
📖 검색 알고리즘 (Searching Algorithm)
배열
["부대찌개", "샤브샤브", "마라탕", "윤영서", "고양이", "강아지", "햄스터"]가 있다고 하자. 이때 우리가 "윤영서"를 찾으려면 어떻게 해야할까?
이를 찾는 것에는 여러 방법이 있을 것이다. 이러한 문제를 해결하는 방법을 '검색 알고리즘'이라 하는데, 오늘은 이 검색 알고리즘에 대해 알아보자.
📖 선형 탐색 (Linear Search)
배열
["부대찌개", "샤브샤브", "마라탕", "윤영서", "고양이", "강아지", "햄스터"]에서 "윤영서"를 찾는 가장 단순한 방법은 배열의 맨 앞 혹은 맨 뒤부터 모든 요소를 보면서 "윤영서"가 맞는지 확인하는 것일 것이다.
선형 탐색은 맨 앞부터 시작해서 맨 뒤로 이동하면서(혹은 반대로) 한번에 하나의 요소를 확인하면서 모든 항목을 확인한다.
✏️ Linear Search Exercise
Write a function called linearSearch which accepts an array and a value, and returns the index at which the value exists. If the value does not exist in the array, return -1.
Don't use indexOf to implement this function!
Examples:
linearSearch([10, 15, 20, 25, 30], 15) // 1
linearSearch([9, 8, 7, 6, 5, 4, 3, 2, 1, 0], 4) // 5
linearSearch([100], 100) // 0
linearSearch([1,2,3,4,5], 6) // -1
linearSearch([9, 8, 7, 6, 5, 4, 3, 2, 1, 0], 10) // -1
linearSearch([100], 200) // -1
function linearSearch(arr, num){
for (let i = 0; i < arr.length; i++) {
if (arr[i] === num){
return i;
}
}
return -1;
} 💗 Binary Search Solution
function linearSearch(arr, val){
for(var i = 0; i < arr.length; i++){
if(arr[i] === val) return i;
}
return -1;
}위 알고리즘은 시간 복잡도 O(N)을 따른다. 그러므로 배열이 길어질수록, 더 많은 검색을 요한다.
그렇다면 선형 탐색에서, 최고의 경우는 어떻게 될까? 우리가 검색을 하자마자 찾는 것, 즉 O(1)이 최선일 것이다. 최악의 경우는 O(N)이다. 이는 맨마지막에 찾는 경우가 될 것이다.
그러므로 평균적인 시간 복잡도를 따져, 선형 탐색의 시간 복잡도는 O(N)이라 하고 이는 앞서 '빅 오 표기법'에서 말했듯이 '경향'을 고려한 값이다.
🗨️ 선형 탐색 알고리즘 함수
아래 함수들은 선형 탐색 알고리즘을 가진다.
- Array.findIndex()
- Array.indexOf()
- Array.includes()
📖 이진 탐색 (Binary Search)
이진 탐색은 선형 탐색보다 훨씬 빠르다. 항목을 하나하나씩 제껴나가는 선형 탐색과 달리 이진 탐색은 확인을 할 때마다 절반을 제낄 수가 있다. 주의할 점은, 이진 검색은 분류된 배열을 대상으로만 작동하므로 데이터가 분류되어 있어야 한다는 것이다.
["부대찌개", "샤브샤브", "마라탕", "윤영서", "고양이", "강아지", "햄스터"]이렇게 된 배열이 있다고 한다면 여기서 윤영서를 찾기 위해 절반을 제거하고 또 절반을 제거하는 행위는 의미가 없다. 이진 탐색은 명확한 '기준'이 필요하다.
["강아지", "고양이", "마라탕", "부대찌개", "샤브샤브", "윤영서", "햄스터"]이렇게 가나다순으로 정렬이 되어있을때, "윤영서" 찾기 위해 우리는 중간점을 선택할 수 있다.
"부대찌개" 를 보고 우리는, "윤영서"는 ㅇ으로 시작하는 글자이므로 '뒤에 배치되어 있을 것'이라 예상할 수 있다. 그렇다면 앞의 배열을 버린다.
["샤브샤브", "윤영서", "햄스터"]중간점을 찾으면 "윤영서"가 나온다. 이렇게 윤영서를 선형 탐색보다는 빠르게 찾을 수 있다.
기본적인 개념은 분할 정복(Divide and Conquer)이다.
이는 배열을 두 부분으로 나눈뒤, 중간점을 선택하고 우리가 찾는 값이 중간점을 기준으로 어느쪽에 있는지를 확인한다.
✏️ Binary Search Exercise
Write a function called binarySearch which accepts a sorted array and a value and returns the index at which the value exists. Otherwise, return -1.
This algorithm should be more efficient than linearSearch - you can read how to implement it here - https://www.khanacademy.org/computing/computer-science/algorithms/binary-search/a/binary-search and here - https://www.topcoder.com/community/data-science/data-science-tutorials/binary-search/
Examples:
binarySearch([1,2,3,4,5],2) // 1
binarySearch([1,2,3,4,5],3) // 2
binarySearch([1,2,3,4,5],5) // 4
binarySearch([1,2,3,4,5],6) // -1
binarySearch([
5, 6, 10, 13, 14, 18, 30, 34, 35, 37,
40, 44, 64, 79, 84, 86, 95, 96, 98, 99
], 10) // 2
binarySearch([
5, 6, 10, 13, 14, 18, 30, 34, 35, 37,
40, 44, 64, 79, 84, 86, 95, 96, 98, 99
], 95) // 16
binarySearch([
5, 6, 10, 13, 14, 18, 30, 34, 35, 37,
40, 44, 64, 79, 84, 86, 95, 96, 98, 99
], 100) // -1
function binarySearch(arr, num){
let left = 0;
let right = arr.length-1;
if (arr[left] === num) {
return left;
}
if (arr[right] === num) {
return right;
}
while(left<=right){
let idx = Math.floor((left+right) / 2);
if (arr[idx] === num) {
return idx;
}else if(arr[idx] < num){
left = idx+1;
}else if(arr[idx] > num){
right = idx-1;
}
}
return -1;
}💗 Binary Search Solution
function binarySearch(arr, elem) {
var start = 0;
var end = arr.length - 1;
var middle = Math.floor((start + end) / 2);
while(arr[middle] !== elem && start <= end) { //내 코드에서는 arr[middle] === elem 조건일때를 if-else에 포함해줬다.
if(elem < arr[middle]) end = middle - 1;
else start = middle + 1;
middle = Math.floor((start + end) / 2);
}
return arr[middle] === elem ? middle : -1;
}
이진 탐색에서, 최선의 경우는 어떻게 될까? 당연히 O(1)이 최선일 것이다. 최악의 경우는 O(logN)이 된다.
그러므로 평균적인 시간 복잡도를 따져, 이진 탐색의 시간 복잡도는 O(logN)이다.
O(logN)를 가지는 시간 복잡도는 어떻게 구할 수 있을까?
[2,4,5,9,11,14,15,19]
이 있다고 하자. 이때 우리가 찾을 수는 13이다. 우리는 중간점인 9를 찾는다. 9는 13보다 작으므로, 왼쪽 인덱스를 중간점의 값에 ++하고 중간점을 옮긴다.
[11,14,15,19]
중간점은 14이다. 13은 14보다 작다. 오른쪽 인덱스를 중간점의 값에 --하고 중간점을 옮긴다.
[11]
중간점은 11이다. 13은 11과 같지 않다.
원소는 8개였고, 우리는 원소 13를 찾는데 3스텝이 걸렸다.
절반씩 줄어들게 되므로 최악의 경우라면 우리는 계속 절반을 줄이게 되므로 logN의 단계가 필요할 것이다.
그러므로 이진 탐색의 시간 복잡도는 O(logN)이 된다.
📖 나이브 문자열 탐색 (Naive String Search)
문자열내의 부분 문자열이 몇 번 존재하는지 탐색하는 알고리즘에 대해 생각해보자.
가장 간단한 방식은 두 문자열을 나란히 놓고 한 번에 하나의 문자를 비교하는 것이다.
대략적인 알고리즘은 아래 사진과 같다.
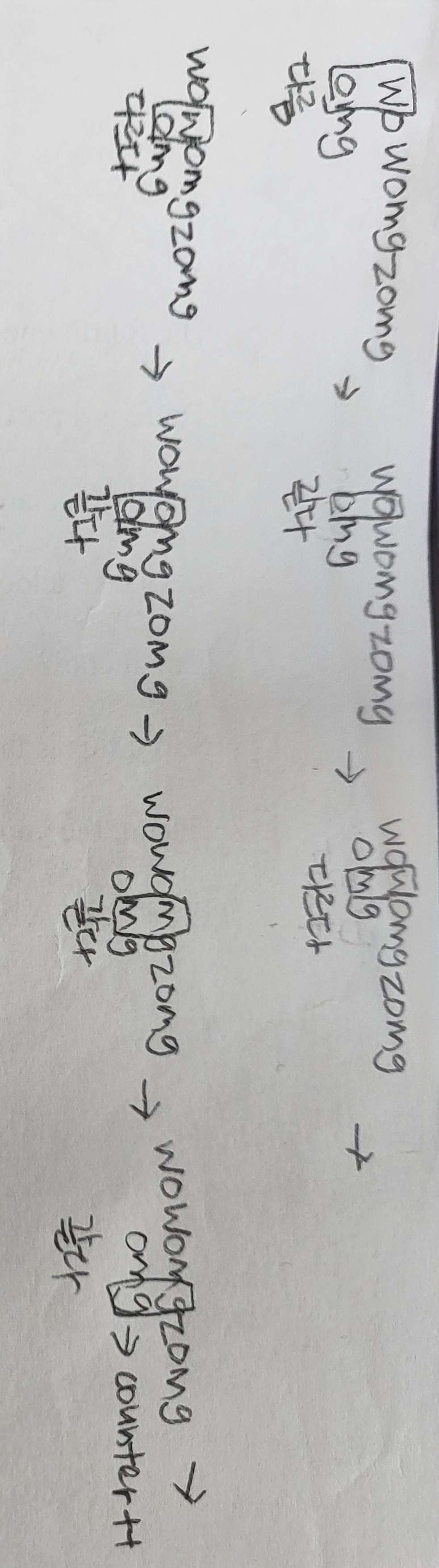
✏️ Naive String Search Solution
function naiveSearch(long, short){
var count = 0;
for(var i = 0; i < long.length; i++){
for(var j = 0; j < short.length; j++){
if(short[j] !== long[i+j]) break; //부분 문자열 비교
if(j === short.length - 1) count++; //for문 다 돌리고나서 온전히 다 돌아갔다 하면 count올려준다.
}
}
return count;
}
