1. Perceptron
single-Layer Neural Network
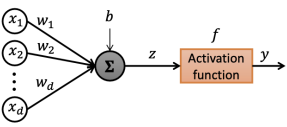
activation function f
-
unit step function
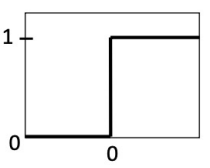
-
sigmoid function
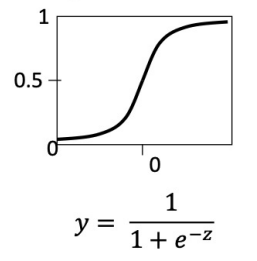
-
ReLU function
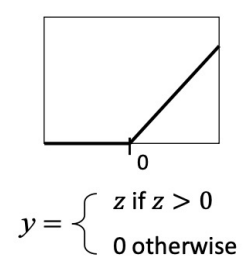
activation function의 중요한 점은 non-linearity을 가진다는 것이다.
이런 activation function을 안쓰게 되면 무조건 linearity한 값만을 가질 것이다.
2. Training Perceptron
딥러닝에서 학습을 한다는 것은 에 임의의 데이터 x가 들어가 나온 예측값인 과 실제 정답값인 의 차 의 값(=Loss)을 최소화 하는 것을 목표로 파라미터 를 학습(업데이트)하는 것을 의미한다.
이런 Loss를 줄이는데 사용되는 것은 Gradient Descent다.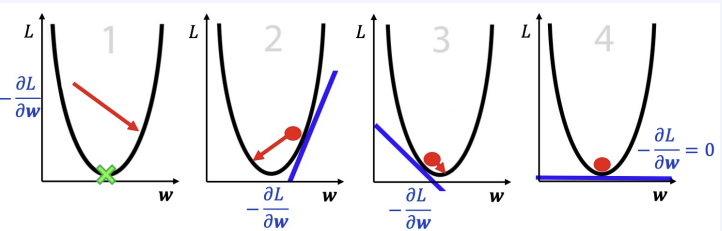
그림을 보면 Gradient Descent의 값이 단계 마다 나오는 것을 알 수 있다. 마지막 결과에서 첫번째 Gradient를 계산하기 위해 역전파 방법을 사용하는데 이때 사용 되는 것이 Chain Rule 이다. 
- Gradient Descent의 문제점
- 많은 데이터를 필요로 한다.
- 기울기를 계산하는 과정에 많은 시간이 소모 된다.
- 많은 epochs(iterations)이 요구된다
3. Multi-Layer Perceptron(MLP)
말 대로 하나의 layer가 아니라 여러개의 layer를 층마다 쌓아 놓은거라고 이해하면 된다.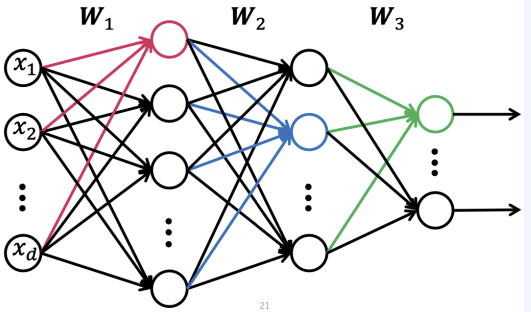
그림의 각 동그라미를 노드라고 하는데, 노드마다 non-linear한 activation function이 있기 때문에 아주 복잡한 모델을 표현할 수 있게 되고, 그 결과 더 좋은 성능을 보여준다.
4. Loss Functions
- Cross entropy loss(classification)
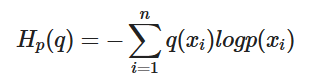
- multi-label soft-margin loss
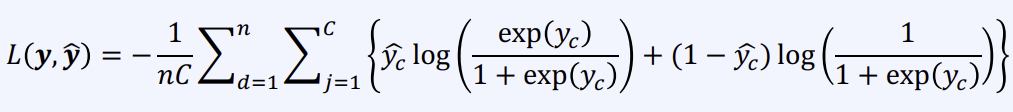
- Mean squared error(regression)
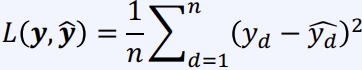
5. Stochastic Gradient Descent(SGD)
- 각각의 데이터 하나하나에 weight값을 업데이트 한다면 하나의 잘못되 데이터에도 예민하게 반응하는 문제가 발생한다.
- Minibatch SGD는 몇개의 데이터를 하나의 집단으로 만들어서 weight값을 업데이트 하는 것을 말한다. 하나의 잘못된 noise 데이터에 덜 민감하다.
- 대부분의 optimization 방법은 SGD에 기반 두었다.(Momentum, Adam ...)
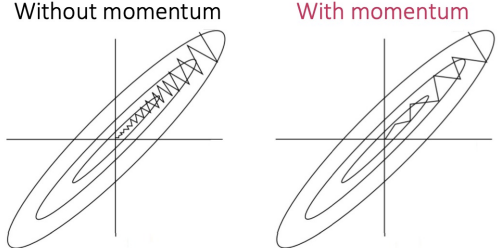
6. Momentum (관성)
- 이전의 학습방향을 기억하고 반영 된다.
다음과 같은 수식을 보면 weight를 업데이트 하는 과정에서 를 추가로 넣어주는 것을 통해 확인하면 된다.
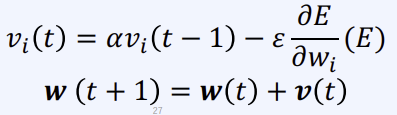
[강의]패스트 캠퍼스(한 번에 끝내는 컴퓨터비전 초격차 패키지)
