *dst, const void *src, size_t n);만약 dst와 src가 중첩된다면 결과 보장 x
void *memccpy(void *dst, const void *src, int c, size_t n);src 첫 n바이트 내에서 c바이트를 발견하면 복사를 멈춘다는 차이를 제외하면 memcpy()와 동일
dst에서 c의 다음 바이트를 가리키는 포인터를 반환하거나 찾지 못하면 NULL 반환
메모리 쭉 따라가려면
void *mempcpy(void *dst, const void *src, size_t n);mempcpy()는 memcy()와 동일하게 동작하지만 마지막 바이트를 복사한 후에 다음 바이트를 가리키는 포인터를 반환
여러 데이터를 연속적인 메모리 위치에 모아야 할 경우 유용하지만
단순히 dst+n을 반환하기 때문에 눈에 띄는 개선은 없다.
바이트 탐색하기
void *memchr(const void *s, int c, size_t n);s가 가리키는 메모리의 n바이트 범위에서 unsigned char 문자 c를 탐색한다.
#define _GNU_SOURCE
void *memrchr(const void *s, int c, size_t n);c와 일치하는 첫 바이트를 가리키는 포인터를 반환, 실패시 NULL
memchr()과 동일하지만 시작지점부터 찾는게 아니라 s가 가리키는 메모리의 뒤에서부터 n바이트 범위에서 탐색 시작, GNU의 확장이며 c언어의 일부가 아님
좀 더 복잡한 탐색을 위한 괴상한 이름의 memmem() 함수는 임의 바이트 배열에서 메모리 블록을 탐색
#define _GNU_SOURCE
void *memmem(const void *haystack,
size_t haystacklen,
const void *needle,
size_t needlelen);길이가 haystacklen 바이트인 메모리 블록 haystack 내부에서 길이가 needlelen 바이트인 서브 블록 needle의 첫 번째 위치를 가리키는 포인터를 반환
실패시 NULL
- GNU 확장
바이트 섞기
#define _GNU_SOURCE
void *memfrob(void *s, size_t n);s에서 시작하는 메모리의 처음 n바이트를 숫자 42와 XOR 연산을 통해 이상한 값으로 바꾼 후 s를 반환
이렇게 반환된 메모리 영역을 memfrob()에 다시 넘기면 원래 내용으로 돌아옴
따라서 아래 코드는 보안 관점에서 아무것도 하지 않은 것과 같다.
memfrob(memfrob(secret, len), len);-- 이 함수는 암호화 함수가 아니라 문자열을 알아보기 어렵게 바꾸는 정도로 사용해야함
메모리 락 걸기
애플리케이션이 시스템의 페이징 동작 방식에 영향을 미치기를 원하는 두가지 상황
-
결정성
시간 제약이 있는 애플리케이션은 결정론적인 동작을 필요로 한다.
어떤 메모리 접근이 페이지 폴트를 일으킨다면 페이지 폴트는 디스크 입출력 연산을 발생시키므로 애플리케이션은 시간 제한을 넘긴다.
필요한 페이지가 항상 물리 메모리에 존재하고 절대 디스크로 페이징되지 않도록 해서 그 메모리 접근이 페이지 폴트를 일으키지 않게 일관성과 결정성을 보장하며 성능을 개선할 수 있다. -
보안
중요한 내용을 메모리에 저장했는데 이런 내용이 암호화되지 않은 디스크로 페이징될 수 있다.
예를 들어 사용자의 개인 키는 일반적으로 암호화된 상태로 저장되지만 메모리에 있던 암호화되지 않은 복사본이 스왑파일로 저장될 수도 있다.
이런 경우 애플리케이션에서 키를 담고 있는 메모리 영역을 항상 물리 메모리에 위치하도록 요구할 수 있다.
커널의 페이징 동작방식을 변경하면 전반적인 시스템 성능에 나쁜 영향
이렇게 하면 한 애플리케이션의 결정성이나 보안을 향상할 수 있지만 페이지가 메모리에 잠겨있으므로 다른 애플리케이션의 페이지가 디스크로 페이징될 수 있다.
따라서 커널 동작방식을 변경하면 최적이 아닌 다른 페이지를 스왑아웃할 가능성이 있다.
일부 주소 공간 락 걸기
int mlock(const void *addr, size_t len);[addr, addr+len) 바이트의 가상 메모리를 물리 메모리로 잠근다.
성공시 0, 실패시 -1/errno
//암호화된 문자열을 메몸리에 저장하는 프로그램 예제
int ret;
//메모리에서 secret을 락 건다
ret = mlock(secret, strlen(secret));
if(ret)
perror("mlock");전체 주소 공간 락 걸기
int mlockall(int flags);현재 프로세스 주소 공간에 있는 모든 페이지를 물리 메모리에 잠금
flags
MCL_CURRENT
이 값을 설정하면 mlockall()은 현재 맵핑된 페이지(스택, 데이터
메모리락 해제하기
POSIX는 물리메모리에서 페이지의 락을 해제해서 커널이 필요한 경우 그 페이지를 디스크로 페이지 아웃할수 있도록 두가지 인터페이스를 정의한다.
#include <sys/mman.h>
int munlock(const void* addr,size_t len);
int munlockall(void);munlock()시스템콜은 addr에서 시작해서 len 바이트만큼 확장된 페이지의 락을 해제한다. 이 호출mlock()에 대응하는 함수다. munlockall()은 mlockall()에 대응하는 함수다. 두 함수 모두 호출이 성공하면 0을 반환하고 실패하면 -1을 반환한다.
메모리 락은 중첩되지 않는다. 따라서 mlock()이나 mlockall()을 여러 번 호출해서 잠궜더라도 munlock()이나 munlockall()을 한번만 호출하면 잠긴 페이지가 풀린다.
락 제약
메모리락은 시스템 전반적인 성능에 영향을 미치므로 너무 많은 페이지를 락 걸면 메모리 할당이 실패할 수 있다. 리눅스 프로세스에서 얼마나 많은 페이지를 락 걸수 있는지 제한을 두고 있다.
CAP_IPC_LOCK기능을 가진 프로세스는 페이지 수에 제약 없이 메모리를 락 걸수 있다.
하지만 이 기능 없는 프로세스는 RLIMIT_MEMLOCK 바이트만 락 걸수 있다. 기본적으로 이 리소스 제한은 32KB이며, 한 두개 정도 락을 걸만한 크기이지만 시스템 성능에 영향을 미칠만큼 크지는 않다.
페이지가 물리 메모리에 존재하는지 확인
#include <unistd.h>
#include <sys/mman.h>
int mincore(void* start,size_t length,unsigned char* vec);mincore()를 호출하면 시스템 콜을 호출하는 시점에 물리 메모리에 맵핑된 페이지를 기술하는 벡터를 제공한다.
start: 시스템 페이지 크기의 배수
-> 페이지 크기: sysconf(_SC_PAGESIZE)로
length: 페이지 크기 다음 배수로 올림됨
vec: 적어도 (length+PAGE_SIZE-1)/PAGE_SIZE 바이트를 담은 배열에 대한 포인터, 반환된 벡터는 vec에 저장
-> 상주하고 있으면 대응 바이트의 최하위 비트, 상주하지 않으면 해제
그 페이지가 물리메모리에 위치하다면 각 바이트의 최하위 비트는 1이며, 그렇지 않다면 0이다.
static
//정적 변수는 초깃값을 지정하지 않으면 0이 들어감
전역변수에 static을 붙이면 변수의 범위를 파일 범위로 제한
int main(){
static int num;
}
//정적변수는 사라지지 않고 유지되므로 값이 계속 증가함
#include <stdio.h>
void increaseNumber(){
static int num1 = 0;
printf("%d\n", num1);
num1++;
}
int main(){
increaseNumber(); // 0
increaseNumber(); // 1
increaseNumber(); // 2
increaseNumber(); // 3
return 0;
}static을 붙인 정적 함수는 그 파일 안에서만 사용할 수 있다.
정적 함수를 사용하면 같은 이름을 가진 함수를 파일마다 만들 수 있다.
따라서 정적함수는 기능이 여러파일로 분리되어 있을 때 각 파일 안에서만 사용하는 기능을 구현할 수 있다.
