
이번 포스팅은 학기 중 진행했던 텍스트 마이닝 프로젝트의 일부를 담고 있습니다.
개요
대학을 이제 막 졸업한, 혹은 졸업을 앞둔 청년들에게 다가오는 첫 번째 시련은 아무래도 취업일 것입니다. 원하는 직장, 직업을 가지는 것은 누구나 꿈꾸는 일이지만, 그 꿈을 이루기엔 요즘 현실이 너무나도 어려운 것 같습니다. 계속해서 들려오는 실업률, 청년 실업 등 관련된 소식이 이를 뒷받침합니다.
또한, 어렵게 들어간 회사가 막상 맞지 않는 경우가 있을 수도 있습니다. 보수적인 사내 문화, 너무 많은 야근, 적은 연봉, 흔히 말하는 꼰대 같은 상사 등.. 많은 부분이 사회 초년생들을 힘들게 할 수 있습니다.
취업을 준비하는 구직자분들은 취업과 관련된 정보를 얻기가 참 어렵다고 합니다. 합격에 필요한 스펙, 활동, 자격 조건과 같은 정보도 중요하지만, 기업에 대한 정보 또한 중요합니다. 기업 내의 분위기는 어떠한지, 일의 강도는 어떠한지, 워라벨은 어떠한지를 미리 알아야 어렵게 들어간 회사에 실망하지 않을 것입니다.
이번 프로젝트는 이러한 문제에 조금이나마 도움이 될 수 있도록, 기업 내 현직자분들의 기업 리뷰를 요약하여 제공하고자 합니다. 또한, 취업 준비에 도움이 될 수 있도록 최종 합격자분들의 취업 팁 및 취업에 도움이 되었던 활동을 요약하여 제공합니다.
데이터 수집
취업 컨텐츠 플랫폼, 캐치

취업 컨텐츠 플랫폼 "캐치(CATCH)"에서는 취업과 관련된 많은 정보를 얻을 수 있습니다. 이번 프로젝트에서는 많은 정보 중 기업 현직자분들이 작성한 기업 리뷰 정보와 최종 합격자분들의 합격 후기 정보를 사용하였습니다.
사이트 내 정보는 다음과 같습니다. 우선 기업 리뷰입니다.

각 기업의 전반적인 리뷰 점수를 확인할 수 있습니다. 또한, 현직자분의 각 기업에 대한 좋은 점 리뷰와 나쁜 점 리뷰, 별점과 기업에 대한 추천 여부를 확인할 수 있습니다.
다음으로 최종 합격 후기입니다.
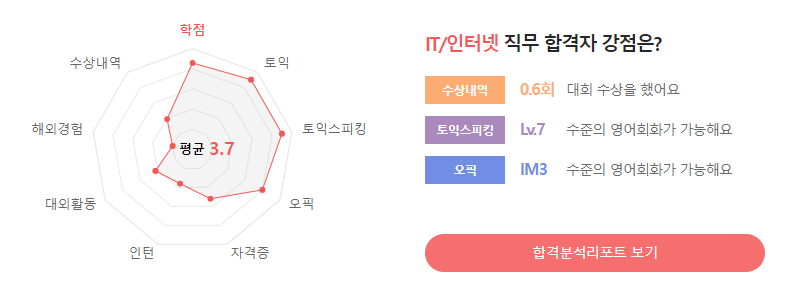
각 직무별 평균적인 합격 스펙을 확인할 수 있습니다. 총 12개의 직무가 존재합니다.
또한, 공통된 4가지의 질문/답변과 함께 해당 합격자분의 합격 스펙을 확인할 수 있습니다. 4가지의 질문은 다음과 같습니다.
1) 서류, 면접 등 각 단계별 준비&응시 후기를 상세하게 작성해주세요.
2) 본인이 생각하는 최종합격의 이융하 합격Tip을 알려주세요.
3) 취업준비 기간과 기업/직무 선택의 과정은 어땠나요?
4) 취업준비에 가장 도움이 되었던 활동이 있다면?
실제 기업 리뷰 내용이나 합격 후기를 확인하시려면 캐치 사이트를 참고해 주세요.
데이터 크롤링

이번 프로젝트에서는 셀레니움을 사용하여 캐치 사이트의 데이터를 크롤링하였습니다. 기업 리뷰의 경우, (기업 이름, 좋은 점 리뷰, 나쁜 점 리뷰, 기업 추천 여부)를 크롤링하였으며, 합격 후기의 경우 (기업 이름, 직무, 본인이 생각한 합격 이유와 취업 팁, 취업 중 도움이 된 활동)을 크롤링하였습니다. 기업 리뷰의 경우 대기업/중견기업 중 170여개의 기업 리뷰를 수집하였으며, 최종 합격 후기의 경우 존재하는 모든 후기를 수집하였습니다.
추가로, 각 기업에 대한 전반적인 리뷰 점수와 직무별 평균 합격 스펙 또한 수집하였습니다.
수집된 데이터의 형태는 다음과 같습니다.
1. 기업 리뷰

기업 이름은 블라인드 처리하였습니다.
2. 최종 합격 후기

마찬가지로 기업 이름은 블라인드 처리하였습니다.
3. 기업의 전반적인 리뷰 점수
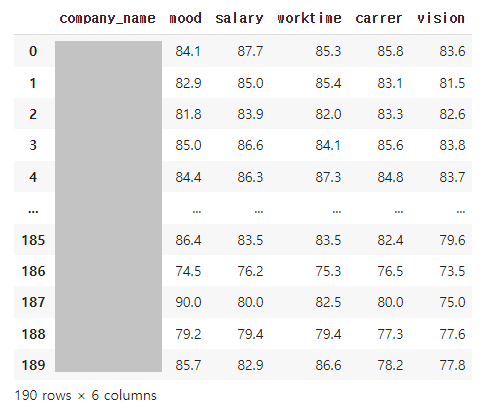
각 컬럼의 뜻은 다음과 같습니다.
- mood: 조직문화/분위기
- salary: 연봉/복지
- worktime: 근무시간/휴가
- carrer: 커리어/성장 (career 스펠링이 틀렸지만, 나중에 발견한 것이라 수정하지 않았습니다..ㅎㅎ)
- vision: 경영진/비전
4. 직무별 평균 합격 스펙
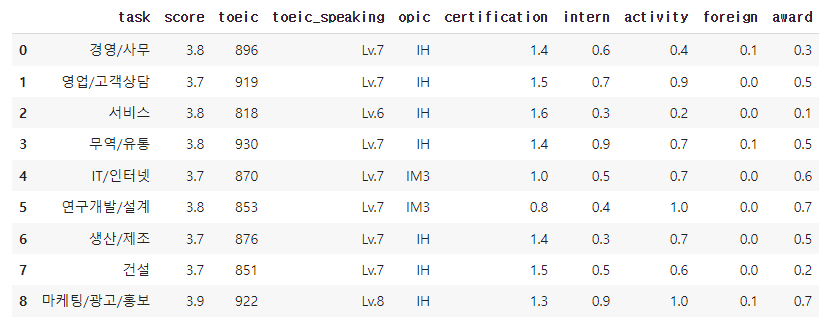
총 12개의 직무가 존재하지만, 직무별 평균 합격 스펙이 존재하지 않는 직무가 존재합니다. 수집된 데이터에 결측치는 존재하지 않았으므로, 전처리 과정으로 넘어갑니다.
전처리
텍스트에 적용한 전처리 과정은 다음과 같습니다. 우선, 전체 문장을 개행 문자나 온점으로 분리합니다. 이후, pandas의 explode 메서드를 사용하여 하나의 row 당 하나의 문장이 위치하도록 합니다. 이후 SentenceBERT를 사용하여 각 문장을 벡터로 임베딩 합니다.
문장을 입력하여 임베딩하므로, 문장의 형태를 최대한 보존하기 위하여 불용어 제거 및 표제어 추출 등을 진행하지 않았습니다.
다음은 전처리 코드입니다.
split, explode
# 리뷰 예시
review['good_review'][4]출력
'Good\n눈치 없이 퇴근이 가능하나\n부서바이부서가 심하다. 월급 만족'
def split_text(text):
words = re.split(r'[.\n]', text)[1:]
words = [word.strip() for word in words if word.strip()]
words = [word for word in words if len(word) >= 2]
return words
review['good_review'] = review['good_review'].apply(split_text)
review['bad_review'] = review['bad_review'].apply(split_text)
review.good_review[4]출력
['눈치 없이 퇴근이 가능하나', '부서바이부서가 심하다', '월급 만족']
# explode 메서드를 통해 리스트 내 한 문장을 하나의 row로 표현
good_review = review[['company_name', 'good_review']]
good_review = good_review.explode('good_review')
good_review.reset_index(inplace=True, drop=True)
good_review출력

위와 같은 방법으로, 나쁜 점 리뷰에 대해서도 동일하게 진행합니다.
bad_review = review[['company_name', 'bad_review']]
bad_review = bad_review.explode('bad_review')
bad_review.reset_index(inplace=True, drop=True)기업 리뷰 데이터의 경우, good_review 또는 bad_review의 row 개수가 5개 미만인 기업은 모두 제거합니다. 이는 이후 문장 요약을 진행하기 전, 각 기업에 대한 좋은/나쁜 리뷰를 5개의 클러스터로 군집화할 것이기 때문입니다. 군집 개수보다 적은 리뷰를 가진 기업은 데이터에서 제거합니다.
# 이후 클러스터링을 위해, good_review, bad_review의 row 개수가 5개 미만인 기업은 제거
for c in review.company_name.unique():
if good_review[good_review.company_name==c].shape[0] < 5 or bad_review[bad_review.company_name==c].shape[0] < 5:
good_review = good_review[good_review.company_name!=c]
bad_review = bad_review[bad_review.company_name!=c]
good_review.shape, bad_review.shape출력
((4190, 2), (4185, 2))
본인이 생각한 합격 이유와 취업 팁(이하 취업 팁)과 도움이 된 활동의 경우도 기업 리뷰의 경우와 비슷하게 전처리를 진행합니다. 문장을 구분하는 함수만 조금 달라집니다.
def split_text(text):
words = re.split(r'[.\n]', text)
words = [word.strip() for word in words if word.strip()]
words = [word for word in words if len(word) >= 2]
return words
success['tip'] = success['tip'].apply(split_text)
success['activity'] = success['activity'].apply(split_text)
# 같은 방법으로 explode
tip = success[['tasks', 'tip']]
activity = success[['tasks', 'activity']]
tip = tip.explode('tip')
tip.reset_index(inplace=True, drop=True)
activity = activity.explode('activity')
activity.reset_index(inplace=True, drop=True)SenteceBERT
SBERT를 사용하여 각 문장을 임베딩합니다. 서울대학교의 KR-SBERT 모델을 사용하였습니다. 각 문장은 768차원의 벡터로 임베딩됩니다.
# 서울대학교의 KR-SBERT 모델 사용
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
# SBERT를 활용한 문장 임베딩
good_review['embedding'] = good_review.apply(lambda x: model.encode(x.good_review), axis = 1)
# 하나의 문장이 768 차원의 벡터로 임베딩
len(good_review.embedding[0])출력
768
# 나머지 텍스트도 임베딩 진행
bad_review['embedding'] = bad_review.apply(lambda x: model.encode(x.bad_review), axis = 1)
tip['embedding'] = tip.apply(lambda x: model.encode(x.tip), axis = 1)
activity['embedding'] = activity.apply(lambda x: model.encode(x.activity), axis = 1)문장 요약
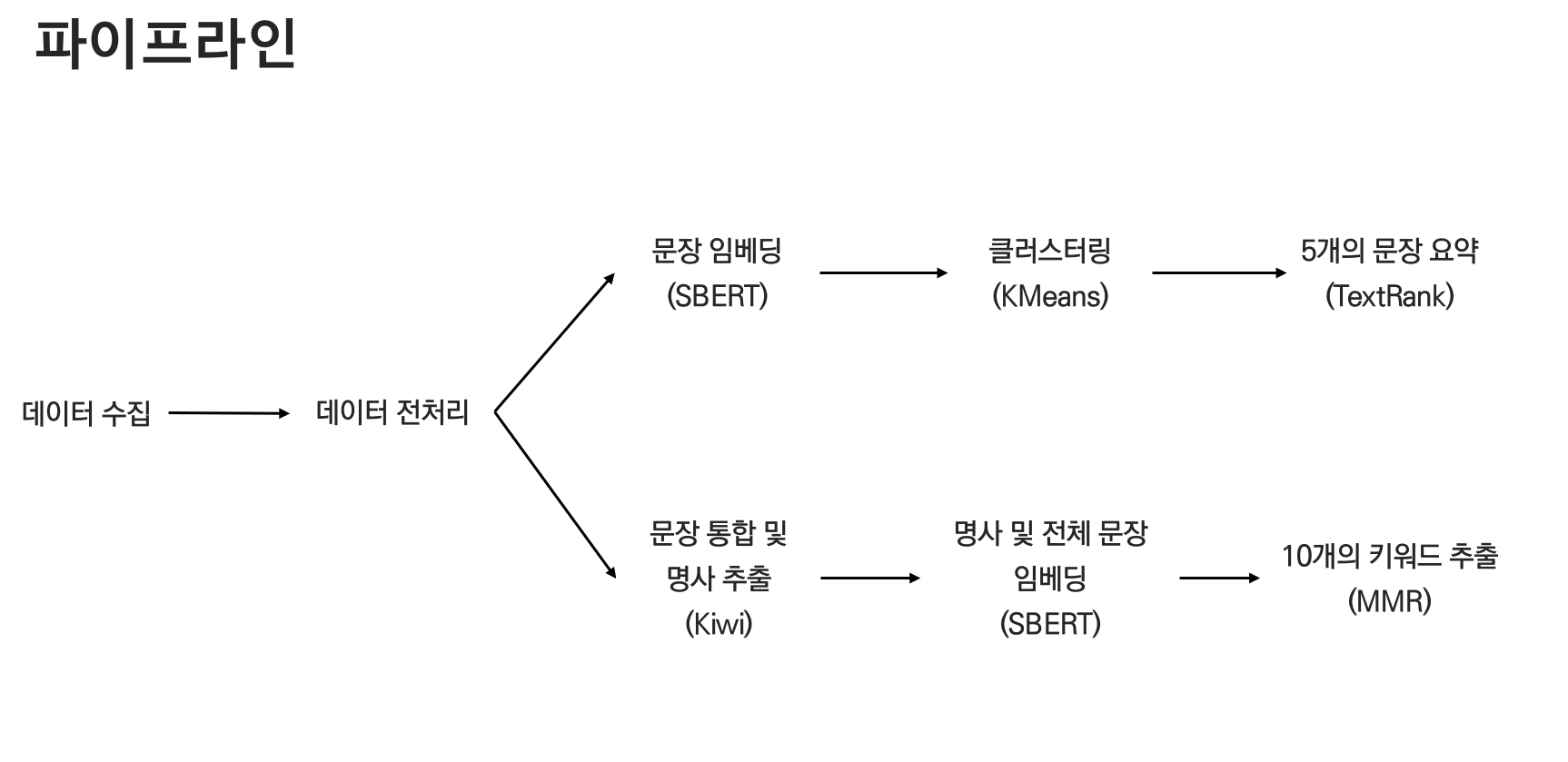
문장 요약을 위해서 크게 2가지의 알고리즘을 사용합니다. 우선, 전체 텍스트를 5개의 클러스터로 분류합니다. 기업 리뷰를 예로 들면, 각 클러스터에는 해당 기업에 대한 리뷰 중 유사한 리뷰들이 모여 있을 것입니다.
이후 각 클러스터에 TextRank 알고리즘을 적용하여 각 클러스터를 대표하는 하나의 문장을 선택합니다. 전체 클러스터의 개수가 5개이므로, 총 5개의 대표 문장을 얻을 수 있습니다.
TextRank 및 텍스트 요약에 대한 더 많은 정보는 딥러닝을 이용한 자연어 처리 입문을 참고하시기 바랍니다.
embedding_dim = 768
# 문장간 유사도 행렬 계산
def similarity_matrix(sentence_embedding):
sim_mat = np.zeros([len(sentence_embedding), len(sentence_embedding)])
for i in range(len(sentence_embedding)):
for j in range(len(sentence_embedding)):
sim_mat[i][j] = cosine_similarity(sentence_embedding[i].reshape(1, embedding_dim),
sentence_embedding[j].reshape(1, embedding_dim))[0,0]
return sim_mat
# 유사도 행렬 기반 문장 별 점수 계산
def calculate_score(sim_matrix):
nx_graph = nx.from_numpy_array(sim_matrix)
scores = nx.pagerank(nx_graph)
return scores
# 점수가 가장 높은 문장 1개의 인덱스 계산
# 해당하는 인덱스는 전체 텍스트를 요약하는 문장의 인덱스
def calc_top_index(score):
top_index = []
temp_score = sorted(score.items(), key=lambda x: x[1], reverse=True)[:]
top_index.append(temp_score[0][0])
return top_index
# 전체 텍스트를 5개의 클러스터로 분할
# 이후 calc_top_index로 각 클러스터 당 대표하는 1개 인덱스 계산
def text_clustering(data):
vector_data = data['embedding'].tolist()
X = [x for x in vector_data]
X = np.array(X)
kmeans = KMeans(n_clusters=5, random_state=21)
kmeans.fit(X)
labels = kmeans.labels_
data['cluster'] = labels
return data다음은 기업 리뷰와 합격 후기 텍스트를 요약하는 함수입니다.
def review_summarization(data, review_type):
company_review = pd.DataFrame(columns=['company_name', 'embeddings'])
embedding_list = []
temp_review = data
for embedding in temp_review['embedding']:
embedding_list.append(embedding)
company_review['company_name'] = [temp_review.company_name]
company_review['embeddings'] = [embedding_list]
company_review.reset_index(inplace=True, drop=True)
company_review['SimMatrix']= company_review['embeddings'].apply(similarity_matrix)
company_review['score'] = company_review['SimMatrix'].apply(calculate_score)
company_review['top_index'] = company_review['score'].apply(calc_top_index)
temp_review = data.reset_index(drop=True)
index = company_review['top_index']
review_list = []
if review_type.lower() == 'good':
for i in index[0]:
review_list.append(temp_review.loc[i, 'good_review'])
elif review_type.lower() == 'bad':
for i in index[0]:
review_list.append(temp_review.loc[i, 'bad_review'])
return review_listdef success_summarization(tip, activity, task_name):
task_tip = pd.DataFrame(columns=['task', 'embeddings'])
task_activity = pd.DataFrame(columns=['task', 'embeddings'])
tip_embedding_list = []
act_embedding_list = []
temp_tip, temp_act = tip, activity
for embedding in temp_tip['embedding']:
tip_embedding_list.append(embedding)
for embedding in temp_act['embedding']:
act_embedding_list.append(embedding)
temp_tip = pd.DataFrame(columns=['task', 'embeddings'])
temp_tip['task'] = [task_name]
temp_tip['embeddings'] = [tip_embedding_list]
task_tip = pd.concat([task_tip, temp_tip])
temp_activity = pd.DataFrame(columns=['task', 'embeddings'])
temp_activity['task'] = [task_name]
temp_activity['embeddings'] = [act_embedding_list]
task_activity = pd.concat([task_activity, temp_activity])
task_tip.reset_index(inplace=True, drop=True)
task_activity.reset_index(inplace=True, drop=True)
task_tip['SimMatrix']= task_tip['embeddings'].apply(similarity_matrix)
task_tip['score'] = task_tip['SimMatrix'].apply(calculate_score)
task_tip['top_index'] = task_tip['score'].apply(calc_top_index)
task_activity['SimMatrix']= task_activity['embeddings'].apply(similarity_matrix)
task_activity['score'] = task_activity['SimMatrix'].apply(calculate_score)
task_activity['top_index'] = task_activity['score'].apply(calc_top_index)
temp_tip, temp_act = tip[tip.tasks==task_name].reset_index(drop=True), activity[activity.tasks==task_name].reset_index(drop=True)
tip_index, act_index = task_tip[task_tip.task==task_name]['top_index'], task_activity[task_activity.task==task_name]['top_index']
tip_list = []
act_list = []
for i in tip_index[0]:
tip_list.append(temp_tip.loc[i, 'tip'])
for i in act_index[0]:
act_list.append(temp_act.loc[i, 'activity'])
return tip_list, act_list키워드 추출
전체 텍스트의 키워드를 추출하는 과정은 다음과 같습니다.
- 분리된 텍스트를 하나의 텍스트로 통합한다.
- 전체 텍스트에서 명사를 추출한다.
- 추출된 명사와 전체 텍스트 사이의 유사도가 높다면 그 명사를 키워드로 결정한다.
추출된 명사와 전체 텍스트 사이의 유사도를 계산할 수 있도록, 각 명사와 전체 텍스트를 SBERT를 사용하여 임베딩합니다.
또한, 위의 3가지의 과정만을 사용하여 키워드를 추출할 경우 추출된 키워드가 모두 비슷할 수 있습니다. 이를 방지하고 다양한 의미의 키워드를 도출할 수 있도록, 다음의 MMR 알고리즘을 사용합니다.
는 전체 텍스트, 는 각 토큰(명사)를 의미하며, 는 0에서 1사이 값을 가집니다.
오른쪽 식 을 통해, 추출되는 키워드 간 유사도가 낮아지게 함으로 다양한 의미의 키워드를 도출합니다.
다음은 코드 부분입니다. SBERT의 경우 위와 같이 KR-SBERT 모델을 사용하였으며, 명사 추출을 위해 Kiwi 형태소 분석기를 사용하였습니다.
# Kiwi 형태소 분석기를 사용한 품사 태깅
# 명사만 추출
def noun_extractor(text):
kiwi = Kiwi()
results = []
result = kiwi.analyze(text)
for token, pos, _, _ in result[0][0]:
# 명사 또는 외국어(SL) 관련 토큰만 추출
if len(token) != 1 and pos.startswith('N') or pos.startswith('SL'):
results.append(token)
return results
# 키워드의 다양성을 위한 mmr 알고리즘
# diversity = 1 - lambda로 생각할 수 있음
def mmr(doc_embedding, candidate_embeddings, words, top_n, diversity):
# 문서와 각 키워드들 간의 유사도가 적혀있는 리스트
word_doc_similarity = cosine_similarity(candidate_embeddings, doc_embedding)
# 각 키워드들 간의 유사도
word_similarity = cosine_similarity(candidate_embeddings)
# 문서와 가장 높은 유사도를 가진 키워드의 인덱스를 추출.
# 만약, 2번 문서가 가장 유사도가 높았다면
# keywords_idx = [2]
keywords_idx = [np.argmax(word_doc_similarity)]
# 가장 높은 유사도를 가진 키워드의 인덱스를 제외한 문서의 인덱스들
# 만약, 2번 문서가 가장 유사도가 높았다면
# ==> candidates_idx = [0, 1, 3, 4, 5, 6, 7, 8, 9, 10 ... 중략 ...]
candidates_idx = [i for i in range(len(words)) if i != keywords_idx[0]]
# 최고의 키워드는 이미 추출했으므로 top_n-1번만큼 아래를 반복.
# ex) top_n = 5라면, 아래의 loop는 4번 반복됨.
for _ in range(top_n - 1):
try:
candidate_similarities = word_doc_similarity[candidates_idx, :]
target_similarities = np.max(word_similarity[candidates_idx][:, keywords_idx], axis=1)
# MMR을 계산
mmr = (1-diversity) * candidate_similarities - diversity * target_similarities.reshape(-1, 1)
mmr_idx = candidates_idx[np.argmax(mmr)]
# keywords & candidates를 업데이트
keywords_idx.append(mmr_idx)
candidates_idx.remove(mmr_idx)
except:
break
return [words[idx] for idx in keywords_idx]
# 입력된 텍스트에 대해 10개의 키워드를 출력하는 함수
def extract_keywords(text):
# 명사 추출 후 명사 토큰만 사용
n_gram_range = (1, 1)
nouns = noun_extractor(text)
text = ' '.join(nouns)
# n-gram을 고려한 CountVectorizer
count = CountVectorizer(ngram_range=n_gram_range).fit([text])
candidates = count.get_feature_names_out()
# SentenceBERT를 사용한 인코딩
doc_embedding = model.encode([text])
candidate_embeddings = model.encode(candidates)
# mmr 알고리즘을 적용하여 다양성을 가진 10개의 키워드 추출
return mmr(doc_embedding, candidate_embeddings, candidates, top_n=10, diversity=0.4)def extract_keywords_from_review(data, review_type):
if review_type == 'good':
review_text = '. '.join(data.good_review)
return extract_keywords(review_text)
elif review_type == 'bad':
review_text = '. '.join(data.bad_review)
return extract_keywords(review_text)
def extract_keywords_from_success(data, success_type):
if success_type == 'tip':
success_text = '. '.join(data.tip)
return extract_keywords(success_text)
elif success_type == 'activity':
success_text = '. '.join(data.activity)
return extract_keywords(success_text)키워드 추출을 구현할 때는 이곳의 코드를 많이 참고하였습니다. 더 자세한 내용을 알고 싶으시다면 참고하시길 바랍니다.
프로젝트 결과
이제 실제 데이터를 요약한 결과를 확인합니다.
요약 결과 확인
다음의 함수를 통해, 검색 가능한 기업 종류 또는 직무 종류를 확인할 수 있습니다. 취업 팁과 도움이 된 활동은 직무별로 검색이 가능하도록 구현하였습니다.
def print_company_list():
print('검색 가능한 기업 종류는 다음과 같습니다', end='\n\n')
n_iter = len(good_review.company_name.unique()) // 7 + 1
for i in range(n_iter):
if i != n_iter:
print(good_review.company_name.unique()[7*i:7*(i+1)])
elif i == n_iter:
print(good_review.company_name.unique()[7*i:])
def print_task_list():
print('검색 가능한 직무 종류는 다음과 같습니다', end='\n\n')
print(success.tasks.unique()[:6])
print(success.tasks.unique()[6:])print_company_review, print_task_review 함수를 통해 원하는 기업의 리뷰 정보 또는 원하는 직무의 취업 후기 정보를 확인할 수 있습니다.
def print_company_review(company_name):
'''
Parameter
------------
company_name: str, 회사 이름
Output
------------
company information: 회사의 종합적 리뷰 및 good 리뷰, bad 리뷰에 대한 요약 제시
'''
print('-'*200, end='\n\n')
print(company_name, end='\n\n')
company_overall_review = overall_review[overall_review.company_name==company_name]
company_review = review[review.company_name==company_name]
company_good_review = good_review[good_review.company_name==company_name]
company_bad_review = bad_review[bad_review.company_name==company_name]
company_success = success[success.company_name==company_name]
# 회사의 종합적 리뷰 출력
# shape[0]이 0이라면 해당 기업에 대한 종합 리뷰가 존재하지 않음
if company_overall_review.shape[0] != 0:
print('해당 기업의 종합적인 리뷰 점수는 다음과 같습니다.')
print(' 1) 조직문화/분위기: %.1f' %company_overall_review.mood.iloc[0])
print(' 2) 연봉/복지: %.1f' %company_overall_review.salary.iloc[0])
print(' 3) 근무시간/휴가: %.1f' %company_overall_review.worktime.iloc[0])
print(' 4) 커리어/성장: %.1f' %company_overall_review.carrer.iloc[0])
print(' 5) 경영진/비전: %.1f' %company_overall_review.vision.iloc[0])
print(end='\n\n')
# 회사의 리뷰 중 추천 비율 출력
total_review_cnts = company_review.shape[0]
recommend_cnts = company_review.recommend.str.contains('추천').sum()
print('전체 리뷰 %d개의 리뷰 중 %d개의 추천 리뷰가, %d개의 비추천 리뷰가 존재합니다.' %(total_review_cnts, recommend_cnts, total_review_cnts - recommend_cnts), end='\n')
print('전체 리뷰 중 추천 리뷰의 비율은 %.2f%%입니다.' %(recommend_cnts/total_review_cnts*100), end='\n\n\n')
# 클러스터링
company_good_review = text_clustering(company_good_review)
company_bad_review = text_clustering(company_bad_review)
# Good 리뷰 요약
print('해당 기업의 Good review 요약')
for c in range(5):
good_review_list = review_summarization(company_good_review[company_good_review.cluster==c], 'good')
for i in range(1):
try:
print('- ', good_review_list[i])
except:
break
print()
print('해당 기업의 Good review에 대한 키워드')
good_keyword_list = extract_keywords_from_review(company_good_review, 'good')
for w in good_keyword_list:
print(w, end=' ')
print(end='\n\n')
# Bad 리뷰 요약
print('해당 기업의 Bad review 요약')
for c in range(5):
bad_review_list = review_summarization(company_bad_review[company_bad_review.cluster==c], 'bad')
for i in range(1):
try:
print('- ', bad_review_list[i])
except:
break
print()
print('해당 기업의 Bad review에 대한 키워드')
bad_keyword_list = extract_keywords_from_review(company_bad_review, 'bad')
for w in bad_keyword_list:
print(w, end=' ')
print(end='\n\n\n')
n_company_success = len(company_success)
print('해당 기업의 최종합격 후기가 %d개 존재합니다.' %(len(company_success)))
if (n_company_success > 0):
print('다음은 해당 기업의 최종합격 후기 예시입니다.', end='\n\n')
print('직무: %s' %(company_success.tasks.iloc[0]), end='\n\n')
print('1. 본인이 생각한 합격 이유와 합격 Tip')
for i in range(len(company_success.tip.iloc[0])):
print(company_success.tip.iloc[0][i], end='\n')
print()
print('2.취업준비에 가장 도움이 되었던 활동')
for i in range(len(company_success.activity.iloc[0])):
print(company_success.activity.iloc[0][i], end='\n')
# End
print()
print('-'*200)def print_task_review(task_name):
'''
Parameter
------------
task_name: str, 직무 이름
Output
------------
task information: 해당 직무에 대한 정보, 합격자들의 스펙 및 합격 Tip과 도움이 되었던 활동 요약 제시
'''
print('-'*200, end='\n\n')
print('직무: ', task_name, end='\n\n')
task_success = success[success.tasks==task_name]
task_tip = tip[tip.tasks==task_name]
task_activity = activity[activity.tasks==task_name]
task_success_spec = success_spec[success_spec.task==task_name]
spec_list = ['경영/사무', '영업/고객상담', '서비스', '무역/유통', 'IT/인터넷', '연구개발/설계', '생산/제조', '건설', '마케팅/광고/홍보']
print('해당 직무에 대한 합격 후기가 %d개 존재합니다' %(task_success.shape[0]), end='\n\n')
if task_name in spec_list:
print('해당 직무 합격자의 평균 스펙은 다음과 같습니다.')
print(' 1) 평균 학점은 %.1f점 입니다.' %task_success_spec.score.iloc[0])
print(' 2) 평균 토익 점수는 %d점 입니다.' %task_success_spec.toeic.iloc[0])
print(' 3) 평균 토익 스피킹 레벨은 %s 입니다.' %task_success_spec.toeic_speaking.iloc[0])
print(' 4) 평균 오픽 레벨은 %s 입니다.' %task_success_spec.opic.iloc[0])
print(' 5) 평균 자격증 개수는 %.1f개 입니다.' %task_success_spec.certification.iloc[0])
print(' 6) 평균 인턴 경험은 %.1f회 입니다.' %task_success_spec.intern.iloc[0])
print(' 7) 평균 대외 활동 경험은 %.1f회 입니다.' %task_success_spec.activity.iloc[0])
print(' 8) 평균 해외 활동 경험은 %.1f회 입니다.' %task_success_spec.foreign.iloc[0])
print(' 9) 평균 수상 내역은 %.1f회 입니다.' %task_success_spec.award.iloc[0])
else:
print('해당 직무에 대한 합격자 분석이 존재하지 않습니다.')
print(end='\n\n')
# 클러스터링
task_tip = text_clustering(task_tip)
task_activity = text_clustering(task_activity)
tip_list_1, activity_list_1 = success_summarization(task_tip[task_tip.cluster==0], task_activity[task_activity.cluster==0], task_name)
tip_list_2, activity_list_2 = success_summarization(task_tip[task_tip.cluster==1], task_activity[task_activity.cluster==1], task_name)
tip_list_3, activity_list_3 = success_summarization(task_tip[task_tip.cluster==2], task_activity[task_activity.cluster==2], task_name)
tip_list_4, activity_list_4 = success_summarization(task_tip[task_tip.cluster==3], task_activity[task_activity.cluster==3], task_name)
tip_list_5, activity_list_5 = success_summarization(task_tip[task_tip.cluster==4], task_activity[task_activity.cluster==4], task_name)
print('본인이 생각한 최종합격 이유와 합격 Tip 요약')
print('- ', tip_list_1[0])
print('- ', tip_list_2[0])
print('- ', tip_list_3[0])
print('- ', tip_list_4[0])
print('- ', tip_list_5[0])
print()
print('해당 직무의 합격 이유와 합격 Tip에 대한 키워드')
tip_keyword_list = extract_keywords_from_success(task_tip, 'tip')
for w in tip_keyword_list:
print(w, end=' ')
print(end='\n\n')
print('취업 준비시 가장 도움이 된 활동 요약')
print('- ', activity_list_1[0])
print('- ', activity_list_2[0])
print('- ', activity_list_3[0])
print('- ', activity_list_4[0])
print('- ', activity_list_5[0])
print(end='\n\n')
print('해당 직무의 가장 도움이 된 활동에 대한 키워드')
act_keyword_list = extract_keywords_from_success(task_activity, 'activity')
for w in act_keyword_list:
print(w, end=' ')
print()
# End
print()
print('-'*200)기업 리뷰
기업 리뷰 정보를 확인하면 다음과 같습니다.
print_company_list()출력
검색 가능한 기업 종류는 다음과 같습니다
['삼성전자' '현대자동차' 'GS칼텍스' '기아' 'S-OIL' 'SK하이닉스' '삼성생명보험']
['현대모비스' '에이치디현대오일뱅크' '포스코인터내셔널' '삼성디스플레이' 'LG전자' '삼성물산' '쿠팡']
['삼성화재해상보험' 'LG디스플레이' '현대제철' 'LG화학' '한국투자증권' '현대글로비스' '한화생명보험']
['교보생명보험' '현대해상화재보험' 'DB손해보험' 'LG이노텍' 'HMM' 'KT' '농협은행']
['삼성SDI' '미래에셋증권' '롯데케미칼' '이마트' '대한항공' 'LG유플러스' 'SK텔레콤']
['현대건설' '농협경제지주' '엘지에너지솔루션' 'GS리테일' '한화솔루션' '대우건설' '에이치디현대중공업']
['한국GM' '롯데쇼핑' 'GS건설' '포스코홀딩스' '한화손해보험' 'CJ대한통운' '포스코이앤씨']
['고려아연' '키움증권' 'CJ제일제당' '동국제강' '현대트랜시스' '현대엔지니어링' '삼성전기']
['현대위아' '삼성엔지니어링' 'SK네트웍스' 'SK에코플랜트' '롯데건설' '삼성중공업' '팬오션']
['아시아나항공' '호텔롯데' '네이버' '효성TNC' '두산에너빌리티' '삼성SDS' '금호석유화학']
['한화오션' '코리아세븐' '현대삼호중공업' '흥국생명보험' 'LG CNS' 'GS글로벌' '현대캐피탈']
['호텔신라' 'LS전선' 'SK브로드밴드' '한화' '코오롱인더스트리' 'LG생활건강' '현대미포조선']
['KT&G' '삼성카드' '비씨카드' '한국타이어앤테크놀로지' '삼성전자판매' '케이지모빌리티' 'SK C&C']
['롯데하이마트' '롯데글로벌로지스' '미래에셋생명보험' '현대로템' '포스코퓨처엠' 'CJ ENM' '세메스']
['아모레퍼시픽' '코웨이' 'CJ올리브영' '현대카드' '한국항공우주산업' 'KCC' '하']
['에이치엘만도' '롯데칠성음료' '에스씨케이컴퍼니' '효성중공업' 'HD현대건설기계' '롯데렌탈' '카카오']
['롯데웰푸드' '삼성바이오로직스' '에스원' '한진' '태광산업' '삼성웰스토리' 'DB생명보험']
['SK실트론' 'CJ프레시웨이' '대림' '효성화학' 'LS일렉트릭' '현대오토에버' '대한전선']
['현대케피코' '한화시스템' '이마트24' '동원홈푸드' '한화투자증권' '금호건설' '쿠팡풀필먼']
['삼성전자서비스' '삼양사' 'SK이노베이션' '셀트리온' '넥슨코리아' '현대지에프홀딩스' 'KCC건설']
['동원F&B' '신세계' '에이치디현대일렉트릭' '세아제강' '애경케미칼' 'DB하이텍' '현대백화점']
['SSG닷컴']# 기업 이름은 블라인드 처리
print_company_review('$$$$')출력

다음과 같이, 종합적인 리뷰 점수와 추천 리뷰의 비율, 좋은 점 / 나쁜 점 리뷰에 대한 요약과 키워드, 최종합격 후기 개수와 최종합격 후기가 존재한다면 하나의 후기를 예시로 보여주고 있습니다.


다른 기업을 검색했을 때의 결과는 다음과 같습니다.


최종 합격 후기
최종 합격 후기의 경우 직무별로 검색이 가능합니다.
print_task_list()출력
검색 가능한 직무 종류는 다음과 같습니다
['영업/고객상담' '연구개발/설계' '생산/제조' '경영/사무' '전문/특수직' '디자인']
['IT/인터넷' '마케팅/광고/홍보' '무역/유통' '건설' '서비스' '미디어']IT/인터넷 직무의 예시를 보겠습니다.
print_task_review('IT/인터넷')출력

다음과 같이, 해당 직무 합격자들의 평균 스펙, 본인이 생각한 최종합격 이유와 합격 팁/취업 중 도움이 된 활동에 대한 요약과 키워드를 제공합니다.


다른 직무의 경우를 보겠습니다.


마무리
이번 프로젝트를 통해 현직자분들의 기업 리뷰 정보와 취업 최종 합격자분들의 합격 후기 정보를 요약하여 제공할 수 있었습니다. 정보 수집 시간에 부담을 느낄 수 있는 구직자분들에게 작은 도움이 될 수 있기를 바랍니다.
이번 프로젝트의 한계점으로는, 하나의 플랫폼에서만 데이터를 수집하여 데이터의 양이 적다는 것과 요약한 정보를 평가할 수 있는 수단이 없다는 점입니다. 캐치 외에도 잡플래닛과 같은 다른 취업 플랫폼에서 관련 데이터를 수집한다면 더욱 신빙성 있는 정보 제공을 할 수 있으리라 생각합니다.
마지막으로, 키워드 추출 부분에서 전체 텍스트와 단어간의 유사도를 사용한 개념을 응용하여 구직자가 원하는 키워드(연봉, 복지 등)를 입력하면 적절한 기업을 추천해 주는 시스템 또한 생각해 볼 수 있을 것 같습니다.
이번 프로젝트에 관련된 자세한 부분은 제 깃허브에 정리하여 업로드 하겠습니다. 더 자세한 부분을 확인하시려면 제 깃허브를 방문해 주세요.
이상으로 취업 컨텐츠 플랫폼 기반 기업 리뷰 및 취업 팁 요약 프로젝트 포스팅을 마칩니다.
감사합니다.
