분할정복이란?
방대한 문제를 조금씩 조금씩 나눠가면서 용이하게 풀 수 있는 문제 단위로 나눈 후 해결하고, 결과값을 다시 합쳐서 해결하는 방법(재귀적).
알고리즘단계
-
분할(Divide)
기존문제를 작은 부분문제들로 나눈다.- 분할과정
Base case: 이미 문제가 충분히 작아서, 더 작은 문제로 나누지 않아도 바로 답을 알 수 있는 경우
Recursive case : 문제가 커서 바로 답을 알 수 없어서, 같은 형태의 부분 문제들로 쪼개서 풀어야 하는 경우
- 분할과정
-
정복(Conquer)
각 부분문제를 해결한다.
상황에따라 다시 divide, conquer, combine 으로 쪼개질 수 있다. -
결합(Combine)
부분문제들의 해결한 것을 통해 기존문제를 해결.
재귀 알고리즘과 분할정복 알고리즘의 차이
재귀 알고리즘: 재귀적으로 문제를 해결하지만 반드시 분할과 정복의 구조를 따르지는 않습니다.
분할정복 알고리즘: 문제를 분할하고, 정복하며, 결합하여 해결하는 재귀 알고리즘의 특수 형태입니다.
-
재귀 알고리즘:
- 재귀 알고리즘은 함수가 자기 자신을 호출하여 문제를 해결하는 방식입니다.
- 단순한 재귀 알고리즘은 보통 더 작은 하위 문제로 직접적으로 재귀 호출을 수행합니다.
- 예시: 피보나치 수열 계산, 팩토리얼 계산 등.
-
분할정복 알고리즘:
- 분할정복 알고리즘은 문제를 더 작은 하위 문제로 나눈 후, 각 하위 문제를 독립적으로 해결하고, 그 결과를 결합하여 전체 문제를 해결합니다.
- 재귀 알고리즘의 한 유형이지만, 항상 "분할(Divide)", "정복(Conquer)", "결합(Combine)"의 세 단계를 따릅니다.
- 예시: 병합 정렬, 퀵 정렬, 이진 탐색 등.
병합,합병정렬(merge sort)
리스트를 절반으로 나누고(분할) 각 부분을 재귀적으로 정렬한 후(정복), 두 정렬된 부분을 합쳐서 전체를 정렬(병합)하는 알고리즘.
분할(Divide): 입력 리스트를 같은 크기의 두 개의 부분 리스트로 분할합니다.
이때 분할은 리스트의 중간 지점에서 수행됩니다.
정복(Conquer): 각 부분 리스트를 재귀적으로 병합정렬을 이용해 정렬합니다.
이 과정은 입력 리스트의 크기가 충분히 작아질 때까지 반복됩니다.
병합(Merge): 정렬된 두 부분 리스트를 하나의 정렬된 리스트로 병합합니다.
배열 예시
주로 배열이나 문자열 같은 큰 규모의 데이터셋을 처리한다.

배열을 더작은 배열로 나누고, 가장 작은 하위배열부터 정렬하는 방식.
초기배열
첫번째분할
두번째분할
세번째분할
첫번째정렬
두번째정렬
세번쩨병합정렬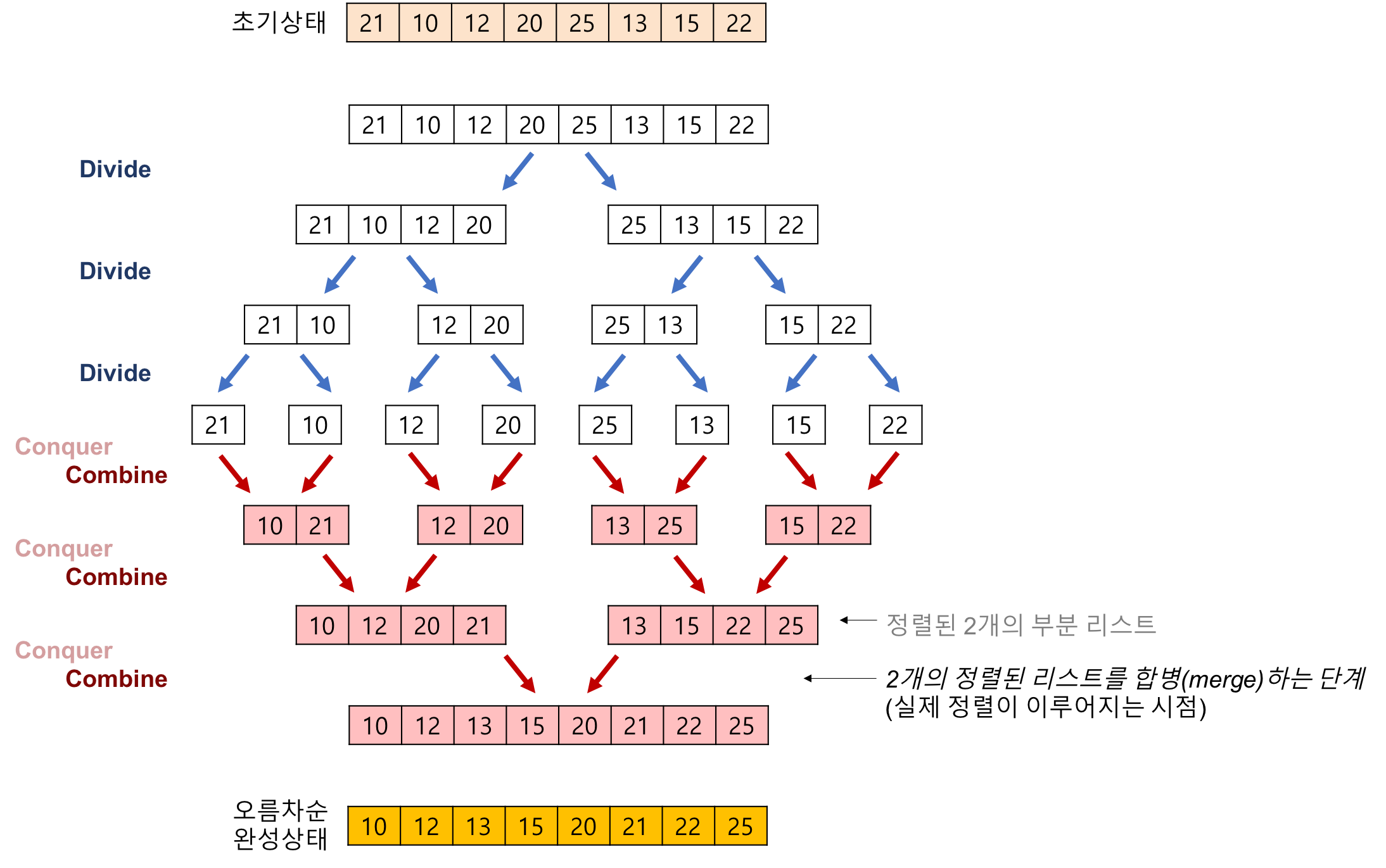
- 오름차순
- 하나씩 비교후 작은값을 새 리스트로.
코드
// 병합 정렬 함수
function mergeSort(arr) {
// 배열의 길이가 1 이하인 경우, 이미 정렬된 상태이므로 배열을 그대로 반환합니다.
if (arr.length <= 1) {
return arr;
}
// 배열을 중간 지점에서 두 개의 하위 배열로 분할합니다.
const mid = Math.floor(arr.length / 2);
const left = arr.slice(0, mid);
const right = arr.slice(mid);
// 재귀적으로 하위 배열을 정렬합니다.
return merge(mergeSort(left), mergeSort(right));
}
// 두 개의 정렬된 배열을 병합하는 함수
function merge(left, right) {
let result = [];
let leftIndex = 0;
let rightIndex = 0;
// 두 배열의 요소를 비교하여 작은 요소를 결과 배열에 추가합니다.
while (leftIndex < left.length && rightIndex < right.length) {
if (left[leftIndex] < right[rightIndex]) {
result.push(left[leftIndex]);
leftIndex++;
} else {
result.push(right[rightIndex]);
rightIndex++;
}
}
// 왼쪽 배열에 남은 요소를 결과 배열에 추가합니다.
return result.concat(left.slice(leftIndex)).concat(right.slice(rightIndex));
}
// 예제 사용
const array = [34, 7, 23, 32, 5, 62];
console.log(mergeSort(array)); // [5, 7, 23, 32, 34, 62]
코드 설명
병합 정렬 함수 (merge Sort)
-
Base Case:
if (arr.length <= 1) { return arr; }- 배열의 길이가 1 이하인 경우, 이미 정렬된 상태이므로 배열을 그대로 반환합니다.
-
분할(Divide):
const mid = Math.floor(arr.length / 2); const left = arr.slice(0, mid); const right = arr.slice(mid);- 배열을 중간 지점에서 두 개의 하위 배열로 분할합니다.
mid는 배열을 반으로 나누는 인덱스를 계산합니다.left는 배열의 왼쪽 절반을,right는 배열의 오른쪽 절반을 의미합니다.
-
재귀 호출(Recursive Call):
return merge(mergeSort(left), mergeSort(right));mergeSort함수를 재귀적으로 호출하여 하위 배열을 정렬합니다.- 정렬된 두 하위 배열을
merge함수로 병합합니다.
병합 함수 (merge)
-
초기 설정:
let result = []; let leftIndex = 0; let rightIndex = 0;- 결과 배열을 저장할 빈 배열
result를 초기화합니다. - 두 배열의 인덱스를 관리하기 위해
leftIndex와rightIndex를 초기화합니다.
- 결과 배열을 저장할 빈 배열
-
병합(Merge):
while (leftIndex < left.length && rightIndex < right.length) { if (left[leftIndex] < right[rightIndex]) { result.push(left[leftIndex]); leftIndex++; } else { result.push(right[rightIndex]); rightIndex++; } }left와right배열의 현재 요소를 비교하여 더 작은 요소를result배열에 추가합니다.- 해당 요소가 추가된 배열의 인덱스를 증가시킵니다.
-
남은 요소 추가:
return result.concat(left.slice(leftIndex)).concat(right.slice(rightIndex));left배열에 남은 요소를result배열에 추가합니다.right배열에 남은 요소를result배열에 추가합니다.- 두 배열 중 하나가 먼저 끝날 수 있으므로 남은 요소를 처리합니다.
예제 사용
const array = [34, 7, 23, 32, 5, 62];
console.log(mergeSort(array)); // [5, 7, 23, 32, 34, 62]
mergeSort함수를 호출하여 배열을 정렬합니다.- 결과는 정렬된 배열
[5, 7, 23, 32, 34, 62]입니다.
병합 정렬(Merge Sort)의 장단점
-
장점:
- 안정성: 동일한 값을 가진 요소들의 상대적인 순서가 유지됩니다.
- 예측 가능성: 최악의 경우에도 시간 복잡도가 O(n log n)으로 일정합니다.
- 외부 정렬: 대규모 데이터를 디스크에 저장하고 작업하는 외부 정렬에 적합합니다.
-
단점:
- 공간 복잡도: 추가적인 메모리 공간 O(n)이 필요합니다.
- 캐시 효율성: 병합 정렬은 연속적인 메모리 접근 패턴을 가지지 않아 캐시 효율성이 낮습니다.
퀵정렬(quick sort)
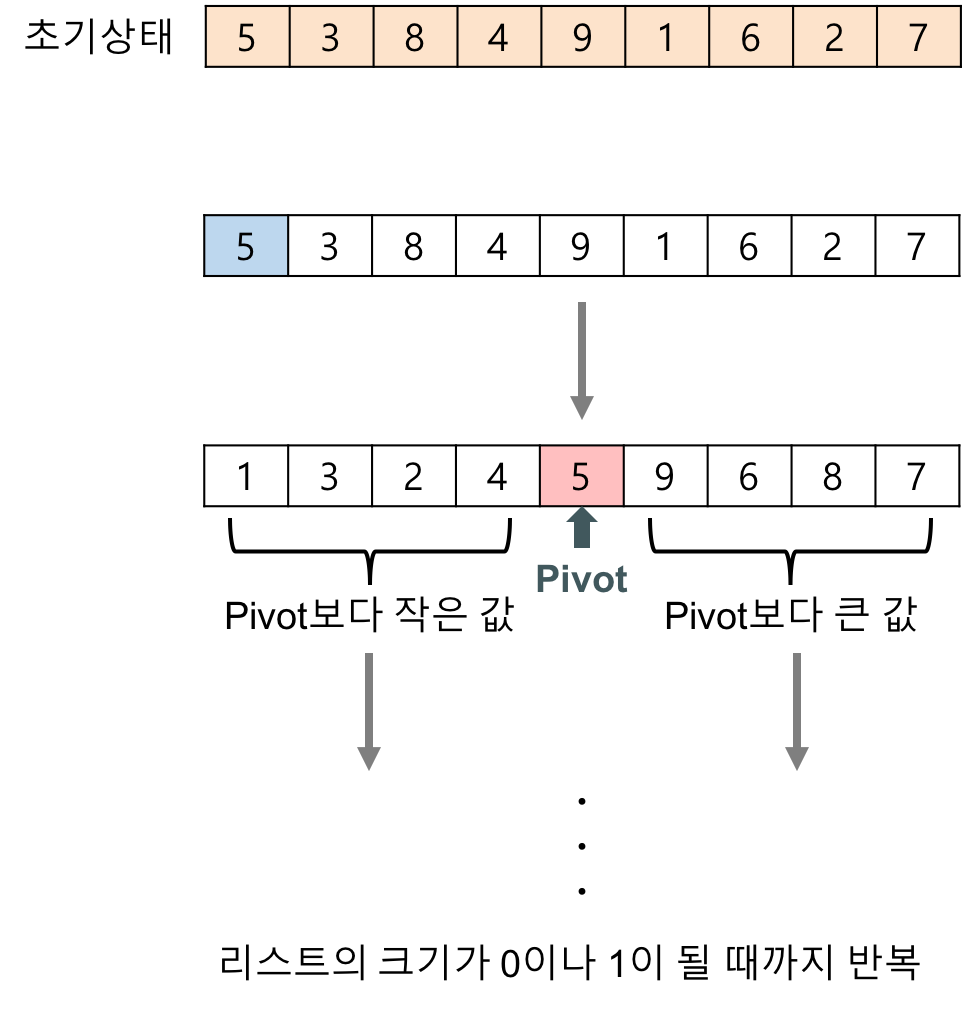
배열에서 하나의 피벗(pivot)을 선택하고, 피벗을 기준으로 배열을 두 부분으로 나눈 후, 각 부분을 재귀적으로 정렬하는 방식.
코드
// 퀵 정렬 함수
function quickSort(arr) {
// 배열의 길이가 1 이하인 경우, 이미 정렬된 상태이므로 배열을 그대로 반환합니다.
if (arr.length <= 1) {
return arr;
}
// 피벗을 배열의 중간 요소로 선택합니다.
const pivot = arr[Math.floor(arr.length / 2)];
const left = [];
const right = [];
const equal = [];
// 배열을 피벗을 기준으로 세 부분으로 분할합니다.
for (let num of arr) {
if (num < pivot) {
left.push(num);
} else if (num > pivot) {
right.push(num);
} else {
equal.push(num);
}
}
// 재귀적으로 하위 배열을 정렬하고, 정렬된 배열을 병합합니다.
return quickSort(left).concat(equal).concat(quickSort(right));
}
// 예제 사용
const array = [34, 7, 23, 32, 5, 62];
console.log(quickSort(array)); // [5, 7, 23, 32, 34, 62]
코드 설명
퀵 정렬 함수 (quickSort)
-
Base Case:
if (arr.length <= 1) { return arr; }- 배열의 길이가 1 이하인 경우, 이미 정렬된 상태이므로 배열을 그대로 반환합니다.
-
피벗 선택(Pivot Selection):
const pivot = arr[Math.floor(arr.length / 2)];- 배열의 중간 요소를 피벗으로 선택합니다.
- 다른 방법으로는 첫 번째 요소나 마지막 요소를 피벗으로 선택할 수도 있습니다.
-
분할(Divide):
const left = []; const right = []; const equal = []; for (let num of arr) { if (num < pivot) { left.push(num); } else if (num > pivot) { right.push(num); } else { equal.push(num); } }- 배열의 각 요소를 피벗과 비교하여
left,right,equal세 부분으로 나눕니다. left에는 피벗보다 작은 요소들,right에는 피벗보다 큰 요소들,equal에는 피벗과 같은 요소들을 저장합니다.
- 배열의 각 요소를 피벗과 비교하여
-
재귀 호출(Recursive Call) 및 병합(Concatenate):
return quickSort(left).concat(equal).concat(quickSort(right));quickSort함수를 재귀적으로 호출하여left와right하위 배열을 정렬합니다.- 정렬된
left배열,equal배열, 정렬된right배열을 병합하여 최종 정렬된 배열을 반환합니다.
예제 사용
const array = [34, 7, 23, 32, 5, 62];
console.log(quickSort(array)); // [5, 7, 23, 32, 34, 62]quickSort함수를 호출하여 배열을 정렬합니다.- 결과는 정렬된 배열
[5, 7, 23, 32, 34, 62]입니다.
퀵 정렬 과정 시각화
-
초기 배열:
[34, 7, 23, 32, 5, 62] -
첫 번째 피벗 선택: 피벗 = 23
left= [7, 5]equal= [23]right= [34, 32, 62]
-
재귀 호출 및 정렬:
quickSort(left)호출: [7, 5] -> [5, 7]quickSort(right)호출: [34, 32, 62] -> [32, 34, 62]
-
병합:
[5, 7].concat([23]).concat([32, 34, 62]) = [5, 7, 23, 32, 34, 62]
최종적으로, 배열이 정렬된 상태로 반환됩니다.
퀵 정렬(Quick Sort)의 장단점
-
장점:
- 평균 시간 복잡도: 대부분의 경우 O(n log n)으로 매우 빠릅니다.
- 공간 효율성: 제자리 정렬(in-place sort)로 추가적인 메모리 공간이 거의 필요하지 않습니다.
- 캐시 효율성: 연속적인 메모리 접근 패턴을 가져 캐시 효율성이 높습니다.
-
단점:
- 최악의 경우 시간 복잡도: 피벗 선택이 불균형하게 이루어질 경우 O(n^2)으로 성능이 저하될 수 있습니다.
- 안정성 부족: 기본적인 퀵 정렬은 안정적이지 않아서 동일한 값을 가진 요소들의 상대적인 순서가 유지되지 않습니다.
이진탐색(binary search)
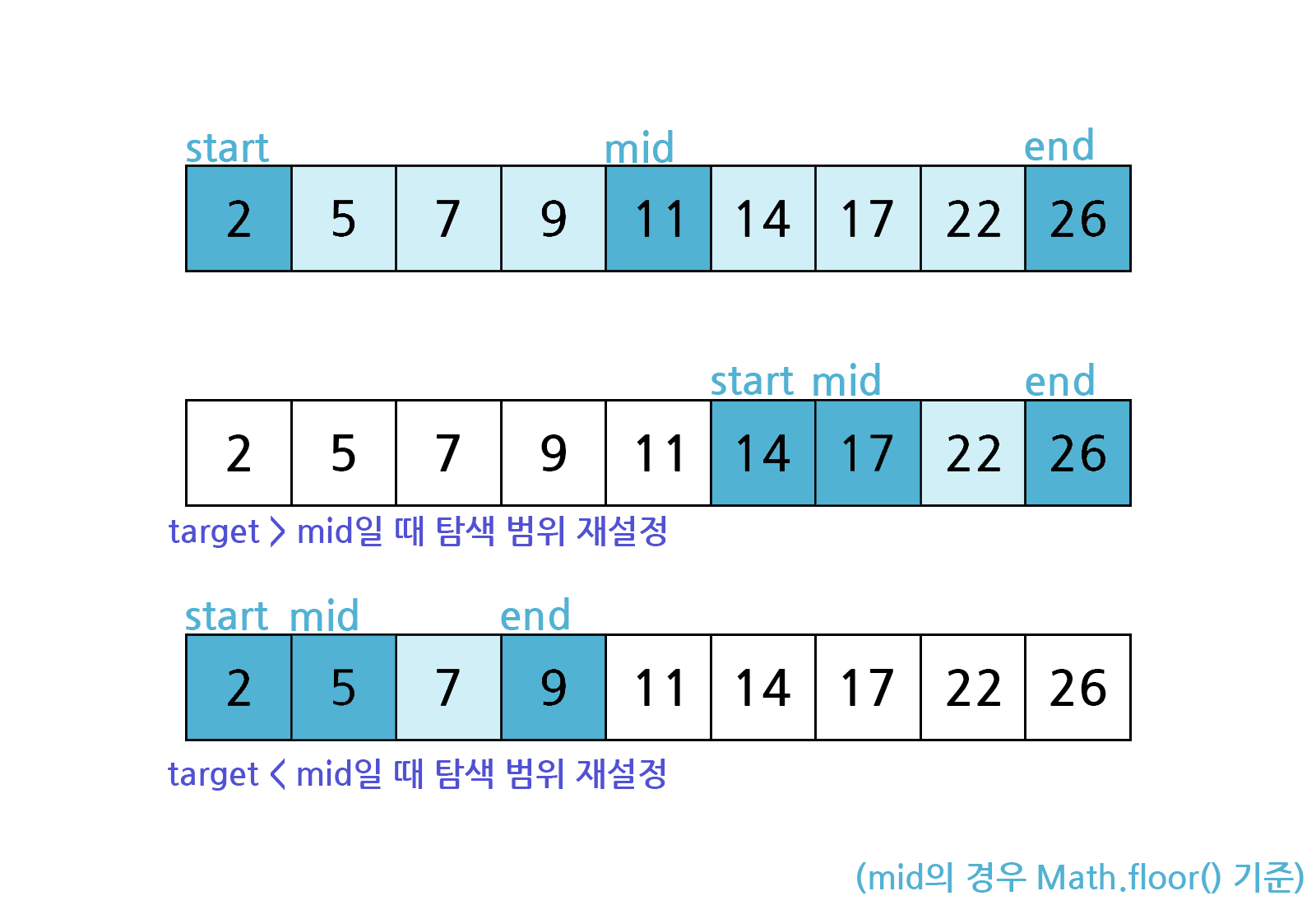
오름차순으로 정렬된 리스트에서 특정한 값의 위치를 찾는 알고리즘.
찾는 값(target)과 중간값(mid)을 비교하여, 그 결과에 따라 탐색 범위를 계속해서 재설정하는 방식.
정렬된 배열에서 중간 요소를 선택하고, 찾고자 하는 값과 비교하여 절반으로 나누어 탐색을 반복.
이진 탐색의 단계
-
중간 값 선택:
배열의 중간 값을 선택합니다. -
값 비교:
찾고자 하는 값과 중간 값을 비교합니다.- 만약 찾고자 하는 값이 중간 값과 같다면, 값을 찾은 것이므로 그 위치를 반환합니다.
- 찾고자 하는 값이 중간 값보다 작다면, 검색 범위를 배열의 왼쪽 절반으로 좁힙니다.
- 찾고자 하는 값이 중간 값보다 크다면, 검색 범위를 배열의 오른쪽 절반으로 좁힙니다.
-
반복 또는 재귀 호출:
위의 과정을 반복 또는 재귀 호출하여 값을 찾습니다. -
값을 찾지 못한 경우:
검색 범위가 더 이상 존재하지 않으면 값이 배열에 없다는 것을 의미하므로, 검색 실패를 반환합니다.
코드
function binarySearch(arr, target, left = 0, right = arr.length - 1) {
// base case: 검색 범위가 더 이상 존재하지 않을 때
if (left > right) {
return -1; // 값을 찾지 못한 경우 -1 반환
}
// 중간 인덱스를 계산
const mid = Math.floor((left + right) / 2);
// 중간 값과 타겟 값을 비교
if (arr[mid] === target) {
return mid; // 값을 찾으면 인덱스를 반환
} else if (arr[mid] < target) {
// 중간 값보다 타겟 값이 크면 오른쪽 부분을 검색
return binarySearch(arr, target, mid + 1, right);
} else {
// 중간 값보다 타겟 값이 작으면 왼쪽 부분을 검색
return binarySearch(arr, target, left, mid - 1);
}
}
// 예제 사용
const array = [1, 3, 5, 7, 9, 11, 13, 15];
const target = 7;
const index = binarySearch(array, target);
console.log(index); // 3 (7은 배열의 인덱스 3에 위치)코드 설명
-
Base Case:
if (left > right) { return -1; // 값을 찾지 못한 경우 -1 반환 }- 검색 범위가 더 이상 존재하지 않으면 값이 배열에 없다는 것을 의미하므로 -1을 반환합니다.
-
중간 인덱스 계산:
const mid = Math.floor((left + right) / 2);- 현재 검색 범위의 중간 인덱스를 계산합니다.
-
중간 값과 타겟 값 비교:
if (arr[mid] === target) { return mid; // 값을 찾으면 인덱스를 반환 } else if (arr[mid] < target) { return binarySearch(arr, target, mid + 1, right); // 오른쪽 부분을 검색 } else { return binarySearch(arr, target, left, mid - 1); // 왼쪽 부분을 검색 }- 중간 값과 타겟 값을 비교합니다.
- 중간 값이 타겟 값과 같으면 중간 인덱스를 반환합니다.
- 중간 값이 타겟 값보다 작으면 오른쪽 부분을 검색합니다.
- 중간 값이 타겟 값보다 크면 왼쪽 부분을 검색합니다.
예제 사용
const array = [1, 3, 5, 7, 9, 11, 13, 15];
const target = 7;
const index = binarySearch(array, target);
console.log(index); // 3 (7은 배열의 인덱스 3에 위치)binarySearch함수를 호출하여 배열에서 타겟 값을 검색합니다.- 결과는 타겟 값이 배열의 인덱스 3에 위치해 있다는 것을 반환합니다.
이진 탐색의 장단점
장점
-
빠른 검색 속도:
- 시간 복잡도가 O(log n)으로 매우 효율적입니다. 이는 배열의 크기가 커질수록 큰 차이를 만듭니다.
-
단순한 구현:
- 반복문 또는 재귀 호출을 사용하여 비교적 간단하게 구현할 수 있습니다.
-
메모리 효율성:
- 추가적인 메모리 공간이 거의 필요하지 않습니다.
단점
-
정렬된 배열 필요:
- 이진 탐색을 사용하려면 배열이 미리 정렬되어 있어야 합니다. 정렬되지 않은 배열에서 이진 탐색을 사용하려면 먼저 배열을 정렬해야 합니다. 이는 추가적인 시간과 비용을 요구할 수 있습니다.
-
데이터 구조 제약:
- 배열과 같은 순차 데이터 구조에서는 효율적으로 사용할 수 있지만, 링크드 리스트와 같은 동적 데이터 구조에서는 효율적이지 않습니다. 이는 링크드 리스트에서 중간 요소에 접근하는 데 O(n) 시간이 걸리기 때문입니다.
-
삽입/삭제 비용:
- 정렬된 배열에서 삽입과 삭제 작업은 O(n)의 시간이 소요될 수 있습니다. 이는 배열의 요소들을 이동시켜야 하기 때문입니다.
이진 탐색의 과정 시각화
-
초기 배열:
[1, 3, 5, 7, 9, 11, 13, 15] -
첫 번째 중간 값 선택:
중간 값 = 7, 인덱스 = 3 -
값 비교:
- 찾고자 하는 값이 중간 값(7)과 같으므로, 값을 찾았습니다.
-
결과:
값 7의 인덱스는 3입니다.
이진 탐색(Binary Search)의 장단점
-
장점:
- 빠른 검색 속도: 정렬된 배열에서의 검색 속도는 O(log n)입니다.
- 단순한 구현: 구현이 비교적 간단하며, 효율적입니다.
- 메모리 효율성: 추가적인 메모리 공간이 거의 필요하지 않습니다.
-
단점:
- 정렬된 배열 필요: 이진 탐색을 사용하려면 배열이 정렬되어 있어야 합니다.
- 데이터 구조 제약: 링크드 리스트와 같은 동적 데이터 구조에서는 이진 탐색을 효율적으로 사용할 수 없습니다.
- 삽입/삭제 비용: 정렬된 배열에서 삽입과 삭제 작업은 O(n)의 시간이 소요될 수 있습니다.
요약
- 병합 정렬: 안정적이고 예측 가능한 시간 복잡도를 가지지만, 추가 메모리 공간이 필요합니다.
- 퀵 정렬: 평균적으로 매우 빠르고 메모리 효율적이지만, 최악의 경우 성능이 저하될 수 있으며 기본적으로 안정적이지 않습니다.
- 이진 탐색: 정렬된 배열에서 빠른 검색을 제공하지만, 배열이 정렬되어 있어야 하며 삽입과 삭제 작업의 비용이 큽니다.
