Q : 해시테이블에 대해서 설명해주세요.
HashTable은 Key : Value 쌍으로 데이터를 저장하는 자료구조이며
값을 빠르게 읽고 저장하기 위해서 사용된다.
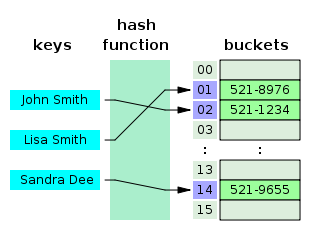
Key값에 해시함수를 적용하여 배열의 Index값을 구한 후 Index 위치에 값을 저장하거나 값을 읽어오는 자료구조를 해시테이블이라고 부른다.
Q : 그렇다면 해시 함수는 무엇인가요?
해시함수는 Key값에 수학적 연산을 사용하여 Index을 축출하는 함수이다.
해시함수에는 대표적으로 3가지 방법이 있다.
- Division Method :
해시테이블의 크기만큼 Key값을 나눈후 남은 나머지를 Index로 취하는 방법이다.
해시테이블의 크기가 2^n이 되지 않아야 효과가 좋다고 알려져있다.
- Digit Folding :
Key값을 ASCII코드로 바꾼후 해당 값을 Index로 취하는 방법이다.
- Multiplication Method :
Key값인 K, 0~1사이의 실수인 A, 2의 제곱수인 m을 사용하여 계산하는 방식이다.
h(K) = (KAmod1)*m;
Q : 인덱스 값이 같게 나오면 어떻게 처리해야 할까요?
인덱스 값이 같다면 해시충돌 알고리즘으로 해결한다.
대표적으로 체이닝기법과 오픈 어드레스 방법이 존재한다.
체이닝 기법
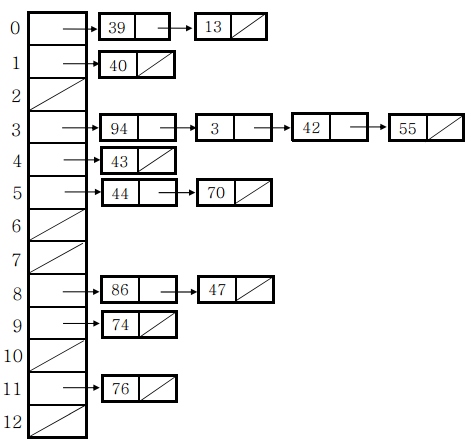
Index 위치에 LinkedList 자료구조를 두어 충돌시 LinkedList에 값을 저장하는 방법이다.
오픈 어드레스 방법
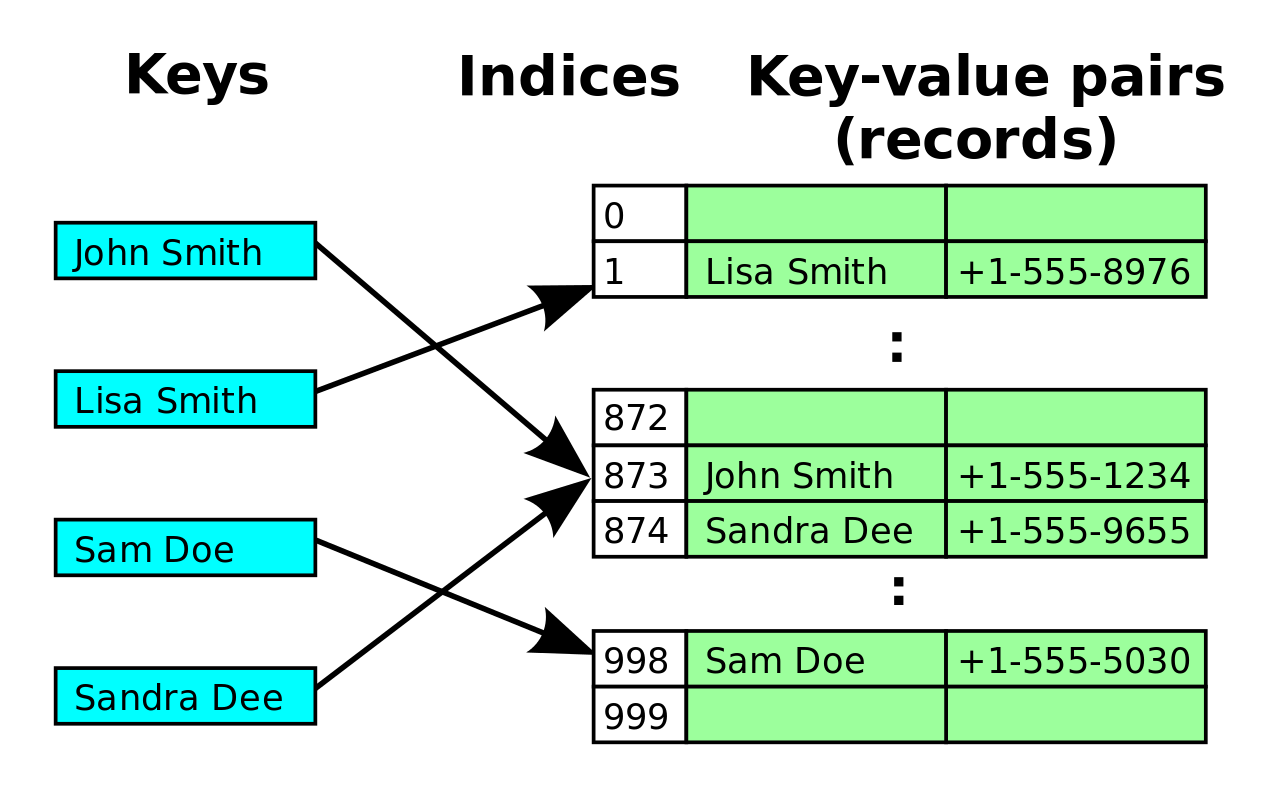
체이닝과 다르게 LinkedList을 넣는 추가 주소 공간이 필요하지 않다.
- 선형 조사 방식
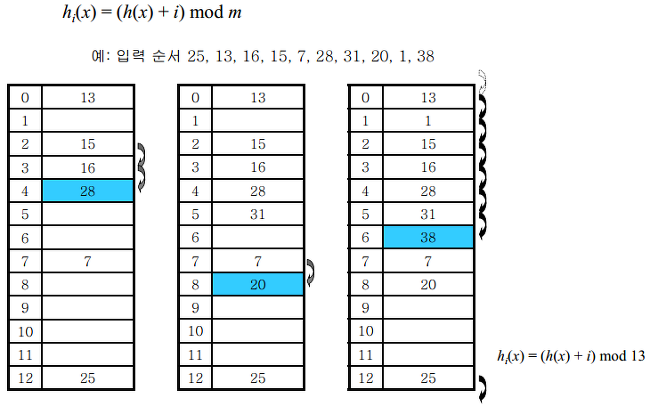
충돌시 해당 Index의 바로 다음 Index에 값을 위치시키는 방법.
단점 1. 단순한 방법이지만 군집화가 발생할 수 있다.
단점 2. 삭제시 다음과 같은 문제점이 발생할 수 있다.
위 그림을 예시로 보자면 숫자 28의 경우 해시함수로 얻은 Index 값이 2이다.
하지만 Index 2,3 에서 충돌이 일어나 선형 조사 방식으로 Index 4에 위치하게 되었다.
이 상황에서 Index 2의 값을 지우고 28을 찾기위해서 탐색을 돌린다면 Index 2에는 Null값이 들어있음으로 Null을 출력하게 된다.
- 이차 선형 조사 방식
선형 조사 방식의 경우 군집화가 자주 일어나기 때문에
2차 함수을 이용해 보폭을 넓혀 위치할 Index값을 늘리는 방법
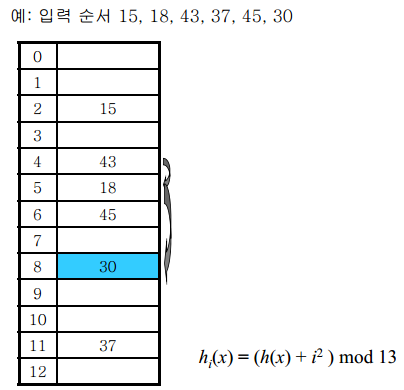
선형 조사 방식보다는 낫지만 여전히 군집화 문제는 피해갈 수 없다
Q : 해시테이블의 시간복잡도는?
O(n) :
선형 조사 방식의 경우 모든 값이 하나의 링크드 리스트에 위치할 경우
오픈 어드레스 방식의 경우 해시테이블이 꽉 차있을 경우
