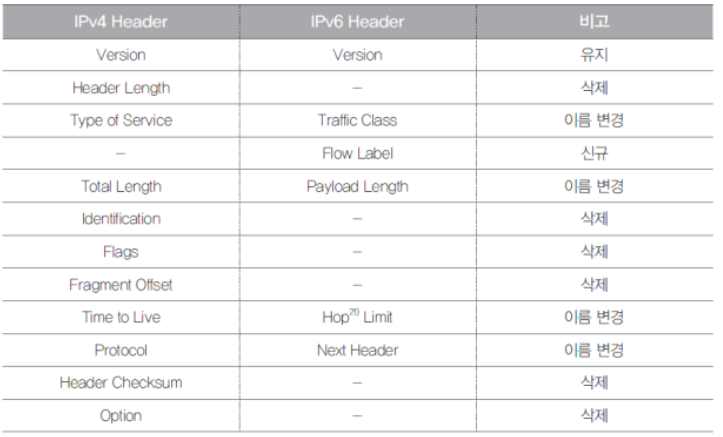
header
IPv4
-
header length
IPv4에서 header의 크기가 최소 20bytes 에서 최대 60bytes
이처럼 IPv4 header 크기는 가변적이기 때문에 꼭 필요했다.
하지만 IPv6 header의 크기는 고정(320bit)이기 때문에 더 이상 header length 필요하지 않게됨 -
Identification, Flags, Fragment Offset
Identification, Flags, Fragment Offset는 router가 IPv4 Packet를 Fragmentation(분할)할 때 사용되는 Field들이다.
하지만 IPv6 Network에 들어서 Router가 Fragmentation를 할 필요가 없어졌습니다.
Fragmentation, Segmentation
MTU 보다 큰 데이터그램은 전송이 불가능 하기 때문에 MTU 보다 작은 크기로 만들어 주는 과정이다.
- Header Checksum
IPv4 Network의 Link간 오류 정정을 Router가 수행
전송 기술이 급격하게 발전하면서 Link간에 Packet 전송이 거의 Error 없이 전달하고 있으며, 게다가 Layer 2에서 이미 CRC Error를 체크하여 Error가 포함된 Packet은 삭제하고 있기 때문에 IP Layer에서 다시 중복적으로 Header Checksum Field를 이용하여 확인할 필요성이 없어졌다.
따라서 IPv6에서는 이러한 불필요한 Router의 부하를 줄이기 위해서 Header checksum Field를 삭제
IPv6
-
Version (4 bits)
IP Packet의 Version를 나타내는 Field입니다. 당연히 IPv6 Header에서는 숫자 6이 기입이 됩니다. -
Traffic Class (8 bits)
IPv4 Header의 “Type of Service” Field가 바뀐 것
IPv6 Packets중 QoS(Quality of Service)를 보장해줘야 할 필요성이 있는 Packet과 그렇지 않은 Packet를 구별할 때 쓰임 -
Flow Label (20 bits)
IPv6에서 새로 생긴 Field
아직 Flow Label 기능이 적용이 안된 장비들이 있으며 , 그런 장비에서 IPv6 Packet 를 생성하거나 처리 할 때, 모두 Flow Label Field를 ‘0’로 세팅
==>
Real-Time Traffic 처럼 매우 중요도가 높은 Traffic을 기타 다른 Packet(ex> 일반 인터넷 데이터)들 보다 더 빨리 처리하기 위해 만든 것 -
Payload Length (16 bits)
IPv4 Header의 "Total Length" Field가 "Payload Length" Field로 이름수정
IPv4의 "Total Length"는 Header와 Payload 의 크기를 합한 반면에 IPv6의 "Payload Length" 는 순수하게 (IPv6 기본 Header 뒷부분에 따라오는) Payload의 크기만 -
Next Header (8 bits)
IPv4 에서의 "Protocol Type" Field가 "Next Header" Field로 이름수정 -
Hop Limit (8 bits)
IPv4 에서의 "Time to Live" Field의 용도와 비슷Time to Live
패킷이 방문할 최대 라우터(hop)의 수
IPv6 Packet이 Router를 거칠 때 마다, Hop Limit Field의 숫자가 1씩 감소
Router는 자신이 수신한 Packet를 Routing 하기전에 Hop Limit Field 값을 조사하게 되는데, 만약 Hop Limit의 값이 '1'이면 해당 Packet을 전달하지 않고 버리게 됩니다. -
Source/Destination Address (128 bits)
IPv6 Header의 가장 큰 특징은 주소 공간이 IPv4 Header에 비해 엄청나게 넓어졌다는 것
TCP

TCP는 여러 개의 필드로 나누어진 20 bytes, 즉 160 bits의 헤더를 사용하며, 각 필드의 비트를 0 또는 1로 변경하여 전송하고자 하는 세그먼트의 정보를 나타낸다.
하지만 이 20 bytes라는 것은 아무 옵션도 없는 기본적인 헤더일 때의 용량이고, TCP의 여러가지 옵션들을 사용하면 헤더 맨 뒤에 옵션 필드들이 추가로 붙기 때문에 최대 40 bytes가 더해진 60 bytes까지도 사용할 수도 있다.
-
Source port, Destination port(16 bits)
이 필드들은 세그먼트의 출발지와 목적지를 나타내는 필드
출발지와 목적지의 주소를 판별하기 위해서는 IP 주소와 포트 번호가 필요IP 주소는 당연히 한 계층 밑인 네트워크 계층에 있는 IP의 헤더에 담기기 때문에, TCP 헤더에는 IP 주소를 나타내는 필드가 없고 포트를 나타내는 필드만 존재
-
Sequence Number(32 bits)
시퀀스 번호는 전송하는 데이터의 순서
최대 4,294,967,296 까지의 수를 담을 수 있기 때문에 시퀀스 번호가 그리 쉽게 중복되지는 않는다.
수신자는 쪼개진 세그먼트의 순서를 파악하여 올바른 순서로 데이터를 재조립
송신자가 최초로 데이터를 전송할 때는 이 번호를 랜덤한 수로 초기화 하며, 이후 자신이 보낼 데이터의 1 bytes당 시퀀스 번호를 1씩 증가시키며 데이터의 순서를 표현하다 4,294,967,296를 넘어갈 경우 다시 0부터 시작 -
Acknowledgment Number(32 bits)
승인 번호는 데이터를 받은 수신자가 예상하는 다음 시퀀스 번호를 의미
연결 설정과 연결 해제 때 발생하는 핸드쉐이크 과정에서는 상대방이 보낸 시퀀스 번호 + 1로 자신의 승인 번호를 만들어내지만, 실제로 데이터를 주고 받을 때는 상대방이 보낸 시퀀스 번호 + 자신이 받은 데이터의 bytes로 승인 번호를 만들어낸다.
예를 들어 1MB짜리 데이터를 전송한다고 생각해보자. 이렇게 큰 데이터를 한번에 전송할 수는 없으므로, 송신자는 이 데이터를 여러 개의 세그먼트로 쪼개서 조금씩 전송해야한다. 이때 송신자가 한번에 전송할 수 있는 데이터 양은 네트워크나 수신자의 상태에 따라 가변적이긴 하지만, 그냥 100 bytes라고 가정해보자.
송신자는 첫 전송으로 100bytes 만큼만 데이터를 전송하며 시퀀스 번호를 0으로 초기화한다. 시퀀스 번호는 1bytes당 1씩 증가하기 때문에 첫 번째 바이트 뭉치는 0, 두 번째 바이트 뭉치는 1, 세 번째 바이트 뭉치는 2와 같은 순서로 매겨질 것이다.
즉, 이번 전송을 통해 수신자는 0~99까지 총 100개의 바이트 뭉치를 받았고, 그 다음 전송 때 받아야할 시퀀스 번호는 2가 아닌 100이 되는 것이다.
tcpdump를 사용하여 패킷을 캡쳐해보면 실제로 송신 측이 보낸 데이터의 길이만큼 수신 측의 승인 번호가 증가하는 모습을 확인해 볼 수 있다.
localhost.http-alt > localhost.49680: Flags [P.], seq 160:240, ack 161, win 6374, length 80
localhost.49680 > localhost.http-alt: Flags [.], ack 240, win 6374송신 측이 보낸 세그먼트를 보면 시퀀스 번호가 seq 160:240로 찍혀있고, 수신 측은 자신의 승인 번호로 콜론 뒤 쪽의 값을 사용하고 있다.
이때 시퀀스 번호의 형식은 n 이상:m 미만의 범위를 나타낸다. 콜론 뒤쪽의 번호는 송신 측의 시퀀스 범위에 포함되지 않으므로 수신 측이 저 번호를 그대로 가져다 쓰는 것이다.
즉, 승인 번호는 다음에 보내줘야하는 데이터의 시작점을 의미한다는 것을 알 수 있다.
-
Data Offset
전체 세그먼트 중에서 헤더가 아닌 데이터가 시작되는 위치가 어디부터인지를 표시
이 오프셋을 표기할 때는 32비트 워드 단위를 사용하며, 32 비트 체계에서의 1 Word = 4 bytes를 의미한다. 즉, 이 필드의 값에 4를 곱하면 세그먼트에서 헤더를 제외한 실제 데이터의 시작 위치를 알 수 있는 것이다.
이 필드에 할당된 4 bits로 표현할 수 있는 값의 범위는 0000 ~ 1111, 즉 0 ~ 15 Word이므로 기본적으로 0 ~ 60 bytes의 오프셋까지 표현할 수 있다.
하지만 옵션 필드를 제외한 나머지 필드는 필수로 존재해야 하기 때문에 최소 값은 20 bytes, 즉 5 Word로 고정되어 있다. -
Reserved (3 bits)
미래를 위해 예약된 필드로, 모두 0으로 채워져야 한다. 상단의 헤더 그림에도 그냥 0 0 0으로 찍혀있는 것을 확인해볼 수 있다. -
Flags (NS ~ FIN)

9개의 비트 플래그, 현재 세그먼트의 속성을 나타낸다.
기존에는 6개의 플래그만을 사용했지만, 혼잡 제어 기능의 향상을 위해 Reserved 필드를 사용하여 NS, CWR, ECE 플래그가 추가되었다.ECN을 사용하지 않던 기존의 네트워크 혼잡 상황 인지 방법은 타임아웃을 이용한 방법이었다. 그러나 처리 속도에 민감한 어플리케이션에서는 이런 대기 시간 조차 아깝기 때문에, 송신자와 수신자에게 네트워크의 혼잡 상황을 명시적으로 알리기 위한 특별한 매커니즘이 필요하게 되었는데, 이것이 바로 ECN이다.
이때 CWR, ECE, ECT, CE 플래그를 사용하여 상대방에게 혼잡 상태를 알려줄 수 있는데, 이 중 CWR, ECE는 TCP 헤더에 존재하고 ECT, CE는 IP 헤더에 존재한다.
| 필드 | 의미 |
|---|---|
| URG | Urgent Pointer(긴급 포인터) 필드에 값이 채워져있음을 알리는 플래그. 이 포인터가 가리키는 긴급한 데이터는 높게 처리되어 먼저 처리된다.요즘에는 많이 사용되지 않는다. |
| ACK | Acknowledgment(승인 번호) 필드에 값이 채워져있음을 알리는 플래그. 이 플래그가 0이라면 승인 번호 필드 자체가 무시된다. |
| PSH | Push 플래그. 수신 측에게 이 데이터를 최대한 빠르게 응용프로그램에게 전달해달라는 플래그이다. 이 플래그가 0이라면 수신 측은 자신의 버퍼가 다 채워질 때까지 기다린다. 즉, 이 플래그가 1이라면 이 세그먼트 이후에 더 이상 연결된 세그먼트가 없음을 의미하기도 한다. |
| RST | Reset 플래그. 이미 연결이 확립되어 ESTABLISHED 상태인 상대방에게 연결을 강제로 리셋해달라는 요청의 의미이다. |
| SYN | Synchronize 플래그. 상대방과 연결을 생성할 때, 시퀀스 번호의 동기화를 맞추기 위한 세그먼트임을 의미한다. |
| FIN | Finish 플래그. 상대방과 연결을 종료하고 싶다는 요청인 세그먼트임을 의미한다. |
| NS | ECN에서 사용하는 CWR, ECE 필드가 실수나 악의적으로 은폐되는 경우를 방어하기 위해 RFC 3540에서 추가된 필드 |
| ECE | ECN Echo 플래그. 해당 필드가 1이면서, SYN 플래그가 1일 때는 ECN을 사용한다고 상대방에게 알리는 의미. SYN 플래그가 0이라면 네트워크가 혼잡하니 세그먼트 윈도우의 크기를 줄여달라는 요청의 의미이다. |
| CWR | 이미 ECE 플래그를 받아서, 전송하는 세그먼트 윈도우의 크기를 줄였다는 의미이다. |
-
Window Size
윈도우 사이즈 필드에는 한번에 전송할 수 있는 데이터의 양을 의미하는 값을 담는다. 2^{16} = 655352^16 = 65535 만큼의 값을 표현할 수 있고 단위는 바이트이므로, 윈도우의 최대 크기는 64KB라는 말이 된다.
하지만 이 최대 크기는 옛날 옛적에 생긴 기준이라 요즘같이 대용량 고속 통신 환경에는 맞지 않는 경우도 있다. 그래서 비트를 왼쪽으로 시프트하는 방식으로 윈도우 사이즈의 최대 크기를 키울 수 있는 방식도 사용하고 있으며, 몇 번 시프트할 지는 옵션 필드의 WSCALE 필드를 사용하여 표기한다. -
Checksum
체크섬은 데이터를 송신하는 중에 발생할 수 있는 오류를 검출하기 위한 값
TCP의 체크섬은 전송할 데이터를 16 Bits씩 나눠서 차례대로 더해가는 방법으로 생성
만약 이 값에 0이 하나라도 있으면 송신 측이 보낸 데이터에 뭔가 변조가 있었음을 알 수 있다. -
Urgent Pointer
말 그대로 긴급 포인터
URG 플래그가 1이라면 수신 측은 이 포인터가 가르키고 있는 데이터를 우선 처리 -
Options
옵션 필드는 TCP의 기능을 확장할 때 사용하는 필드
이 필드는 크기가 고정된 것이 아니라 가변적
그래서 수신 측이 어디까지가 헤더고 어디서부터 데이터인지 알기 위해 위에서 설명한 데이터 오프셋 필드를 사용하는 것이다.
데이터 오프셋 필드는 20 ~ 60 bytes의 값을 표현할 수 있다고 했는데, 아무런 옵션도 사용하지 않은 헤더의 길이, 즉 Source Port 필드부터 Urgent Pointer 필드까지의 길이가 20 bytes이고, 옵션을 모두 사용했을 때 옵션 필드의 최대 길이가 40 bytes이기 때문이다.
만약 데이터 오프셋 필드의 값이 5, 즉 20 bytes보다 크지만 TCP의 옵션을 하나도 사용하고 있지 않다면, 초과한 bytes 만큼 이 필드를 0으로 채워줘야 수신 측이 헤더의 크기를 올바르게 측정할 수 있다.
대표적인 옵션으로는 윈도우 사이즈의 최대 값 표현을 확장할 수 있는 WSCALE, Selective Repeat 방식을 사용하기 위한 SACK 등이 있으며, 이외에도 거의 30개 정도의 옵션을 사용할 수 있다.
