본 글은
docker run명령어로 컨테이너를 띄워본 경험은 있지만, 쿠버네티스는 처음 접하는 독자를 대상으로 합니다. 복잡한 코드는 다루지 않으며, 쿠버네티스가 제어하는 기반 기술을 추상적으로 살펴봅니다. 본 내용은 시리즈로 연재될 예정이며, 컨테이너부터 쿠버네티스까지 차근차근 이야기합니다.
1부. 컨테이너는 존재하지 않는다
쿠버네티스, 그리고 컨테이너
쿠버네티스를 한 문장으로 정의하면 '컨테이너 오케스트레이션 도구'입니다. 지휘자가 오케스트라를 지휘하듯, 수많은 컨테이너를 관리한다는 뜻이죠.
그런데 '컨테이너'란 정확히 무엇일까요?
도커를 사용해 봤다면 컨테이너라는 개념은 익숙할 것입니다.
docker run 을 하면 독립된 환경인 컨테이너가 띄워진다고 많이들 이야기 합니다. 하지만 기술적인 관점에서 엄밀하게 말하면, 리눅스 운영체제에 '컨테이너'라는 기술은 존재하지 않습니다.
컨테이너의 실체: 격리된 프로세스
크롬이 카카오톡의 메모리를 훔쳐볼 수 없듯, 기본적으로 프로세스 간 메모리는 철저히 분리되어 있습니다.
하지만 파일시스템과 네트워크는 사정이 다릅니다. 카카오톡 파일 전송 창을 열면 내 컴퓨터의 모든 폴더가 다 들여다보이고, 모든 프로그램이 하나의 IP 주소를 공유하기 때문에 서로 다른 포트를 써야만 충돌 없이 통신할 수 있습니다.
컨테이너는 여기에 Namespace와 Cgroup을 얹습니다. 파일시스템과 네트워크까지 격리하고, 자원 사용량도 제한하죠. 이를 통해 내부는 격리된 환경이지만, 호스트 입장에서 그 실체는 크롬이나 카카오톡과 다를 바 없는 프로세스 하나일 뿐입니다.
첫 번째 메커니즘: Namespace
리눅스 Namespace는 프로세스에게 "시스템의 독립된 뷰"를 제공합니다. 쉽게 말해 프로세스를 속이는 기술입니다.
- mnt: 파일시스템을 분리합니다. 프로세스는 자신에게 할당된 루트 디렉토리(
/)만 볼 수 있습니다. - pid: 프로세스 ID를 분리합니다. 컨테이너 안에서 실행된 프로세스는 자신이 PID 1번이라고 인식하지만, 호스트에서 보면 15,342번 같은 일반 프로세스일 뿐입니다.
- net: 네트워크를 분리합니다. 자신만의 IP 주소, 포트, 라우팅 테이블을 갖습니다.
- uts: 호스트명을 분리합니다. 컨테이너마다 다른 hostname을 가질 수 있습니다.
- ipc: 프로세스 간 통신을 분리합니다. 공유 메모리나 파이프 같은 자원을 격리합니다.
- user: 사용자 권한을 분리합니다. 호스트에서는 일반 사용자여도 컨테이너 안에서는 root로 보이게 할 수 있습니다.
더 깊이 공부하고 싶다면?
격리라고 해서 모든 Namespace를 분리해야 하는 건 아닙니다. 필요하다면 특정 Namespace만 공유할 수도 있습니다.
실제로 쿠버네티스의 파드는 여러 컨테이너가 Network Namespace를 공유하는 구조입니다. 그래서 같은 파드 속 컨테이너들은localhost로 통신이 가능한 것이죠.
- 검색 키워드:
Linux Namespace Sharing,docker --net container,pause container
두 번째 메커니즘: Cgroup
격리만 한다고 끝이 아닙니다. 어떤 프로세스가 CPU를 혼자 다 써버리면 안 되니까요.
Cgroup은 프로세스가 소비할 수 있는 리소스의 양을 제한합니다. CPU 코어 수, 메모리 상한, 네트워크 대역폭 등을 지정할 수 있고, 메모리 제한을 넘기면 강제 종료되기도 합니다.
이 제한은 계층 구조로 만들 수 있습니다. 상위 그룹에 10GB를 할당하고, 그 안에서 하위 프로세스들이 나눠 쓰게 할 수 있죠.
결국 컨테이너란 Namespace로 환경이 격리되고, Cgroup으로 자원이 제한된 리눅스 프로세스입니다.
깊이 공부하고 싶다면?
Cgroup은 단순히 제한만 거는 게 아니라, 자원 사용량을 측정하는 역할도 합니다.docker stats명령어가 작동하는 이유이기도 합니다.
- 검색 키워드:
Cgroup v1 vs v2,Systemd Cgroup driver
Deep Dive: docker run의 내부
컨테이너의 핵심 원리를 알았으니 이제 docker run 명령어가 하는 일을 자세히 들여다봅시다.
docker run -d nginx를 실행하면 내부에서는 여러 컴포넌트가 역할을 나눠 순차적으로 동작합니다.
1. Docker CLI: 요청의 시작
입력한 명령어는 REST API 형태로 변환되어 도커 데몬에게 전송됩니다.
2. dockerd: API 게이트웨이
요청을 수신한 도커 데몬은 전체 흐름을 담당하지만, 직접 컨테이너를 생성하지는 않습니다. containerd에게 작업을 위임합니다.
3. containerd: 라이프사이클 관리자
컨테이너의 생애 주기를 관리하는 핵심 계층입니다.
- 이미지 확보: 로컬에 이미지가 없으면 레지스트리에서 다운로드합니다.
- 스냅샷 준비: 이미지를 압축 해제하고 실행 가능한 상태로 만듭니다.
- 실행 위임: 준비가 끝나면 저수준 런타임인 runc를 호출합니다.
4. runc: 커널 인터페이스
runc는 리눅스 커널의 기능을 직접 제어하는 실행기입니다. OCI 표준을 따르며, 아주 짧게 실행되고 사라집니다.
- Namespace 생성: 커널에게 요청해 격리된 공간을 만듭니다.
- Cgroup 설정: CPU와 메모리 제한을 설정합니다.
- 프로세스 실행: 격리된 공간 안에서 nginx 프로세스를 실행합니다.
- 종료: 프로세스 실행이 완료되면 runc는 즉시 종료됩니다.
5. containerd-shim: 프로세스 관리
runc가 종료된 후에도 컨테이너는 계속 실행되어야 합니다. shim이 부모 프로세스 역할을 맡아 컨테이너를 관리합니다.
- stdout/stderr 같은 입출력을 관리합니다.
- 컨테이너가 종료되면 종료 코드를 상위 계층에 보고합니다.
Gemini를 통해 구조를 그려보면 아래와 같습니다.
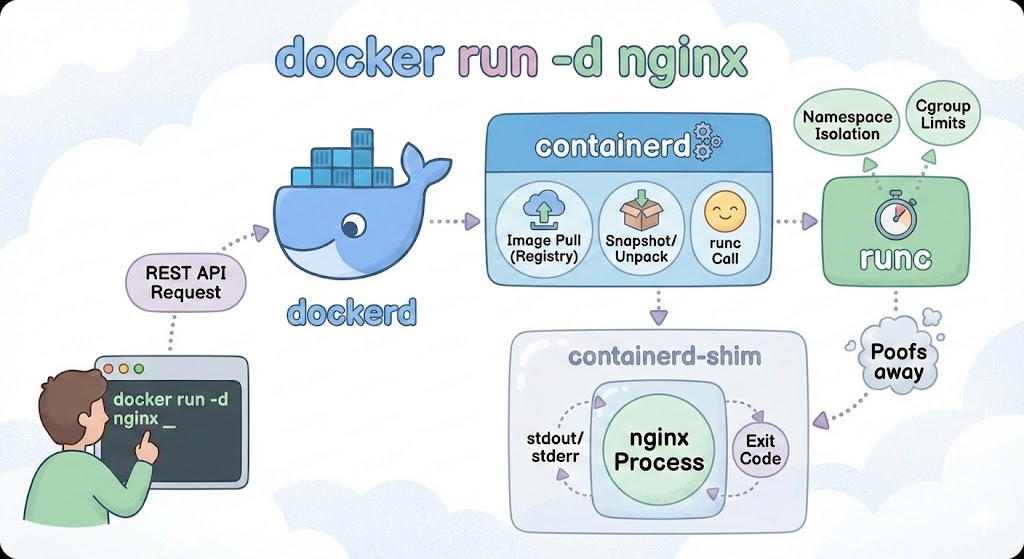
왜 이 계층 구조를 알아야 할까?
"도커가 알아서 해주는데 굳이?" 라고 생각할 수 있습니다. 실제로 평소에는 이런 내부 구조를 몰라도 컨테이너는 잘 돌아가기 때문에 소홀해지기 쉽습니다.
하지만 문제가 생겼을 때 이 구조를 알고 있으면 디버깅이 훨씬 수월해집니다. 컨테이너가 안 뜨거나, 네트워크가 안 되거나, 자원 제한이 이상하게 동작할 때 "어느 단계에서 막혔지?"로 접근할 수 있습니다.
또한 이 구조는 쿠버네티스의 작동 원리와 직결됩니다. 쿠버네티스의 각 노드에는 Kubelet이 설치되어 있는데, 이 Kubelet이 dockerd의 역할을 대신해 containerd와 runc에게 명령을 내립니다. 결국 Pod를 만드는 과정도 우리가 살펴본 흐름과 동일합니다.
Kubelet과 Pod에 대해서는 이후 시리즈에서 자세히 다루겠습니다. 지금은 "쿠버네티스도 결국 같은 리눅스 커널 기능을 쓴다"는 점만 기억해 주세요.
다음 이야기: 이미지는 어디서 오는가
프로세스가 어떻게 격리되는지, 그리고 실제 실행이 어떻게 일어나는지 살펴봤습니다.
그런데 아직 풀리지 않은 의문이 하나 있습니다.
docker run nginx를 실행하면 순식간에 nginx 실행에 필요한 파일들이 준비됩니다. 격리된 프로세스일 뿐이라면서, 이 수많은 파일들은 대체 어디서 오는 걸까요?
다음 2부에서는 이 격리된 공간을 채우는 이미지와 레이어, 그리고 OverlayFS에 대해 알아보겠습니다.
