Retriever 장단점
Similarity Search
정의
유사도 측정
벡터 공간에서의 유사도 측정
벡터 공간에서 유사도 측정은 머신러닝에서 중요한 역할을 합니다. 이러한 측정 방법은 객체, 데이터 포인트 또는 벡터 간의 유사성을 수학적으로 정량화합니다. 임베딩 공간에서 두 벡터가 얼마나 가까운지 계산하는 데 사용할 수 있는 여러 유사도 측정 방법이 있습니다.
내적(Dot Product)
내적은 흔히 사용되는 유사도 측정 방법입니다. 내적은 벡터의 방향 유사성과 크기를 모두 측정합니다. 벡터의 방향과 크기가 모두 중요한 정보를 담고 있을 때 특히 유용합니다.
내적(a,b) = Σ(aᵢ × bᵢ) = a₁b₁ + a₂b₂ + ... + aₙbₙ기하학적으로는 다음과 같이 표현할 수 있습니다:
내적(a,b) = |a| × |b| × cos(θ)여기서 |a|와 |b|는 벡터의 크기(길이)이고, θ는 두 벡터 사이의 각도입니다.
장점
계산이 간단하고 효율적입니다
벡터의 방향과 크기를 모두 고려합니다
양수, 음수, 0 등 다양한 값을 통해 유사성의 정도를 나타낼 수 있습니다
단점
벡터의 크기에 민감하여 크기가 큰 벡터가 결과에 더 많은 영향을 미칩니다
벡터의 길이가 다를 경우 결과가 왜곡될 수 있습니다
값의 범위가 무한대로 열려있어 해석이 어려울 수 있습니다
코사인 유사도(Cosine Similarity)
코사인 유사도는 벡터의 크기(길이)에 관계없이 벡터 간의 각도만 고려합니다. 두 벡터의 코사인 유사도를 계산하려면 두 벡터의 내적을 각 벡터 길이의 곱으로 나누면 됩니다. 이는 벡터 크기를 1로 조정합니다. 따라서 코사인 유사도는 벡터 크기에 영향을 받지 않습니다.
코사인_유사도(a,b) = 내적(a,b) / (|a| × |b|)값이 1이면 두 벡터가 동일함을 나타냅니다. (각도 = 0˚)
값이 0이면 두 벡터가 완전히 직교함을 나타냅니다. (각도 = 90˚)
값이 -1이면 두 벡터가 정반대임을 나타냅니다. (각도 = 180˚)
장점
벡터의 크기에 영향을 받지 않아 순수하게 방향 유사성만 측정합니다
-1에서 1 사이의 값으로 정규화되어 해석이 용이합니다
고차원 공간에서 특히 유용합니다
텍스트 분석, 추천 시스템 등 다양한 분야에서 활용됩니다
단점
벡터의 크기(량)가 중요한 정보를 담고 있는 경우에는 적합하지 않을 수 있습니다
계산 과정에서 정규화 단계가 필요하여 내적보다 연산이 더 많습니다
MMR (Maximal Marginal Relevance)
검색 결과나 키워드 추출 시 결과의 다양성과 관련성을 동시에 고려하는 알고리즘입니다.
MMR은 이미 선택된 항목과의 유사성(중복성)을 줄이면서도 쿼리와의 관련성을 유지하는 방식으로 항목을 재순위화합니다.
주로 문서 요약이나 키워드 추출에서 활용됩니다.
예시
추출된 키워드: 좋은 제품, 훌륭한 제품, 멋진 제품, 뛰어난 제품, 쉬운 설치, 좋은 UI, 가벼운 무게
상위에 있는 여러 키워드가 비슷한 의미를 가지고 있어, 표시할 수 있는 공간이 제한적일 경우(예: 5개만 표시 가능) 정보의 다양성이 떨어지게 됩니다.
해결 방법
1. 코사인 유사도를 이용한 중복 제거
이 접근법은 단어 임베딩을 사용하여 키워드 간 코사인 유사도를 계산하고, 특정 임계값(예: 0.9) 이상의 유사도를 가진 키워드들을 그룹화하여 가장 높은 점수를 가진 하나만 선택하는 방식입니다.
단점: 임계값 설정이 어려우며, 임계값이 너무 낮으면 서로 다른 의미의 키워드까지 그룹화될 수 있고, 너무 높으면 유사한 키워드들이 여전히 결과에 포함될 수 있습니다.
2. MMR을 이용한 키워드 재순위화
MMR은 아래 공식을 통해 항목을 선택합니다:
MMR = λ * Sim1(Doc, Query) - (1-λ) * max(Sim2(Doc, 이미 선택된 문서들))λ는 0과 1 사이의 상수, 1에 가까울 수록 쿼리와의 관련성이 중요시되고, 0에 가까울 수록 다양성이 중시됨
Sim1은 문서와 쿼리 간의 유사도
Sim2는 현재 고려 중인 문서와 이미 선택된 문서들 간의 유사도
MMR의 장단점
장점
다양성 확보: 유사한 키워드가 모두 상위 순위를 차지하는 것을 방지합니다
관련성 유지: 쿼리 관련성을 여전히 고려하므로 중요한 정보는 유지됩니다
유연한 조정: λ 매개변수를 통해 다양성과 관련성 간의 균형을 조절할 수 있습니다
단점
계산 복잡성: 항목이 많을 경우 계산 비용이 증가할 수 있습니다
λ 매개변수 튜닝: 최적의 λ 값을 찾기 위한 실험이 필요합니다
적용 도메인 고려: 모든 도메인에서 동일한 성능을 보장하지 않습니다
유사도 측정 의존성: 사용된 유사도 측정 방식(코사인 등)의 한계에 영향을 받습니다
MMR은 특히 정보 검색, 문서 요약, 키워드 추출 등에서 다양성과 관련성의 균형을 맞추는 효과적인 방법으로, 제한된 공간에서 가능한 많은 정보를 전달하고자 할 때 유용합니다.
Document Compression Retriever
RAG 시스템에서는 데이터를 시스템에 저장할 때 사용자가 어떤 질문을 할지 미리 알 수 없습니다. 따라서 사용자의 질문과 관련된 정보가 많은 무관한 텍스트가 포함된 문서에 묻혀 있을 수 있습니다. 이러한 전체 문서를 LLM에 전달하면 비용이 증가하고 응답 품질이 저하됩니다.
컨텍스트 압축은 검색된 문서를 있는 그대로 반환하는 대신, 주어진 질의의 맥락에 맞게 압축하여 관련 정보만 반환하는 방식입니다. 여기서 "압축"은 개별 문서 내용을 압축하거나 문서 전체를 필터링하는 것을 모두 포함합니다.
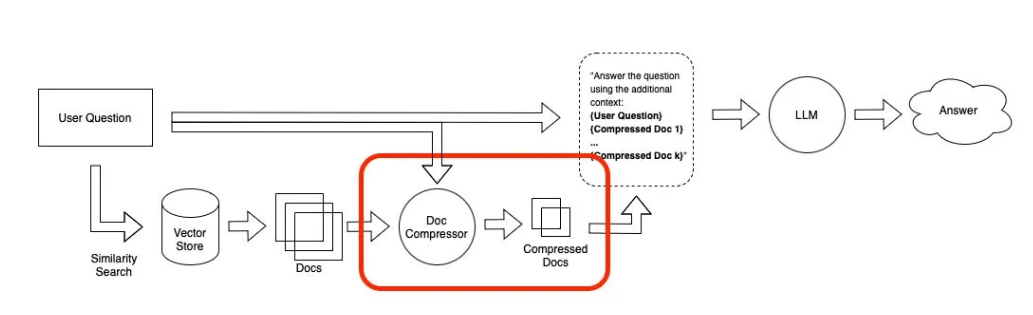
장점
비용 효율성: LLM 호출 시 처리해야 할 텍스트 양이 줄어 비용이 절감됩니다.
응답 품질 향상: 관련 정보만 LLM에 전달되어 더 정확하고 집중된 응답을 생성합니다.
토큰 한계 극복: 대형 문서나 많은 문서를 처리할 때 LLM의 토큰 제한을 초과하는 문제를 해결합니다.
처리 속도 향상: 적은 양의 텍스트를 처리하므로 LLM 응답 시간이 단축됩니다.
단점
추가 계산 비용: 압축 과정에서 추가적인 계산 단계가 필요합니다.
정보 손실 위험: 압축 과정에서 중요한 정보가 누락될 가능성이 있습니다.
구현 복잡성: 효과적인 압축 알고리즘을 설계하고 구현하는 것이 복잡할 수 있습니다.
지연 시간 추가: 압축 단계가 추가되어 전체 처리 시간이 길어질 수 있습니다.
도메인 종속성: 특정 도메인이나 데이터 유형에 맞게 최적화된 압축 방식이 다른 분야에서는 효과적이지 않을 수 있습니다.
Self-Query Retriever
Self-Query Retriever는 사용자 질의를 자동으로 분석하여 구조화된 검색 쿼리와 필터를 생성하는 고급 검색 시스템입니다. 이 방식은 대규모 언어 모델(LLM)을 활용하여 사용자의 자연어 질문을 데이터베이스 쿼리로 변환하는 프로세스를 자동화합니다.
Self-Query Retriever는 사용자의 자연어 질문을 두 가지 주요 구성 요소로 분해합니다:
검색 쿼리: 벡터 데이터베이스에서 의미적 검색에 사용될 핵심 질문
필터 조건: 메타데이터를 기반으로 검색 결과를 필터링하는 조건
이 방식은 벡터 검색의 의미적 유사성과 메타데이터 필터링의 정확성을 결합하여 더 정교한 검색 결과를 제공합니다.
작동 원리
쿼리 분석: LLM이 사용자의 자연어 질문을 분석합니다
쿼리 변환: 분석된 내용을 바탕으로 검색 쿼리와 메타데이터 필터로 변환합니다
검색 실행: 생성된 쿼리로 벡터 검색을 수행하고, 메타데이터 필터를 적용합니다
결과 반환: 관련성이 높고 필터 조건에 맞는 결과를 사용자에게 제공합니다
예시)
# 문서와 메타데이터
documents = [
Document(
page_content="인공지능 안전성을 위한 연구 방법론",
metadata={"year": 2023, "author": "김연구", "topic": "AI Safety", "document_type": "research_paper"}
),
Document(
page_content="딥러닝 모델의 설명가능성에 관한 연구",
metadata={"year": 2022, "author": "이학자", "topic": "Explainable AI", "document_type": "research_paper"}
),
Document(
page_content="강화학습을 활용한 자율주행 알고리즘",
metadata={"year": 2023, "author": "박기술", "topic": "Autonomous Driving", "document_type": "technical_report"}
),
Document(
page_content="인공지능 윤리와 법적 책임",
metadata={"year": 2021, "author": "최법률", "topic": "AI Ethics", "document_type": "article"}
)
]
# 메타데이터 필드 정의
metadata_field_info = [
{"name": "year", "description": "문서가 출판된 연도", "type": "integer"},
{"name": "author", "description": "문서의 저자", "type": "string"},
{"name": "topic", "description": "문서의 주제", "type": "string"},
{"name": "document_type", "description": "문서의 유형(research_paper, technical_report, article 등)", "type": "string"}
]사용자가 "2023년에 발표된 인공지능 안전성에 관한 연구 논문을 찾아줘"라고 질문했을 때:
추출된 검색 쿼리: "인공지능 안전성 연구"
생성된 필터: year=2023, document_type="research_paper"
이렇게 변환된 쿼리와 필터를 통해 벡터 데이터베이스에서 의미적으로 관련 있는 문서를 찾되, 2023년에 발표된 연구 논문으로 결과를 제한합니다.
Self-Query Retriever의 장단점
장점
정확한 검색 결과: 의미적 검색과 메타데이터 필터링을 결합하여 정확도를 높입니다
자연어 처리: 사용자가 복잡한 검색 구문을 알 필요 없이 자연어로 질문할 수 있습니다
유연한 검색: 다양한 유형의 메타데이터를 활용한 복잡한 검색 조건을 지원합니다
효율적인 검색: 필터링을 통해 검색 범위를 좁혀 더 빠른 결과를 제공합니다
개인화 가능: 사용자의 컨텍스트나 선호도에 맞게 검색 방식을 조정할 수 있습니다
단점
LLM 의존성: 고품질의 LLM이 필요하며, 모델의 성능에 크게 의존합니다
메타데이터 품질: 정확한 메타데이터가 없으면 필터링 효과가 제한적입니다
복잡한 설정: 초기 설정 및 메타데이터 스키마 정의가 복잡할 수 있습니다
오해석 가능성: LLM이 사용자 의도를 잘못 해석하여 부적절한 필터를 생성할 수 있습니다
계산 자원: 쿼리 분석과 변환에 추가적인 계산 자원이 필요합니다
source
https://medium.com/advanced-deep-learning/understanding-vector-similarity-b9c10f7506de
https://medium.com/tech-that-works/maximal-marginal-relevance-to-rerank-results-in-unsupervised-keyphrase-extraction-22d95015c7c5
https://medium.com/@SrGrace_/contextual-compression-langchain-llamaindex-7675c8d1f9eb
https://python.langchain.com/docs/how_to/self_query/
https://rudaks.tistory.com/entry/langchain-%EC%85%80%ED%94%84-%EC%BF%BC%EB%A6%AC-%EA%B2%80%EC%83%89%EA%B8%B0-Self-querying
