
논문에서 소개된 모델 아키텍처의 사용법을 간단히 정리하여 소개하는 포스팅입니다.
Introduction
지난 TabNet: Attentive Interpretable Tabular Learning 논문에서는 정형 데이터를 위한 TabNet 아키텍처를 소개하였습니다. TabNet 아키텍처는 학습 가능한 마스크 로 instance-wise 하게 feature selection을 수행합니다.
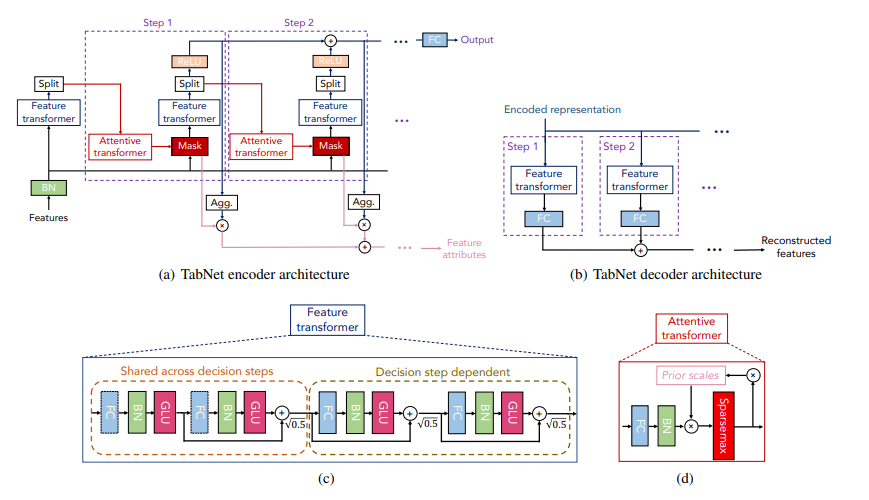
이번 포스팅에서는 pytorch_tabnet 라이브러리를 통해 정형 데이터를 위한 TabNet 아키텍처의 사용 방법에 대해 간단히 알아보겠습니다. Optuna 라이브러리를 사용한 하이퍼파라미터 튜닝 예시까지 확인합니다.
사용한 데이터셋은 Adult 데이터셋입니다. 다음과 같은 특징을 가집니다.
- 이진 분류 문제 (소득이 50K 이상인지 판별)
- 숫자형 특성과 범주형 특성이 모두 존재
모든 코드는 Google의 Colaboratory(Colab) 에서 구현되었습니다.
Setting
구현에 필요한 패키지를 설치합니다.
!pip install pytorch_tabnet
!pip install optunaimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import random
import torch
import torch.nn as nn
import scipy
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from pytorch_tabnet.tab_model import TabNetClassifier
from pytorch_tabnet.pretraining import TabNetPretrainer
import optuna
from optuna import Trial
from optuna.samplers import TPESampler
import warnings
warnings.filterwarnings(action='ignore')def seed_everything(seed = 21):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = Truedef read_split_data():
df = pd.read_csv('/content/drive/MyDrive/Data/adult.csv')
X = {}
y = {}
X['train'], X['test'], y['train'], y['test'] = train_test_split(df.iloc[:, :-1], df.income, test_size = 0.10, random_state=21)
X['train'], X['val'], y['train'], y['val'] = train_test_split(X['train'], y['train'], test_size = 0.10, random_state=21)
return X, yread_split_data()는 adult 데이터셋을 불러와 전체 데이터셋을 훈련 / 검증 / 테스트 데이터셋으로 분할합니다. 아래 코드에는 데이터셋이 Google drive에 저장되어 있는데, 직접 실행을 원하신다면 pd.read_csv()에 적절한 경로를 입력하면 됩니다.
def preprocessing(X, y):
cat_index = X['train'].select_dtypes(['object']).columns
num_index = X['train'].select_dtypes(['int64']).columns
# categorical cardinalities / categorical index for TabNet
cat_cardinalities = []
column_order = {col: idx for idx, col in enumerate(X['train'].columns)}
cat_column_index = [column_order[col] for col in cat_index]
# StandardScaler
ss = StandardScaler()
X['train'][num_index] = ss.fit_transform(X['train'][num_index])
X['val'][num_index] = ss.transform(X['val'][num_index])
X['test'][num_index] = ss.transform(X['test'][num_index])
# LabelEncoder
for col in cat_index:
le = LabelEncoder()
X['train'][col] = le.fit_transform(X['train'][col])
# X_val, X_test에만 존재하는 label이 있을 경우
for label in np.unique(X['val'][col]):
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
for label in np.unique(X['test'][col]):
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
X['val'][col] = le.transform(X['val'][col])
X['test'][col] = le.transform(X['test'][col])
# cardinalities
max_cat = np.max([np.max(X['train'][col]),
np.max(X['val'][col]),
np.max(X['test'][col])]) + 1
cat_cardinalities.append(max_cat)
# y = 1 if > 50K
y['train'] = np.where(y['train']=='>50K', 1.0, 0.0)
y['val'] = np.where(y['val']=='>50K', 1.0, 0.0)
y['test'] = np.where(y['test']=='>50K', 1.0, 0.0)
return X, y, cat_cardinalities, cat_column_indexpreprocessing()을 통해 데이터 전처리를 수행합니다. 적용되는 사항은 아래와 같습니다.
- 숫자형 특성: StandardScaler 적용
- 범주형 특성: LabelEncoder 적용
- 범주형 특성의 경우 특성마다 카디널리티와 컬럼 인덱스를 계산하여 리턴
- 타겟값 y(income)는 income이 50K를 초과하면 1, 아니면 0
StandardScaler를 사용한 것은 간단히 사용할 수 있기 때문입니다. 다른 전처리 방법을 사용하셔도 무방합니다.
Run
이제 모델을 생성하고 훈련합니다. 모델의 하이퍼파라미터는 임의로 설정하였습니다. pytorch_tabnet의 경우 입력으로 np.array와 csr matrix를 받을 수 있습니다.
X, y = read_split_data()
X, y, cat_cardinalities, cat_column_index = preprocessing(X, y)
X['train'] = X['train'].values
X['val'] = X['val'].values
X['test'] = X['test'].values
# This illustrates the behaviour of the model's fit method using Compressed Sparse Row matrices
sparse_X_train = scipy.sparse.csr_matrix(X['train']) # Create a CSR matrix from X_train
sparse_X_valid = scipy.sparse.csr_matrix(X['val']) # Create a CSR matrix from X_valid모델 훈련을 진행합니다. 간단한 예시를 보는 것이므로 15 에포크만 훈련합니다. 훈련 후 검증 손실이 가장 낮았던 파라미터로 저장됩니다.
tabnet_params = {"cat_idxs": cat_column_index,
"cat_dims": cat_cardinalities,
"cat_emb_dim": 2,
"optimizer_fn": torch.optim.Adam,
"optimizer_params": dict(lr=1e-3),
"scheduler_fn": None,
"mask_type": 'sparsemax',
"device_name": 'cuda',
"n_d": 8,
"n_a": 8,
"n_steps": 3,
"gamma": 1.3,
"seed": 21}
clf = TabNetClassifier(**tabnet_params)
max_epochs = 15
# Fitting the model
clf.fit(X_train=sparse_X_train, y_train=y['train'],
eval_set=[(sparse_X_train, y['train']), (sparse_X_valid, y['val'])],
eval_name=['train', 'val'],
eval_metric=['accuracy', 'logloss'],
max_epochs=max_epochs,
patience=10,
batch_size=1024,
virtual_batch_size=128,)출력
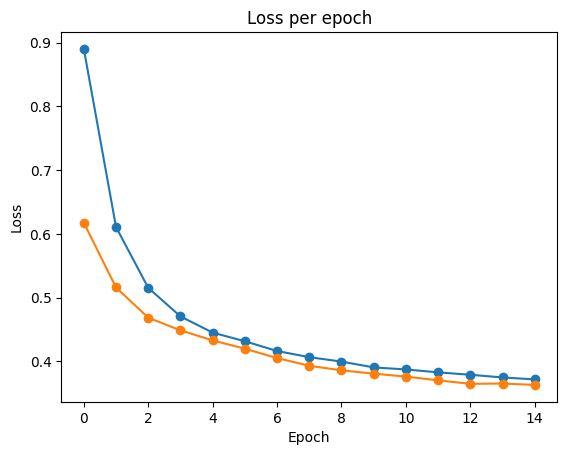
epoch 0 | loss: 0.8903 | train_accuracy: 0.70415 | train_logloss: 0.62085 | val_accuracy: 0.70905 | val_logloss: 0.61757 | 0:00:15s
epoch 1 | loss: 0.61087 | train_accuracy: 0.77622 | train_logloss: 0.5204 | val_accuracy: 0.77866 | val_logloss: 0.516 | 0:00:30s
epoch 2 | loss: 0.51547 | train_accuracy: 0.79025 | train_logloss: 0.47296 | val_accuracy: 0.79504 | val_logloss: 0.46864 | 0:00:41s
epoch 3 | loss: 0.47067 | train_accuracy: 0.79912 | train_logloss: 0.44668 | val_accuracy: 0.79891 | val_logloss: 0.44878 | 0:00:51s
epoch 4 | loss: 0.44522 | train_accuracy: 0.80574 | train_logloss: 0.42845 | val_accuracy: 0.80983 | val_logloss: 0.433 | 0:01:01s
epoch 5 | loss: 0.43168 | train_accuracy: 0.80986 | train_logloss: 0.41552 | val_accuracy: 0.81119 | val_logloss: 0.41996 | 0:01:11s
epoch 6 | loss: 0.4164 | train_accuracy: 0.81338 | train_logloss: 0.402 | val_accuracy: 0.8146 | val_logloss: 0.40528 | 0:01:24s
epoch 7 | loss: 0.40668 | train_accuracy: 0.81783 | train_logloss: 0.38909 | val_accuracy: 0.8187 | val_logloss: 0.39319 | 0:01:36s
epoch 8 | loss: 0.39978 | train_accuracy: 0.82025 | train_logloss: 0.38312 | val_accuracy: 0.81938 | val_logloss: 0.38604 | 0:01:47s
epoch 9 | loss: 0.39062 | train_accuracy: 0.82278 | train_logloss: 0.37639 | val_accuracy: 0.82211 | val_logloss: 0.38084 | 0:01:57s
epoch 10 | loss: 0.38742 | train_accuracy: 0.82341 | train_logloss: 0.37321 | val_accuracy: 0.82279 | val_logloss: 0.37622 | 0:02:07s
epoch 11 | loss: 0.38288 | train_accuracy: 0.82554 | train_logloss: 0.36905 | val_accuracy: 0.83007 | val_logloss: 0.37036 | 0:02:18s
epoch 12 | loss: 0.37908 | train_accuracy: 0.82844 | train_logloss: 0.365 | val_accuracy: 0.8303 | val_logloss: 0.36488 | 0:02:29s
epoch 13 | loss: 0.3749 | train_accuracy: 0.82958 | train_logloss: 0.36138 | val_accuracy: 0.8253 | val_logloss: 0.36536 | 0:02:39s
epoch 14 | loss: 0.37178 | train_accuracy: 0.83046 | train_logloss: 0.35872 | val_accuracy: 0.82734 | val_logloss: 0.36316 | 0:02:50s
Stop training because you reached max_epochs = 15 with best_epoch = 14 and best_val_logloss = 0.36316
/usr/local/lib/python3.10/dist-packages/pytorch_tabnet/callbacks.py:172: UserWarning: Best weights from best epoch are automatically used!
warnings.warn(wrn_msg)# plot losses
plt.plot(clf.history['loss'], marker='o', label='train')
plt.plot(clf.history['val_logloss'], marker='o', label='val')
plt.title('Loss per epoch')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()출력
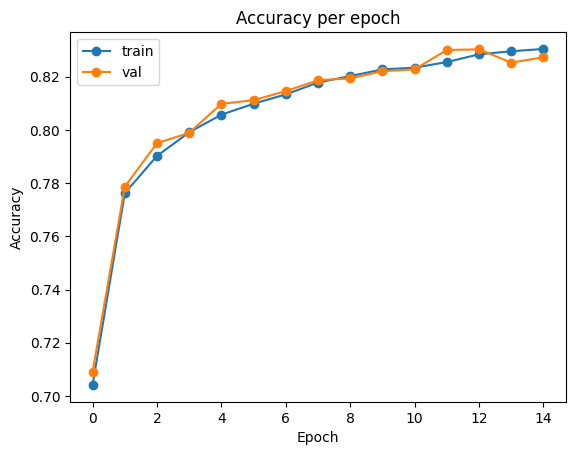
# plot accuracy
plt.plot(clf.history['train_accuracy'], label='train', marker='o')
plt.plot(clf.history['val_accuracy'], label='val', marker='o')
plt.title('Accuracy per epoch')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()출력
테스트 데이터셋에서 평가를 진행합니다.
preds = clf.predict(X['test'])
test_acc = accuracy_score(y_pred=preds, y_true=y['test'])
print('Test acc:', test_acc)출력
Test acc: 0.8286591606960082
Tuning
Optuna 라이브러리를 사용하여 하이퍼파라미터 튜닝을 수행합니다. Optuna 사용 방법에 대해서는 Optuna 튜토리얼을 참고해 주세요.
optuna objective 함수를 정의합니다. 탐색할 하이퍼파라미터의 범위는 pytorch_tabnet
의 github를 참고하였습니다.
# optuna objective
def objective(trial):
n_d_a = trial.suggest_int('n_d_a', 8, 64)
n_steps = trial.suggest_int('n_steps', 3, 10)
gamma = trial.suggest_float('gamma', 1.0, 2.0)
lr = trial.suggest_float('lr', 1e-5, 1e-2)
cat_emb_dim = trial.suggest_int('cat_emb_dim', 1, 4)
tabnet_params = {"cat_idxs": cat_column_index,
"cat_dims": cat_cardinalities,
"cat_emb_dim": 2,
"optimizer_fn": torch.optim.Adam,
"optimizer_params": dict(lr=lr),
"scheduler_fn": None,
"mask_type": 'sparsemax',
"device_name": 'cuda',
"n_d": n_d_a,
"n_a": n_d_a,
"n_steps": n_steps,
"gamma": gamma,
"verbose": 0,
"seed": 21}
clf = TabNetClassifier(**tabnet_params)
max_epochs = 10
# Fitting the model
clf.fit(X_train=sparse_X_train, y_train=y['train'],
eval_set=[(sparse_X_train, y['train']), (sparse_X_valid, y['val'])],
eval_name=['train', 'val'],
eval_metric=['accuracy', 'logloss'],
max_epochs=max_epochs,
batch_size=1024,
virtual_batch_size=128,)
# return minimun loss
return clf.best_cost10 에포크 동안 모델을 훈련한 뒤, 10 에포크 중 가장 작았던 검증 손실(clf.best_cost)을 리턴합니다. 에포크 수, 리턴 값 종류는 임의로 설정한 것이니 다른 방법으로 수정할 수 있습니다.
n_trials=15를 전달하여 15회 탐색을 수행합니다. 최적의 방법은 아닐 수 있습니다.
study = optuna.create_study(study_name='TabNet', direction='minimize', sampler=TPESampler(seed=21))
study.optimize(lambda trial: objective(trial), n_trials=15)
print()
print("Best Score:", study.best_value)
print("Best trial:", study.best_trial.params)출력
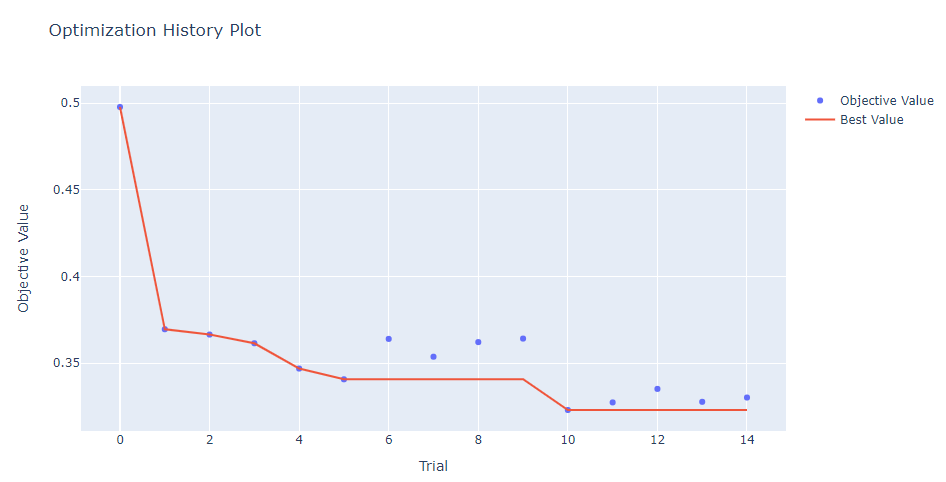
[I 2023-09-05 12:09:02,260] A new study created in memory with name: TabNet
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.49775
[I 2023-09-05 12:11:04,528] Trial 0 finished with value: 0.497748676354725 and parameters: {'n_d_a': 10, 'n_steps': 5, 'gamma': 1.7209663468312297, 'lr': 0.00022594633666033845, 'cat_emb_dim': 1}. Best is trial 0 with value: 0.497748676354725.
Stop training because you reached max_epochs = 10 with best_epoch = 8 and best_val_logloss = 0.36955
[I 2023-09-05 12:13:05,825] Trial 1 finished with value: 0.3695493117804688 and parameters: {'n_d_a': 10, 'n_steps': 5, 'gamma': 1.6639102946247, 'lr': 0.00308806278843642, 'cat_emb_dim': 3}. Best is trial 1 with value: 0.3695493117804688.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.36649
[I 2023-09-05 12:15:29,125] Trial 2 finished with value: 0.36648749477170106 and parameters: {'n_d_a': 11, 'n_steps': 9, 'gamma': 1.1332405192517476, 'lr': 0.0017894653689793888, 'cat_emb_dim': 2}. Best is trial 2 with value: 0.36648749477170106.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.36146
[I 2023-09-05 12:17:52,964] Trial 3 finished with value: 0.36145532329285557 and parameters: {'n_d_a': 57, 'n_steps': 9, 'gamma': 1.9704851253491578, 'lr': 0.0075954325023276726, 'cat_emb_dim': 2}. Best is trial 3 with value: 0.36145532329285557.
Stop training because you reached max_epochs = 10 with best_epoch = 7 and best_val_logloss = 0.34688
[I 2023-09-05 12:20:09,326] Trial 4 finished with value: 0.34687673212281495 and parameters: {'n_d_a': 31, 'n_steps': 8, 'gamma': 1.2706697726731337, 'lr': 0.008542487691193527, 'cat_emb_dim': 4}. Best is trial 4 with value: 0.34687673212281495.
Stop training because you reached max_epochs = 10 with best_epoch = 7 and best_val_logloss = 0.34067
[I 2023-09-05 12:22:17,860] Trial 5 finished with value: 0.3406719760543788 and parameters: {'n_d_a': 51, 'n_steps': 7, 'gamma': 1.1678357652215072, 'lr': 0.002993935993172568, 'cat_emb_dim': 2}. Best is trial 5 with value: 0.3406719760543788.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.36398
[I 2023-09-05 12:24:21,314] Trial 6 finished with value: 0.3639811568004794 and parameters: {'n_d_a': 26, 'n_steps': 6, 'gamma': 1.5443683594576376, 'lr': 0.0021818346888996224, 'cat_emb_dim': 4}. Best is trial 5 with value: 0.3406719760543788.
Stop training because you reached max_epochs = 10 with best_epoch = 7 and best_val_logloss = 0.3537
[I 2023-09-05 12:26:49,135] Trial 7 finished with value: 0.35370463597422713 and parameters: {'n_d_a': 49, 'n_steps': 9, 'gamma': 1.2675218045820724, 'lr': 0.006152098864372861, 'cat_emb_dim': 3}. Best is trial 5 with value: 0.3406719760543788.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.36213
[I 2023-09-05 12:28:53,942] Trial 8 finished with value: 0.3621329834177557 and parameters: {'n_d_a': 30, 'n_steps': 6, 'gamma': 1.8101575494926372, 'lr': 0.006007688961167527, 'cat_emb_dim': 4}. Best is trial 5 with value: 0.3406719760543788.
Stop training because you reached max_epochs = 10 with best_epoch = 6 and best_val_logloss = 0.36416
[I 2023-09-05 12:31:18,719] Trial 9 finished with value: 0.36416007058714683 and parameters: {'n_d_a': 35, 'n_steps': 9, 'gamma': 1.8588894711682389, 'lr': 0.00788656698497452, 'cat_emb_dim': 4}. Best is trial 5 with value: 0.3406719760543788.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.32297
[I 2023-09-05 12:33:05,599] Trial 10 finished with value: 0.32296540432319226 and parameters: {'n_d_a': 47, 'n_steps': 3, 'gamma': 1.1169525121171846, 'lr': 0.004003327754543372, 'cat_emb_dim': 1}. Best is trial 10 with value: 0.32296540432319226.
Stop training because you reached max_epochs = 10 with best_epoch = 8 and best_val_logloss = 0.32734
[I 2023-09-05 12:34:53,511] Trial 11 finished with value: 0.32733886584840094 and parameters: {'n_d_a': 47, 'n_steps': 3, 'gamma': 1.0221741264181599, 'lr': 0.004399067563874516, 'cat_emb_dim': 1}. Best is trial 10 with value: 0.32296540432319226.
Stop training because you reached max_epochs = 10 with best_epoch = 8 and best_val_logloss = 0.33514
[I 2023-09-05 12:36:43,127] Trial 12 finished with value: 0.3351395237441098 and parameters: {'n_d_a': 45, 'n_steps': 3, 'gamma': 1.0135898404859338, 'lr': 0.004625214953709157, 'cat_emb_dim': 1}. Best is trial 10 with value: 0.32296540432319226.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.32768
[I 2023-09-05 12:38:36,589] Trial 13 finished with value: 0.3276812458162435 and parameters: {'n_d_a': 64, 'n_steps': 3, 'gamma': 1.0347330464390387, 'lr': 0.004387414907740412, 'cat_emb_dim': 1}. Best is trial 10 with value: 0.32296540432319226.
Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_logloss = 0.33016
[I 2023-09-05 12:40:40,320] Trial 14 finished with value: 0.33015582241187647 and parameters: {'n_d_a': 42, 'n_steps': 4, 'gamma': 1.3157904843973294, 'lr': 0.005515244660750329, 'cat_emb_dim': 1}. Best is trial 10 with value: 0.32296540432319226.
Best Score: 0.32296540432319226
Best trial: {'n_d_a': 47, 'n_steps': 3, 'gamma': 1.1169525121171846, 'lr': 0.004003327754543372, 'cat_emb_dim': 1}optuna.visualization.plot_optimization_history(study)출력
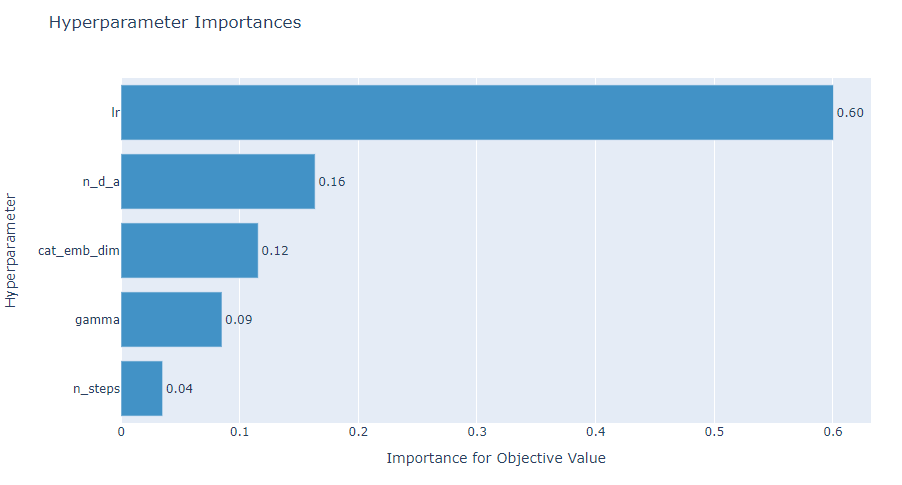
optuna.visualization.plot_param_importances(study)출력
study.best_trial.params출력
{'n_d_a': 47,
'n_steps': 3,
'gamma': 1.1169525121171846,
'lr': 0.004003327754543372,
'cat_emb_dim': 1}최적의 하이퍼파라미터 조합으로 모델을 다시 훈련합니다.
tabnet_params = {"cat_idxs": cat_column_index,
"cat_dims": cat_cardinalities,
"cat_emb_dim": study.best_trial.params['cat_emb_dim'],
"optimizer_fn": torch.optim.Adam,
"optimizer_params": dict(lr=study.best_trial.params['lr']),
"scheduler_fn": None,
"mask_type": 'sparsemax',
"device_name": 'cuda',
"n_d": study.best_trial.params['n_d_a'],
"n_a": study.best_trial.params['n_d_a'],
"n_steps": study.best_trial.params['n_steps'],
"gamma": study.best_trial.params['gamma'],
"seed": 21}
clf = TabNetClassifier(**tabnet_params)
max_epochs = 15
# Fitting the model
clf.fit(X_train=sparse_X_train, y_train=y['train'],
eval_set=[(sparse_X_train, y['train']), (sparse_X_valid, y['val'])],
eval_name=['train', 'val'],
eval_metric=['accuracy', 'logloss'],
max_epochs=max_epochs,
patience=10,
batch_size=1024,
virtual_batch_size=128,)출력
epoch 0 | loss: 0.49173 | train_accuracy: 0.77389 | train_logloss: 0.47868 | val_accuracy: 0.77047 | val_logloss: 0.49163 | 0:00:10s
epoch 1 | loss: 0.39038 | train_accuracy: 0.82703 | train_logloss: 0.38494 | val_accuracy: 0.83076 | val_logloss: 0.39008 | 0:00:21s
epoch 2 | loss: 0.3699 | train_accuracy: 0.83623 | train_logloss: 0.36424 | val_accuracy: 0.83348 | val_logloss: 0.37667 | 0:00:32s
epoch 3 | loss: 0.35702 | train_accuracy: 0.84047 | train_logloss: 0.35016 | val_accuracy: 0.84008 | val_logloss: 0.36179 | 0:00:42s
epoch 4 | loss: 0.35281 | train_accuracy: 0.84513 | train_logloss: 0.34084 | val_accuracy: 0.84122 | val_logloss: 0.35128 | 0:00:53s
epoch 5 | loss: 0.34478 | train_accuracy: 0.84533 | train_logloss: 0.33774 | val_accuracy: 0.84167 | val_logloss: 0.35046 | 0:01:04s
epoch 6 | loss: 0.34343 | train_accuracy: 0.84834 | train_logloss: 0.33089 | val_accuracy: 0.84031 | val_logloss: 0.34412 | 0:01:14s
epoch 7 | loss: 0.3344 | train_accuracy: 0.84927 | train_logloss: 0.32555 | val_accuracy: 0.84304 | val_logloss: 0.33979 | 0:01:25s
epoch 8 | loss: 0.32865 | train_accuracy: 0.85228 | train_logloss: 0.31886 | val_accuracy: 0.8485 | val_logloss: 0.33225 | 0:01:36s
epoch 9 | loss: 0.32549 | train_accuracy: 0.85117 | train_logloss: 0.31835 | val_accuracy: 0.84895 | val_logloss: 0.32744 | 0:01:47s
epoch 10 | loss: 0.32283 | train_accuracy: 0.85268 | train_logloss: 0.31625 | val_accuracy: 0.84918 | val_logloss: 0.32597 | 0:01:57s
epoch 11 | loss: 0.32025 | train_accuracy: 0.85261 | train_logloss: 0.31593 | val_accuracy: 0.85077 | val_logloss: 0.32358 | 0:02:10s
epoch 12 | loss: 0.31826 | train_accuracy: 0.85362 | train_logloss: 0.3145 | val_accuracy: 0.84986 | val_logloss: 0.32124 | 0:02:21s
epoch 13 | loss: 0.31902 | train_accuracy: 0.85321 | train_logloss: 0.31264 | val_accuracy: 0.85123 | val_logloss: 0.32134 | 0:02:30s
epoch 14 | loss: 0.31913 | train_accuracy: 0.85268 | train_logloss: 0.31502 | val_accuracy: 0.851 | val_logloss: 0.32382 | 0:02:41s
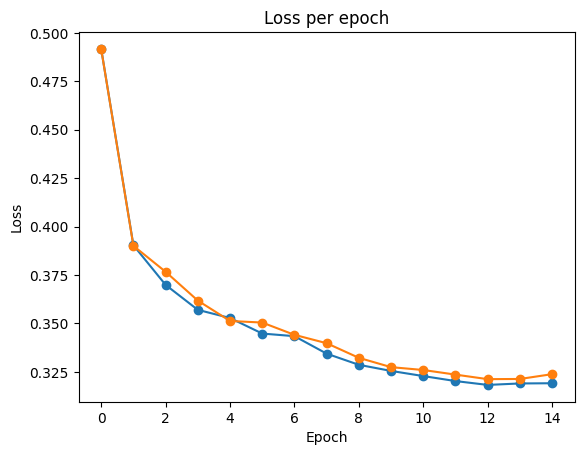
Stop training because you reached max_epochs = 15 with best_epoch = 12 and best_val_logloss = 0.32124# plot losses
plt.plot(clf.history['loss'], marker='o', label='train')
plt.plot(clf.history['val_logloss'], marker='o', label='val')
plt.title('Loss per epoch')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()출력
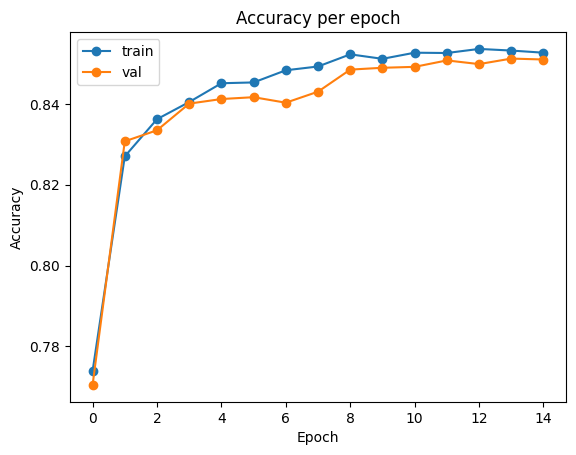
# plot accuracy
plt.plot(clf.history['train_accuracy'], label='train', marker='o')
plt.plot(clf.history['val_accuracy'], label='val', marker='o')
plt.title('Accuracy per epoch')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()출력
테스트 데이터셋에서 최종 평가를 진행합니다.
preds = clf.predict(X['test'])
test_acc = accuracy_score(y_pred=preds, y_true=y['test'])
print('Test acc:', test_acc)출력
Test acc: 0.8503582395087002
Pre-training
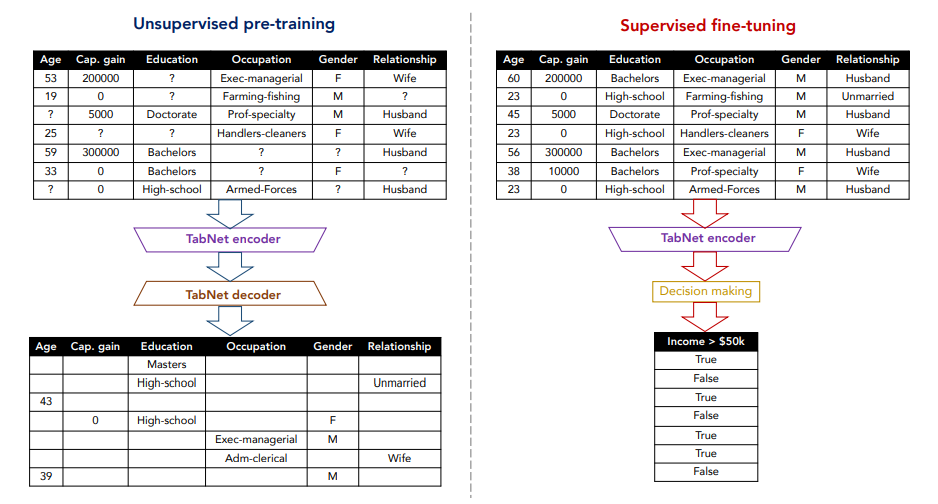
TabNet은 unsupervised pre-training(Self-supervised tabular learning)을 지원합니다. TabNetPretrainer를 통해 구현할 수 있습니다.
# TabNetPretrainer
unsupervised_model = TabNetPretrainer(cat_idxs=cat_column_index,
cat_dims=cat_cardinalities,
cat_emb_dim=1,
optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=1e-3),
mask_type='sparsemax',
n_shared_decoder=1,
n_indep_decoder=1,
verbose=5,)
unsupervised_model.fit(X_train=X['train'],
eval_set=[X['val']],
max_epochs=50 ,
patience=5,
batch_size=2048,
virtual_batch_size=128,
num_workers=0,
drop_last=False,
pretraining_ratio=0.5,)출력
epoch 0 | loss: 18.36013| val_0_unsup_loss_numpy: 7.435939788818359| 0:00:01s
epoch 5 | loss: 2.99452 | val_0_unsup_loss_numpy: 1.9117200374603271| 0:00:10s
epoch 10 | loss: 1.26313 | val_0_unsup_loss_numpy: 1.2095400094985962| 0:00:19s
epoch 15 | loss: 1.0563 | val_0_unsup_loss_numpy: 1.0479300022125244| 0:00:28s
epoch 20 | loss: 1.00818 | val_0_unsup_loss_numpy: 0.999180018901825| 0:00:36s
epoch 25 | loss: 0.99364 | val_0_unsup_loss_numpy: 0.9830700159072876| 0:00:46s
epoch 30 | loss: 0.99167 | val_0_unsup_loss_numpy: 0.9723100066184998| 0:00:55s
epoch 35 | loss: 0.97055 | val_0_unsup_loss_numpy: 0.9566299915313721| 0:01:04s
epoch 40 | loss: 0.97176 | val_0_unsup_loss_numpy: 0.9371100068092346| 0:01:14s
epoch 45 | loss: 0.97622 | val_0_unsup_loss_numpy: 0.9140400290489197| 0:01:23s
Stop training because you reached max_epochs = 50 with best_epoch = 49 and best_val_0_unsup_loss_numpy = 0.8928999900817871fit()에 from_unsupervised=unsupervised_model를 전달합니다.
clf = TabNetClassifier(**tabnet_params)
max_epochs = 15
# Fitting the model
clf.fit(X_train=sparse_X_train, y_train=y['train'],
eval_set=[(sparse_X_train, y['train']), (sparse_X_valid, y['val'])],
eval_name=['train', 'val'],
eval_metric=['accuracy', 'logloss'],
max_epochs=max_epochs,
patience=10,
batch_size=1024,
virtual_batch_size=128,
from_unsupervised=unsupervised_model)출력
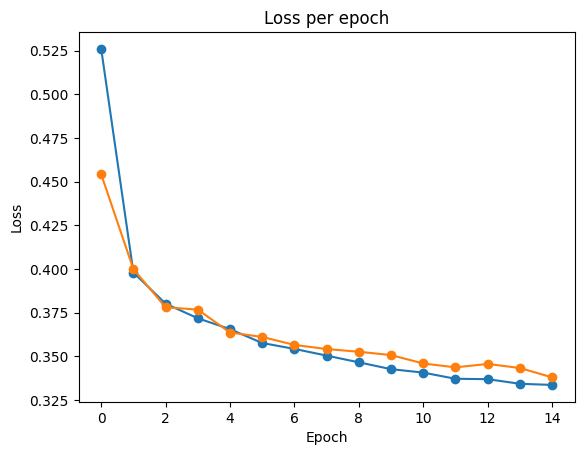
epoch 0 | loss: 0.52595 | train_accuracy: 0.7996 | train_logloss: 0.44058 | val_accuracy: 0.79254 | val_logloss: 0.45424 | 0:00:11s
epoch 1 | loss: 0.39799 | train_accuracy: 0.81381 | train_logloss: 0.38998 | val_accuracy: 0.81324 | val_logloss: 0.3999 | 0:00:22s
epoch 2 | loss: 0.38019 | train_accuracy: 0.82409 | train_logloss: 0.36878 | val_accuracy: 0.81733 | val_logloss: 0.37811 | 0:00:32s
epoch 3 | loss: 0.37182 | train_accuracy: 0.82736 | train_logloss: 0.36359 | val_accuracy: 0.81938 | val_logloss: 0.3768 | 0:00:43s
epoch 4 | loss: 0.3656 | train_accuracy: 0.83031 | train_logloss: 0.3561 | val_accuracy: 0.82257 | val_logloss: 0.36368 | 0:00:54s
epoch 5 | loss: 0.35767 | train_accuracy: 0.83592 | train_logloss: 0.35132 | val_accuracy: 0.82552 | val_logloss: 0.36114 | 0:01:06s
epoch 6 | loss: 0.3543 | train_accuracy: 0.84063 | train_logloss: 0.34489 | val_accuracy: 0.83121 | val_logloss: 0.35658 | 0:01:17s
epoch 7 | loss: 0.35046 | train_accuracy: 0.84154 | train_logloss: 0.34137 | val_accuracy: 0.82848 | val_logloss: 0.35422 | 0:01:26s
epoch 8 | loss: 0.34662 | train_accuracy: 0.8447 | train_logloss: 0.33657 | val_accuracy: 0.8303 | val_logloss: 0.35268 | 0:01:38s
epoch 9 | loss: 0.34272 | train_accuracy: 0.84442 | train_logloss: 0.33577 | val_accuracy: 0.83189 | val_logloss: 0.35076 | 0:01:49s
epoch 10 | loss: 0.34074 | train_accuracy: 0.84743 | train_logloss: 0.33253 | val_accuracy: 0.83553 | val_logloss: 0.34596 | 0:02:00s
epoch 11 | loss: 0.33721 | train_accuracy: 0.84854 | train_logloss: 0.32871 | val_accuracy: 0.83826 | val_logloss: 0.34375 | 0:02:12s
epoch 12 | loss: 0.33698 | train_accuracy: 0.84735 | train_logloss: 0.32889 | val_accuracy: 0.83644 | val_logloss: 0.3457 | 0:02:22s
epoch 13 | loss: 0.33435 | train_accuracy: 0.84732 | train_logloss: 0.32643 | val_accuracy: 0.84031 | val_logloss: 0.34337 | 0:02:34s
epoch 14 | loss: 0.33369 | train_accuracy: 0.84851 | train_logloss: 0.32385 | val_accuracy: 0.84167 | val_logloss: 0.33802 | 0:02:44s
Stop training because you reached max_epochs = 15 with best_epoch = 14 and best_val_logloss = 0.33802# plot losses
plt.plot(clf.history['loss'], marker='o', label='train')
plt.plot(clf.history['val_logloss'], marker='o', label='val')
plt.title('Loss per epoch')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()출력
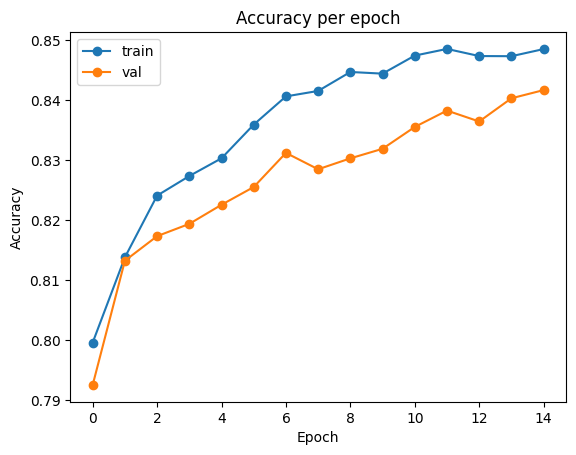
# plot accuracy
plt.plot(clf.history['train_accuracy'], label='train', marker='o')
plt.plot(clf.history['val_accuracy'], label='val', marker='o')
plt.title('Accuracy per epoch')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()출력
preds = clf.predict(X['test'])
test_acc = accuracy_score(y_pred=preds, y_true=y['test'])
print('Test acc:', test_acc)출력
Test acc: 0.84503582395087
TabNetPretrainer의 하이퍼파라미터를 같이 튜닝하지 않았기 때문의 최적의 결과가 아닙니다.
이상으로 TabNet 아키텍처의 간단한 사용 방법에 대해 알아보았습니다. 위의 방법이 모델 성능을 위한 최적의 방법이 아닐 수 있습니다. 하이퍼파라미터 탐색 범위 수정, 모델 훈련 시 scheduler 사용 등 추가적인 방법으로 더 좋은 성능을 달성할 수도 있습니다.
해당 아키텍처에 대해 더 많은 정보를 확인하시려면 pytorch_tabnet의 github를 참고해 주세요.
감사합니다.
