본 벨로그의 내용 및 이미지는 다음의 강의를 참고해서 작성이 되었으며, 틀린 내용이 있을 수도 있으니 너그럽게 봐주시면 감사하겠습니다:)
- 널널한 개발자 TV님의 운영체제 강의 Process와 Thread의 차이
- 널널한 개발자 TV님의 운영체제 강의 Chapter03
- 10분 테코톡 코다의 Process vs Thread
- 한빛 아카데미 '쉽게 배우는 운영체제'
Process? Thread?
기본적으로 프로세스와 스레드는 cpu core에서 실행되는 하나의 처리 단위이다. 일반적으로 OS는 프로세스를 하나의 작업(=관리) 단위로 보고, 하나의 프로세스 안에는 개별화된 코드의 흐름이 있을 수 있는데, 그 개별화된 하나의 코드의 흐름을 스레드라고 정의한다. 이때 하나의 프로세스 안에 여러 개의 코드의 흐름이 있는 경우에 멀티스레딩이라고 한다.
Process란?
그렇다면 프로세스란 무엇인가?
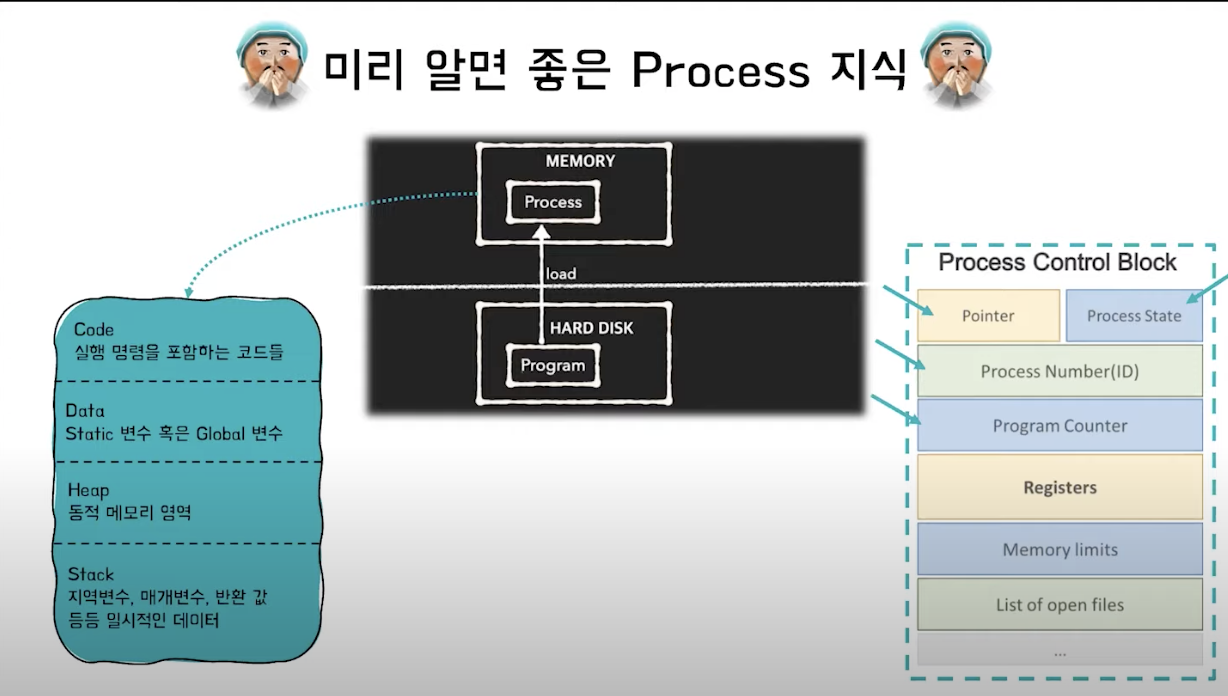
우리가 짜놓은 코드는 프로그램의 형태로 2차메모리인 HDD나 SDD에 저장이 된다. 이 프로그램을 실행하면, OS는 프로세스가 실행되기 위한 제한된 연산장치의 공간을 각 프로세스에 할당하는데 이를 Virtual Memory (가상 메모리)라고 한다. 위의 그림에서 보이는 것처럼 프로세스는 이러한 가상 메모리 공간을 실행 명령을 포함하는 코드들이 포함된 Code영역 Static 변수 혹은 Global 변수가 포함된 Data 영역, 동적 메모리 영역인 Heap 영역, Stack 영역이 차지하며, 해당 프로세스가 어느 정도까지 처리되었는지 확인하기 위해 필요한 Process Control Block (PID, PC, Register, ...) 역시 가상 메모리 공간 위에 올라간다.
서두에 하나의 프로세스 안에 여러개의 스레드가 존재할 수 있다고 했다. 이 말은 곧 하나의 프로세스 안에 있는 여러 개의 스레드의 공간은 OS가 그 프로세스에 할당된 가상 메모리로 그 공간이 한정된다는 뜻이다. 각 스레드들은 가상 메모리 내에서 공용 공간으로 사용할 수 있는 공간도 있지만, 각각의 스레드만이 사용할 수 있는 공간이 Thread Local Storage라는 공간도 존재한다.
다시 프로세스로 돌아와서, CPU는 한번에 하나의 작업만을 처리할 수 밖에 없기 때문에 여러 프로세스들을 동시에 (작은 단위로 나누어서 하나씩) 처리하기 위해서는 하나의 프로세스를 처리하다가 그 프로세스를 대기상태로 보내고, 다시 다른 프로세스를 처리하는 시분할 방식이 도입되었다.
Process의 상태
시분할 방식을 위해서는 각 프로세스는 여러 상태로 전이되면서 관리되는데, 프로세스가 가질 수 있는 상태를 구체적으로 명시해보면 다음과 같다.
- 생성 : 프로세스가 메모리에 올라와 실행 준비를 한 상태로 PCB가 생성된다.
- 준비 : 실행 대기 중인 프로세스가 자기 순서를 기다리는 상태이다. 프로새스 제어 블록은 ready queue에서 자기 순서를 기다리며 CPU 스케줄러에 의해 관리된다. 준비상태에서 자기 순번이 되면 dispatch(PID)를 통해 해당 프로세스가 실행이 된다.
- 실행 : 프로세스가 CPU를 할당받아 실행되는 상태이다. 하나의 프로세스는 타임 슬라이스라는 주어진 시간동안만 CPU를 사용할 수 있는데, 이 시간이 지나면 timeout(PID)를 통해 해당 프로세스는 실행 상태에서 준비상태로 상태가 옮겨진다. 만약 실행 상태 동안 작업이 완료되면 exit(PID)가 실행되어 프로세스가 정상 종료된다. 만약 실행 상태에 있는 프로세스가 입출력을 요청하면 CPU는 입출력 관리자에게 입출력을 요청하고 해당 프로세스에 대해 block(PID)를 실행하면 해당 프로세스는 대기 상태로 옮겨진다.
- 대기 : 실행 상태에 있는 프로세스가 입출력을 요청하면 입출력이 완료될때까지 기다리는 상태이다. 입출력이 완료되면 wakeup(PID)로 해당 프로세스는 다시 ready queue의 맨 뒤로 들어가 다시 준비 상태로 이동하게 된다.
- 완료 상태 : 프로세스가 종료되는 상태로, 왼료 상태에서는 코드와 사용햇던 데이터를 메모리에서 삭제하고 프로세스 제어 블록을 폐기한다. 비정상적으로 종료되는 강제 중료를 만나면 디버깅하기 위해 강제 종료 직전의 메모리 상태를 저장장치로 옮기기 위해 덤프를 뜨기도 한다.
Context Switching
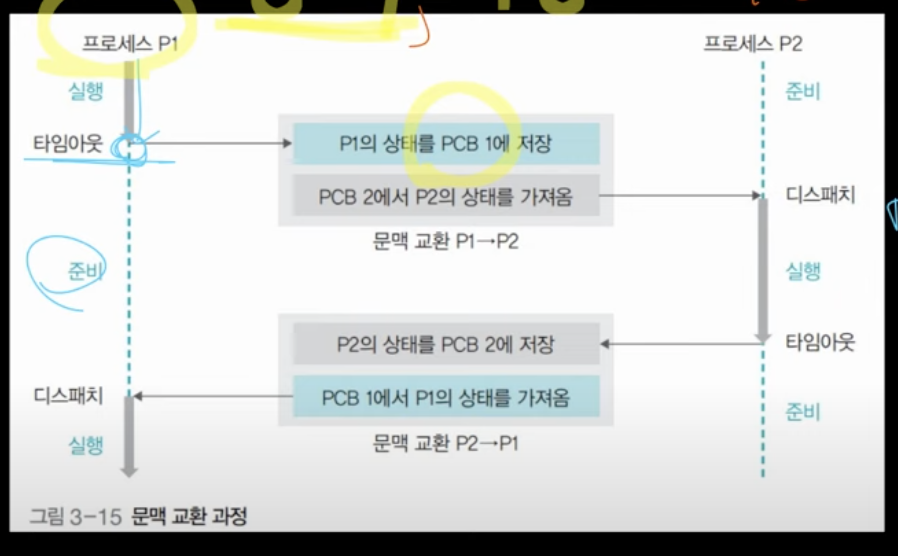
Context switching은 실행 상태에 있던 프로세스(P1)가 타임아웃이 되면 PCB1에 자신의 상태를 저장하고 준비 상태에 있던 프로세스 P2가 PCB2에 있는 자신의 상태를 가져와서 실행하는 CPU내에서 문맥이 변경되면서 연산이 실행되는 과정을 의미한다.
Process의 구조
프로세스의 구조는 위의 그림에서 보이는 것처럼 크게 4가지로 나누어진다.
- 코드 영역 : 실행 명령을 포함하는 코드가 포함되어 있는 영역 (일반적으로 읽기 전용으로 처리)
- 데이터 영역 : 크드가 실행되면서 사용하는 변수나 파일 등의 각종 데이터가 있는 영역 (읽기 쓰기 둘다 가능)
- 스택 영역 : 프로세스를 실행하기 위해 부수적으로 필요한 데이터
- 힙 영역 : 동적 메모리 영역
Process의 생성과 복사
프로그램이 시작되면 OS 프로그램을 실행하기 위해 프로세스를 생성한다. 다시 말해 OS는 프로세스를 위해 PCB 및 해당 프로세스를 실행하기 위한 공간인 Virtual Memory Space를 할당한다.
SSD로부터 매번 RAM까지 프로그램을 올리려면 시간이 많이 걸리기 때문에 이미 실행 중인 프로세스로부터 새로운 프로세스를 복사하는 방법도 있다. (이미 구글 크롬을 실행하고 있는데 새로운 창을 띄우거나 이미 워드프로그램을 실행 중인데 또 실행) 대표적인 방법으로는 fork()와 exec()이 있다고 한다.
- fork(): 프로세스를 복사할 때 새로운 VMS를 할당한다. 즉 복사된 프로세스는 새로운 PID, 코드, 데이터, 스택 영역을 확보하게 된다.
- exec(): 프로세스를 복사할 때 새로운 VMS를 할당하지 않고, 기존 프로세스가 할당 받았던 VMS 영역을 자식 프로세스가 덮어쓰는 방식이다. 이렇게 될 경우, PID, PPID, CPID는 그대로 유지되며, 코드 영역, 데이터 영역, 스택 영역만이 변경된다.
Thread
프로세스가 생성되면 CPU 스케줄러는 프로세스가 해야 할 일을 CPU에 전달하고 실제 작업은 CPU가 수행한다. 이때 CPU 스케줄러가 CPU에 전달하는 일 하나가 스레드이다.
Multi-tasking vs Multi-threading
그렇다면 스레드를 사용하는 이유는 무엇일까? 프로세스는 크게 프로세스가 실행되면서 바뀌지 않는 영역인 정적인 영역과 작업을 하면서 바뀌는 동적인 영역(레지스터, 힙, 스택)으로 구분된다. 이때 OS가 빠른 작업을 위해 fork()를 통해 프로세스를 여러 개 만들면 multi-tasking을 한다고 할 수 있다. 하지만 multi-tasking은 불필요한 정적 영역을 계속 메모리에 복사하기 때문에 비효율성을 초래한다. 따라서 하나의 VMS안에서 정적인 영역은 공유하고 스레드별로 독립적인 동적 영역을 가지면서 작업을 하는 multi-threading이라는 개념이 도입되었다. Multi-threading에서는 각 스레드 별로 동기화 이슈를 처리하는 것이 중요하다고 한다.
cf) Mutli-processing vs Mulit-threading
멀티프로세싱은 CPU를 여러 개 사용하여 여러 개의 스레드를 동시에 처리하는 작업 환경을 말한다. 하나의 컴퓨커에 여러 개의 CPU 혹은 하나의 CPU 내 여러 개의 코어에 스레드를 배정하여 동시에 작동하는 경우 멀티프로세싱이라고 한다. 반면 멀티스레딩은 '프로세스' 내 작업을 여러 개의 스레드로 분할함으로써 작업의 부담을 줄이는 프로세스 운영 기법이다.
멀티스레드의 장점으로는
- 응답성 향상 : 한 스레드가 I/O처리를 할 때 다른 스레드가 작업을 처리
- 자원 공유 & 효율성 향상 : 프로세스 내 자원을 공유함으로써 불필요한 자원 낭비 방지
멀티스레드의 단점으로는
- 한 스레드에 문제가 생기면 전체 프로세스에 영향을 미침 (인터넷 익스플로러)
Multi-thread Model
스레드는 프로세스와 마찬가지로 구현하는 주체에 따라서 '사용자 스레드'와 '커널 스레드'로 나누어 진다.
- 커널 스레드 : 커널이 직접 생성하고 관리하는 스레드
- 사용자 스래드 : 라이브러리에 의해 구현된 일반적인 스레드 (사용자 스레드가 커널 스레드를 사용하려면 시스템 호출로 커널 기능을 이용해야 함)
1 to N Model
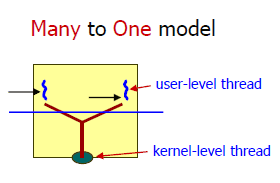
하나의 커널 스레드가 여러개의 사용자 스레드와 mapping되는 모델. 사용자 스레드 간의 문맥 교환과 같은 부가 작업이 줄어들어 속도가 빠르다는 장점은 있지만, 하나의 커널 스레드가 여러 사용자 스레드와 연결되어 있기 때문에 커널 스레드가 대기 상태에 들어가면 모든 사용자 스레드가 같이 대기 상태로 들어가게 된다. 또한 멀티코어나 멀티프로세스의 이점을 충분히 이용할 수 없다는 단점도 존재한다.
1 to 1 Model
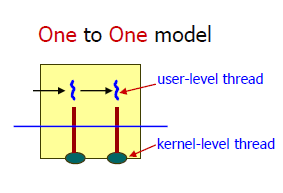
하나의 사용자 스레드가 하나의 커널 스레드와 mapping된 모델. 커널 스레드가 독립적으로 스케줄링되기 때문에 작업 효율성이 높으며, 사용자 스레드는 커널 스레드가 제공하는 보호 기능과 같은 기능을 사용할 수도 있다. 하지만 (여러 스레드 생성으로 인한) 높은 생성비용 및 문맥 교환할 때의 오버헤드 비용은 단점이다.
M to N Model
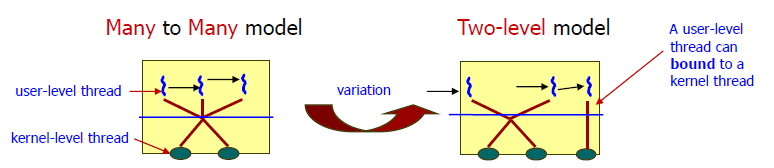
M개의 사용자 스레드가 N개의 커널 스레드로 (일반적으로 M>N) mapping되는 모델. 1 to N Model과 1 to 1 Model의 장단점을 모두 가지고 있다.
