단일 책임 원칙 (SRP)
-
일반적인 해석 → “하나의 컴포넌트는 오로지 한 가지 일만 해야 하고, 그것을 올바르게 수행해야 한다.”
-
실제 정의 → “컴포넌트를 변경하는 이유는 오직 하나뿐이어야 한다.”
- 이것이 좀 더 SRP의 목적에 부합한 설명!
- 책임 → ‘변경할 이유’로 해석!
-
아키텍처에서 SRP의 의미
- 컴포넌트를 변경할 이유가 한 가지이다. → 우리가 다른 이유로 SW를 변경하더라도 이 컴포넌트에 대해서는 전혀 신경 쓸 필요가 없다. 즉 의도치 않은 부수효과를 걱정할 필요 없다! 이것이 SRP의 목적이기도 하다!
-
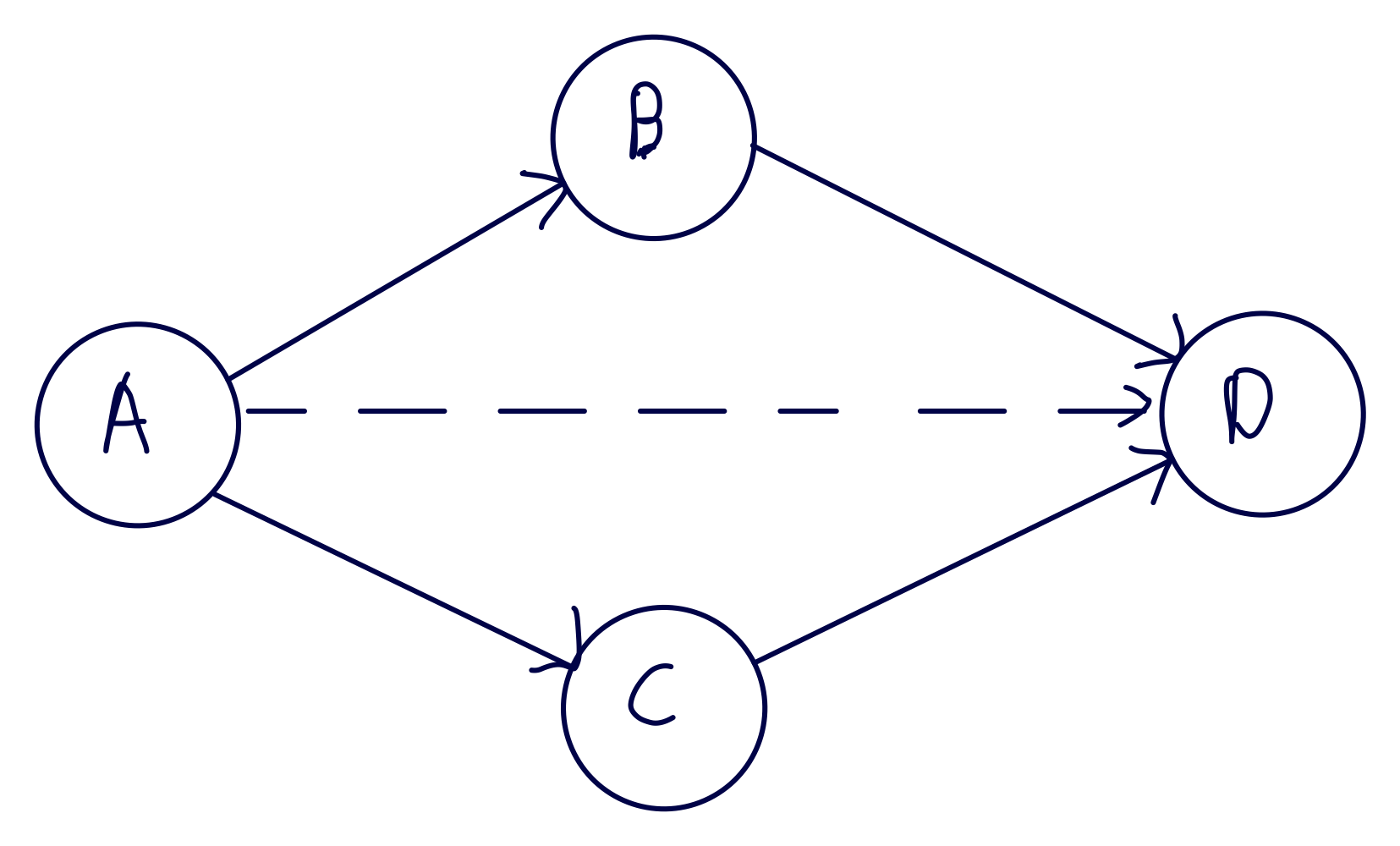
아쉽게도 변경할 이유(책임)라는 것은 컴포넌트 간의 의존성을 통해 너무도 쉽게 전파된다.
-
의존성 각각은 변경하는 이유 하나씩에 해당한다. 점선 화살표 같은 전이 의존성도 마찬가지이다.
-
컴포넌트 A의 경우 모든 컴포넌트에 의존하고 있다. 즉 다른 어떤 컴포넌트가 바뀌던지 영향을 받게 된다.
-
일반적으로 많은 코드는 SRP를 위반한다. 그리고 그로인해, 점점 변경하기가 더 어려워지고 변경 비용도 증가한다.
의존하면 SRP 위반..?
-
의존에 따라 변경 이유가 늘어나게 된다. 즉, 의존 관계가 있을 경우 엄격하게 따지면 SRP 위반이 맞다고 생각한다.
-
하지만 애플리케이션의 사이즈가 조금만 커져도 의존 관계를 이용하지 않고 작성하는 건 불가능하고, 가능하더라도 오히려 더 많은 문제를 야기한다.
-
그렇기에 의존으로 생기는 변경 이유는 제외하고 하나의 책임, 즉 하나의 변경 이유를 갖는 것이 현실적인 SRP의 실현이라고 생각한다. 하지만 그렇다고 하더라도 의존 관계가 지나치게 많은 것은 부적합하며 SRP를 어겼다고 판단해야한다.
부수효과
-
요구사항의 변경 등으로 코드에 한 영역을 변경했다. → 예상하지 못한 곳에서 부수효과가 발생한다.
-
이 경우 클라이언트가 변경을 원하지만 부수효과를 우려해서, 올바른 방향의 변경으로 나아갈 수 없는 악순환이 반복될 수 있다. → SW 신뢰의 문제이기도 하다고 생각한다.
의존성 역전 원칙 (DIP)
-
계층형 아키텍처에서 영속성 계층에 대한 도메인 계층의 의존성으로 인해, 영속성 계층을 변경할 때 마다 도메인 계층에 영향이 가게 된다.
- 하지만 도메인 코드는 애플리케이션에서 가장 중요한 코드(실질적으로 비즈니스적 가치를 전달하는 코드)이다.
- 영속성 코드의 변경으로 도메인 코드가 영향을 받는 것은 옳지 못하고, 이런 상황을 원하지 않는다.
-
그럼 어째?
- DIP가 답을 알려준다.
-
DIP → “코드 상의 어떤 의존성이든 그 방향을 바꿀 수(역전시킬 수) 있다.”
- 단 이때, 의존성의 양쪽 코드를 모두 제어할 수 있을 때만 의존성 역전이 가능하다.
-
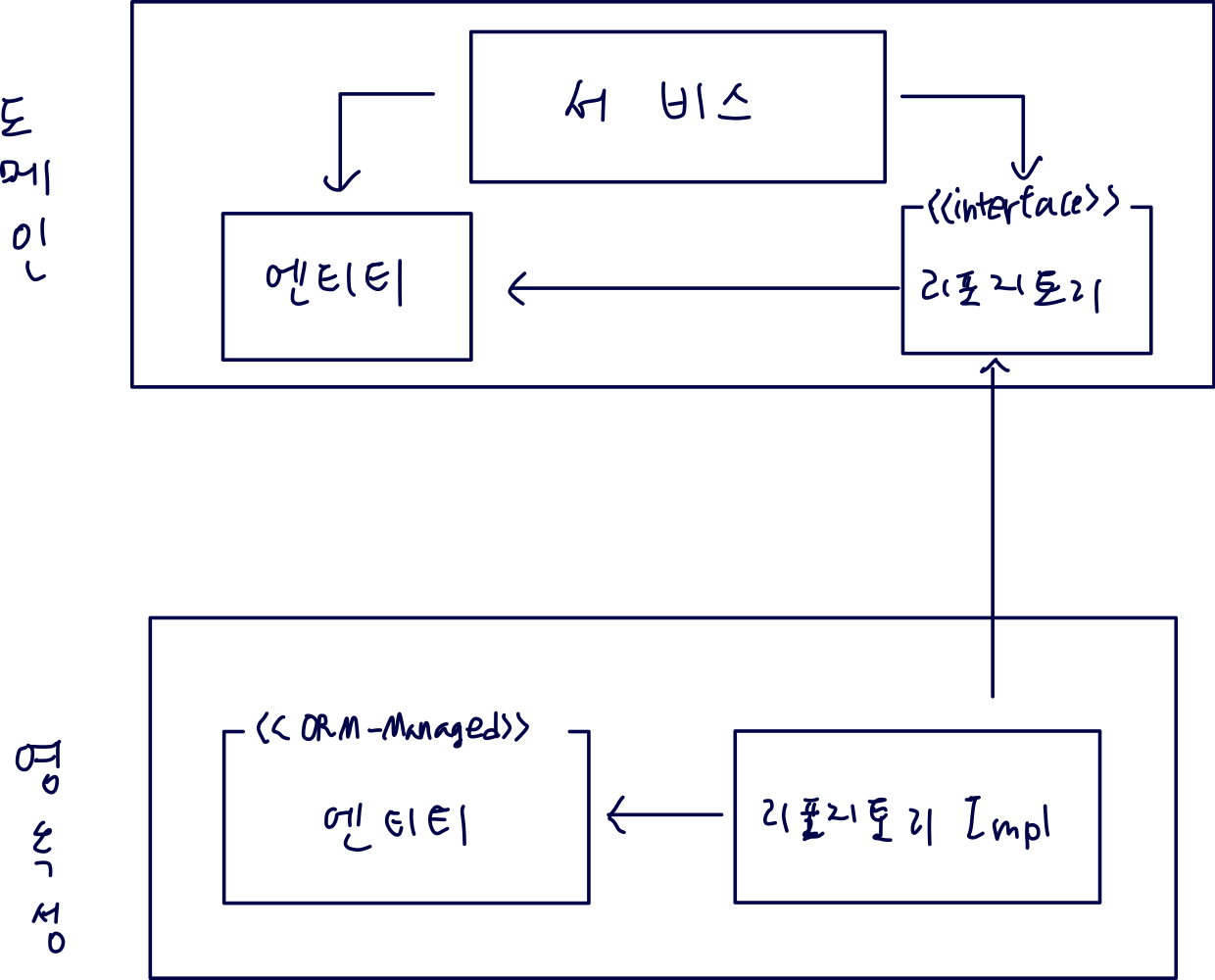
도메인 코드와 영속성 코드 간의 의존성 역전 → 도메인 코드의 변경할 이유의 개수를 줄여보자.
-
엔티티는 도메인 객체를 포현하고 도메인 코드는 이 엔티티들의 상태를 변경하는 일을 중심으로 하기 때문에 엔티티가 도메인 계층에 위치
-
“도메인 → 영속성” 방향의 의존성을 “영속성 → 도메인” 방향으로 역전
클린 아키텍처
-
로버트 C.마틴 → ‘클린 아키텍처’
- “설계가 비즈니스 규칙의 테스트를 용이하게 하고, 비즈니스 규칙은 프레임워크, DB, UI 기술, 그 밖의 외부 애플리케이션이나 인터페이스로부터 독립적일 수 있다.”
- 도메인 코드가 바깥으로 향하는 어떤 의존성도 없어야 함을 의미
- DIP를 이용하여 모든 의존성이 도메인 코드로 향하도록
-
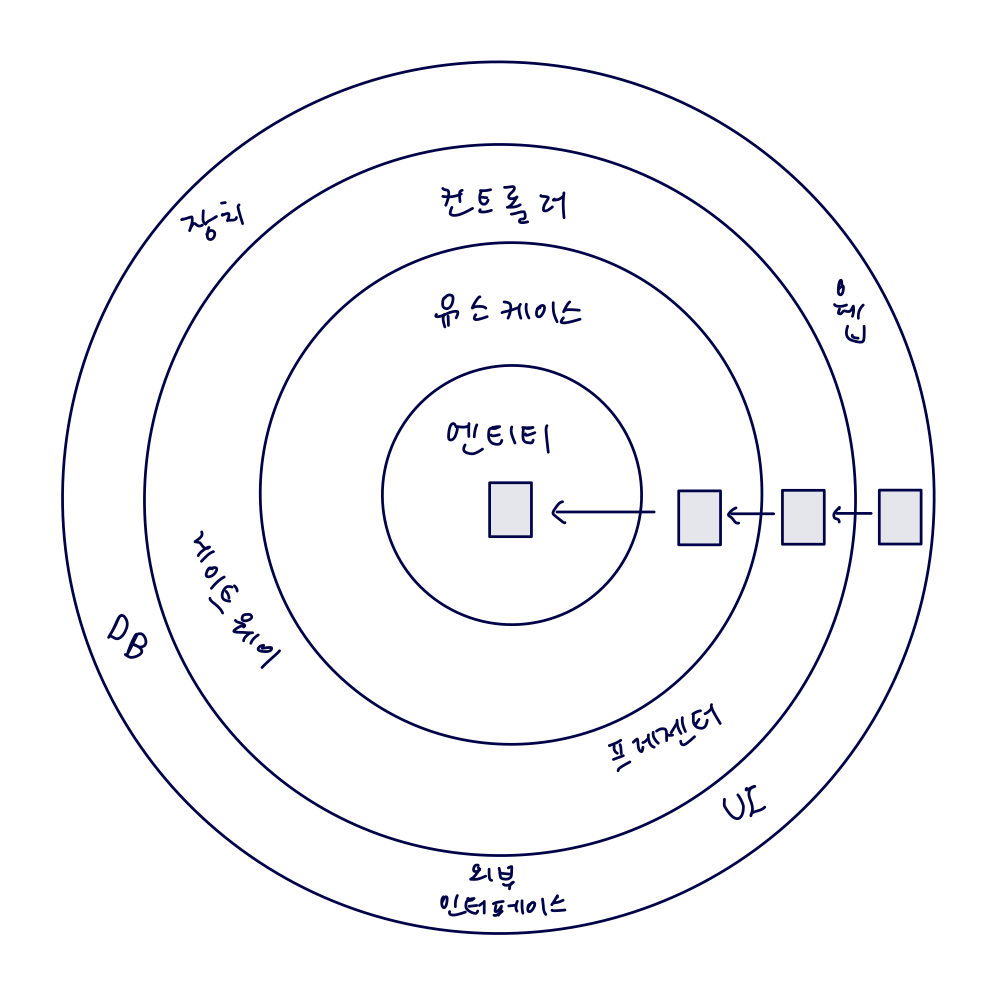
이 아키텍처에서 가장 중요한 규칙은 의존성 규칙
- → 계층 간의 모든 의존성이 안쪽으로 향해야 한다.
-
Core에는 주변 유스케이스에서 접근하는 도메인 엔티티들이 존재
-
유스케이스 = 앞 쪽 설명의 서비스
- SRP를 지키기 위해 조금 더 세분화돼 있다.
- 넓은 서비스 문제를 피하기 위해!
-
도메인 코드에서는 어떤 영속성 프레임워크나 UI 프레임워크가 사용되는지 알 수 없기 없다!
- → 특정 프레임워크에 특화된 코드를 가질 수 없고 비즈니스 규칙에 집중
- 도메인 코드를 자유롭게 모델링
-
다소 추상적이다.
너무 좋아! 하지만 대가가 있다...
-
애플리케이션의 엔티티에 대한 모델을 각 계층에서 유지보수해야한다..!
-
영속성 계층에서 ORM 프레임워크를 사용한다고 가정
- 이때 DB 컬럼과 객체 필드와의 매핑 정보 같은 것을 가지고 있는 엔티티 클래스가 필요하다.
- 도메인 계층은 영속성 계층을 모르기에 두 계층에서 각각 엔티티를 만들어야한다.
- 또한 이 두 계층이 데이터를 주고 받을 때, 두 엔티티를 서로 변환해야 한다. 도메인 계층과 다른 계층들 사이에서도 마찬가지
-
근데 위와 같은 상황은 바람직하다!
- 도메인 코드가 프레임워크에 특화된 문제로 부터 해방된, 결합이 제거된 상태!
- Java Persistence API에서는 ORM이 관리하는 엔티티에 인자가 없는 기본 생성자를 추가하도록 강제한다. 이것이 바로 도메인 모델에서는 포함해서 안되고, 굳이 포함할 필요도 없는 프레임워크에 특화된 결합의 예이다.
Java Persistence API에서는 ORM이 관리하는 엔티티에 인자가 없는 기본 생성자를 추가하도록 강제 → Why?
-
동적으로 객체 생성 시 Reflection API를 활용하기 때문이다.
-
Reflection API → 구체적인 클래스 타입을 알지 못해도 ****그 클래스의 정보(메서드, 타입, 변수 등등)에 접근할 수 있게 해주는 자바 API
- 컴파일 시간이 아니라 실행 시간에 동적으로 특정 클래스의 정보를 객체화를 통해 분석 및 추출해낼 수 있는 프로그래밍 기법
-
대부분 프레임워크나 라이브러리 같은 사용하는 사람이 어떤 클래스를 만들지 모르는 경우 리플렉션을 통해 동적으로 이 문제를 해결하기 위해 많이 사용한다.
-
Reflection API로 가져올 수 없는 정보 중 하나가 생성자의 인자 정보!
- 그래서 기본 생성자가 반드시 있어야 객체를 생성할 수 있는 것이다.
- 기본 생성자로 객체를 생성만 하면 필드 값 등은 Reflection API로 넣어줄 수 있다.
-
Ref
헥사고날 아키텍처
-
클린 아키텍처의 원칙들을 조금 더 구체적으로 만들어준다!
-
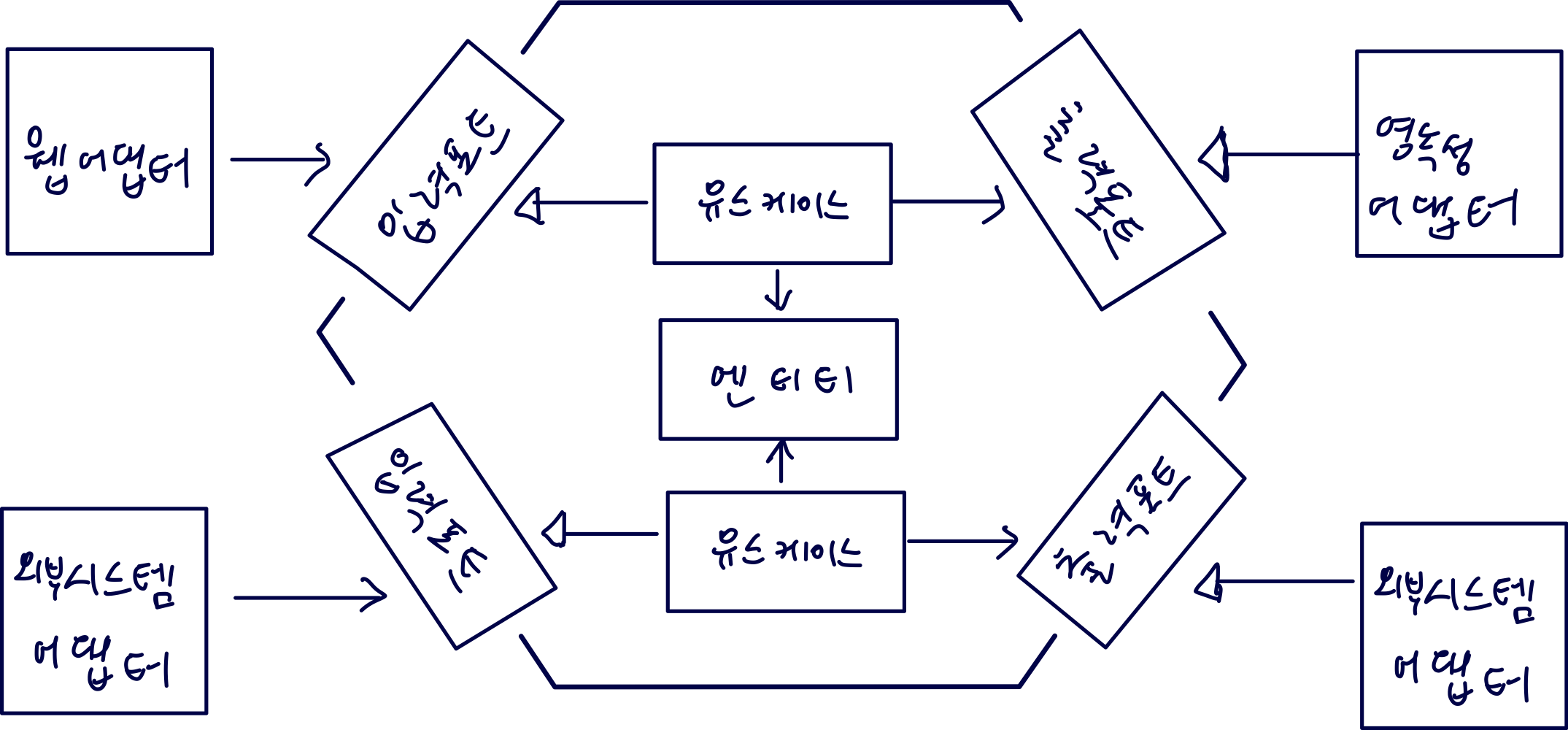
애플리케이션 코어가 각 어댑터와 상호작용하기 위해 특정 포트를 제공하기 때문에 “포트와 어댑터 아키텍처”이라고도 한다.
-
육각형 안에는 도메인 엔티티와 이와 상호작용하는 유스케이스 존재
-
육각형에서 외부로 향하는 의존성 존재 X
- → 클린 아키텍처에서 제시한 의존성 규칙이 그대로 적용
- 모든 의존성은 코어를 향한다.
-
왼쪽에 있는 어댑터
- 애플리케이션 코어를 호출하는 애플리케이션을 주도하는 어댑터
-
오른쪽에 있는 어댑터
- 애플리케이션 코어에 의해 호출되는 애플리케이션에 의해 주도되는 어댑터
-
애플리케이션 코어 - 어댑터 통신을 위해 애플리케이션 코어가 각각의 포트를 제공해야한다.
- 주도하는 어댑터(왼쪽)에게는 그러한 포트가 코어에 있는 유스케이스 클래스들에 의해 구현되는 인터페이스가 ****된다.
- 주도되는 어댑터(오른쪽)에게는 그러한 포트가 어댑터에 의해 구현되고 코어에 의해 호출되는 인터페이스가 된다.
-
헥사고날 아키텍처를 계층으로 구성해보면...
- 가장 바깥쪽 → 애플리케이션과 다른 시스템 간의 번역을 담당하는 어댑터로 구성
- 그 다음 → 포트와 유스케이스 구현체를 결합해서 애플리케이션 계층을 구성
- 이 2가지가 애플리케이션의 인터페이스를 정의하기 때문
- 마지막 계층(가장 안쪽) → 도메인 엔티티가 위치
유지보수 가능한 SW를 만드는데 어떻게 도움이 될까?
-
“의존성을 역전시켜 도메인 코드가 다른 바깥쪽 코드에 의존하지 않게 함으로써 영속성과 UI에 특화된 모든 문제로부터 도메인 로직의 결합을 제거하고 코드를 변경할 이유의 수를 줄일 수 있다.”
- → 변경할 이유가 적을수록 유지보수성은 더 좋아진다.
-
도메인 코드를 비즈니스 문제에 맞게 자유롭게 모델링 할 수 있다.
-
영속성과 UI코드도 각각의 문제에 맞게 자유롭게 모델링 할 수 있다.
