본 벨로그의 내용 및 이미지는 다음의 강의를 참고해서 작성이 되었으며, 틀린 내용이 있을 수도 있으니 너그럽게 봐주시면 감사하겠습니다:)
- 널널한 개발자 TV님의 운영체제 강의 메모리 관리 개요
- 널널한 개발자 TV님의 운영체제 강의 절대주소와 상대주소
- 널널한 개발자 TV님의 운영체제 강의 메모리 오버레이와 스왑
- 널널한 개발자 TV님의 운영체제 강의 (물리)메모리 분할 방식
- 한빛 아카데미 '쉽게 배우는 운영체제'
32 bit 와 64 bit의 차이
비트(bit)는 한번에 다룰 수 있는 데이터의 최대 크기를 의미한다. 32bit CPU가 있다고 하면 당연하게도 이 CPU내부의 레지스터, 각종 버스의 크기의 대역폭도 32 bit이다. 이 32bit CPU의 경우 메모리 주소를 지정하는 레지스터인 MAR의 크기가 32bit이므로 표현할 수 있는 메모리 주소의 범위가 0~2^32-1 총 2^32이며 이를 16진수로 나타내면 00000000~FFFFFFFF이며 총크기는 4GB이다. 따라서 32bit CPU 컴퓨터는 메모리를 최대 4GB까지 사용할 수 있다. 64bit CPU까지 확장하여서 비교해해보면 다음과 같다.
| 구분 | 32bit CPU | 64bit CPU |
|---|---|---|
| 주소 범위 | 0~2^(32)-1번지 | 0~2^(64)-1번지 |
| 총크기 | 약 4GB | 약 16,777,216TB |
메모리 관리의 복잡성

컴퓨터는 메모리 공간을 관리할때 (위의 그림에서의 정사각형 한칸) 1byte 단위로 관리한다. CPU는 메모리에 있는 내용을 가져오거나 작업 결과를 메모리에 저장하기 위해 메모리 주소 레지스터(MAR)를 사용한다.
메모리 관리의 이중성
메모리 관리의 이중성이란 프로세스 입장에서는 메모리를 독차지하려 하고, 메모리 관리자 입장에서는 되도록 관리를 효율적으로 하고 싶어하는 것을 말한다. 메모리 관리 시스템은 이러한 메모리 관리의 이중성을 완만하게 해결학 위해 노력한다.
계층적 메모리 구조를 만든 이유 : 충분히 크지 않은 메모리에서 여러 작업을 동시에 실행해야 하는데, 작업 속도 역시 CPU에 필적해야 작업 효율이 떨어지지 않게 되므로 메모리를 계층적 구조로 만들어 작업 속도를 올리고 가격을 낮추어 계층적 메모리 구조로 만들었다.
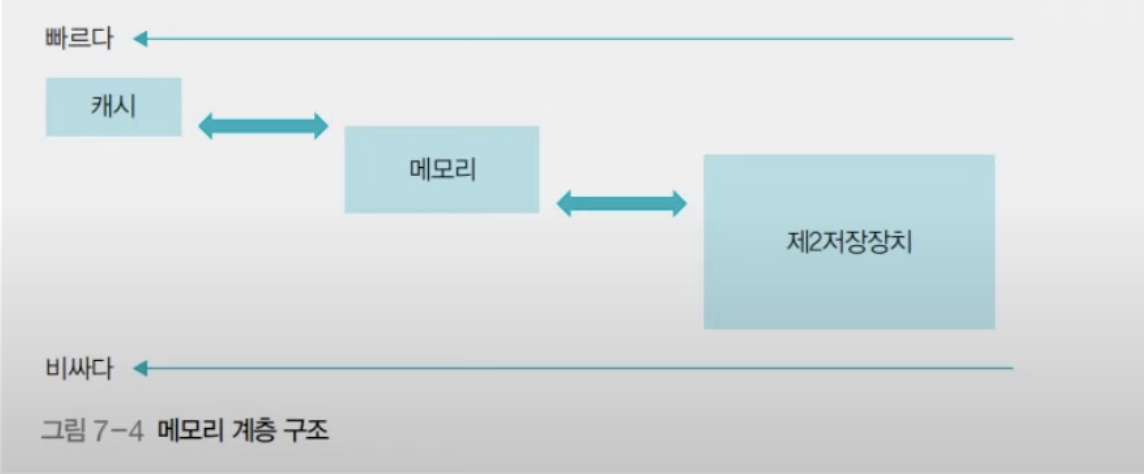
메모리 관리자의 역할
메모리는 메모리 관리자에 의해 관뢰되며 크게 가져오기 (fetch), 배치 (replacment), 재배치 (replacement)의 작업을 한다.
- 가져오기 (fetch): 프로세스와 데이터를 메모리로 가져오는 작업이다. 가져와야하는 데이터의 용량이 메모리의 크기를 넘어가는 경우에는 필요할때마다 수시로 가져오기도 한다. 필요하다고 예상되는 데이터를 미리 가져오는 방법도 있다.
- 배치 (replacement): 가져온 프로세스를 메모리의 어떤 위치에 올려놓을지 결정하는 정책이다. 메모리를 같은 크기로 자르는 것을 페이징(paging) 이라고 하며, 프로세스를 크기에 맞게 자르는 것을 세그멘테이션(segmentation) 이라고 한다. 둘다 한정된 메모리를 효율적으로 사용하기 위해 고안된 정책이다.
- 재배치 (replacement): 새로운 프로세스르 가져와야 하는데 메모리가 꽉 찼다면 메모리에 있는 프로세스를 하드디스크로 옮겨놓아야 새로운 프로세스를 메모르에 가져올 수 있다. 이때 어떤 프로세스를 내보낼지 결정하는 알고리즘을 교체 알고리즘이라고 한다.
절대주소와 상대주소
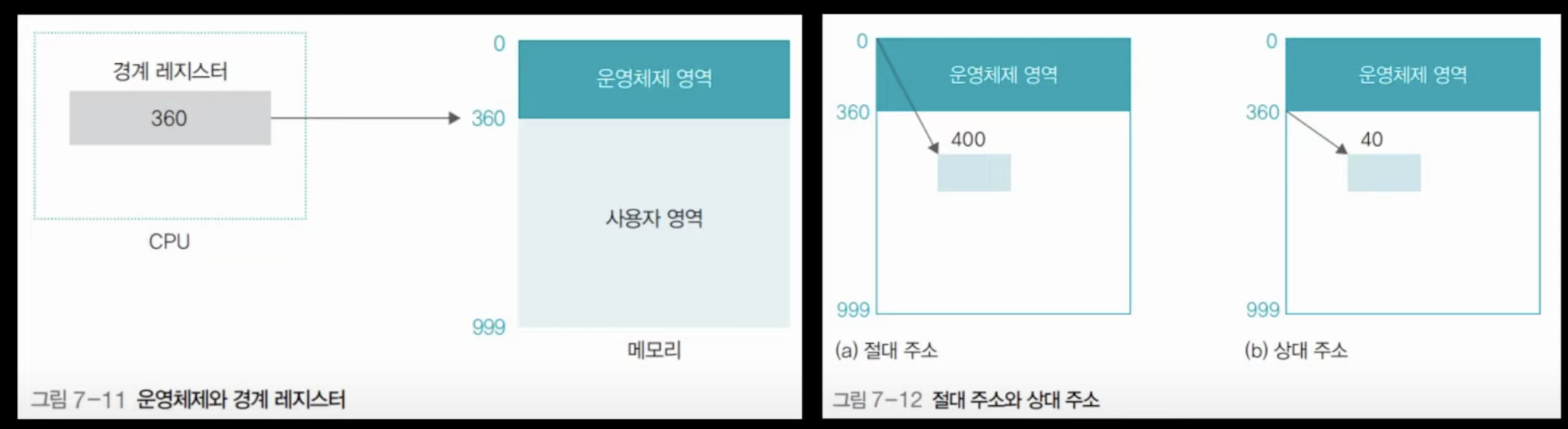
기본적으로 사용자 프로세스는 운영체제 영역을 피하여 메모리에 적재된다. 따라서 보다 실제 물리적인 프로세스의 위치가 주소가 아닌 상대적인 주소로 프로세스를 관리하기 시작하기 위해 상대주소라는 개념이 도입되었다. 위의 그림 7-12에서 360번지가 0번지로, 400번지가 40번지로 바뀌는데, 360번지와 400번지는 절대 주소 (MAR이 사용하는 주소로 실제 컴퓨터에 꽃힌 램 메모리의 주소)이고 0번지와 40번지는 상대 주소이다. 상대 주소는 논리 주소라고도 불리며, 가상 메모리와 관련이 있다고 한다.
메모리 오버레이
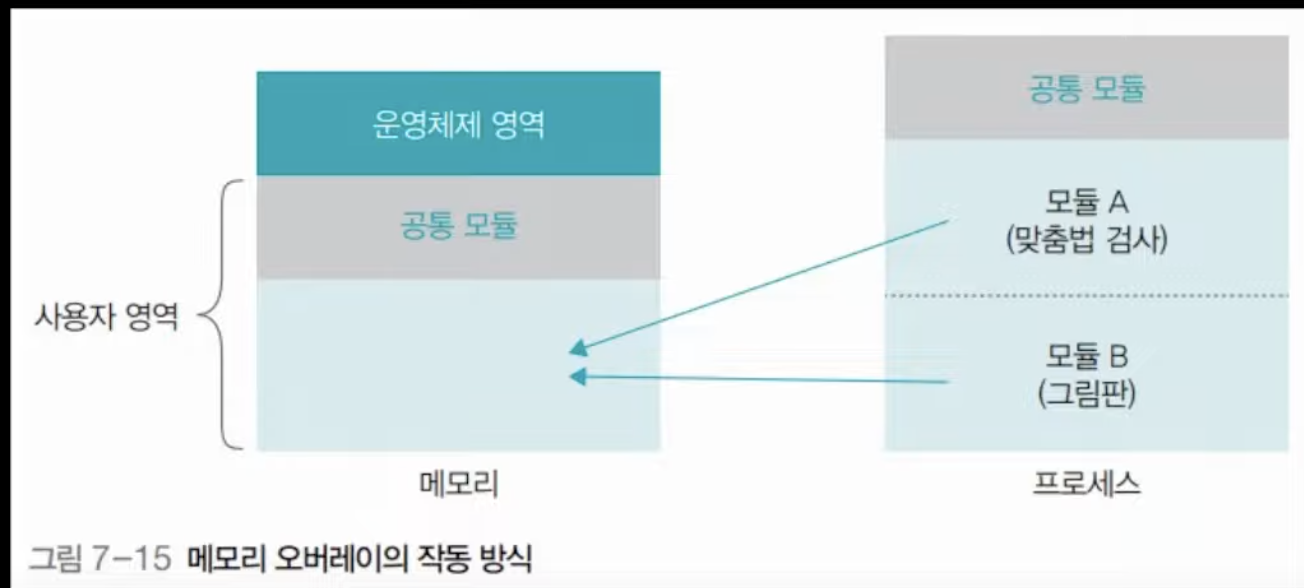
프로그램의 크기가 실제 메모리보다 클 때, 프로그램을 몇 개의 모듈로 나누고 필요할 때마다 모듈을 메모리에 가져와 사용하는 것을 메모리 오버레이라고 한다. 위의 그림 예시에서 처럼 아래 한글을 실행하면 모든 모듈들을 전부 램에다 올리고 실행하는 것이 아니라 맞춤법 검사나 그림판과 같은 모듈들을 필요할때마다 램에다 올려놓고 실행하는 방식이 메모리 오버레이 기법이다.
스왑
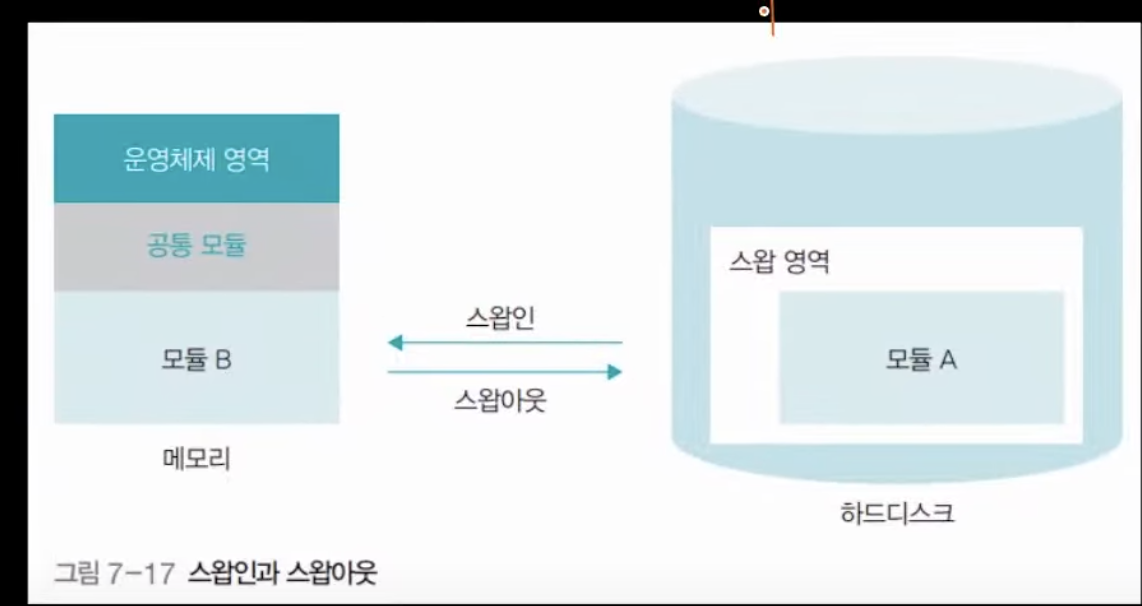
메모리 오버레이를 위해 프로세스를 모듈로 나누어서 메모리에 가져와서 실행을 했다. 그렇다면 나누어진 각 모듈들은 어디서 가져와서 실행할까? 바로 2차 메모리 공간인 SSD이다. 하지만 이 모듈들은 언제 다시 메모리록 가져올 지 모르기 때문에 메모리 관리자에 의해 스왑 영역이라는 공간에 특별 보관된다. 그리고 스왑 영역에서 메모리로 데이터를 가져오는 작업을 스왑 인, 메모리에서 스왑 영역으로 데이터를 내보내는 작업을 스왑 아웃이라고 한다. 스왑 인 & 아웃은 페이지 인 & 아웃 이라고 불리기도 한다.
메모리 분할 방식
메모리에 여러 개의 프로세스를 배치하는 방법은 크게 가변 분할 방식과 고정 분할 방식으로 나뉜다.
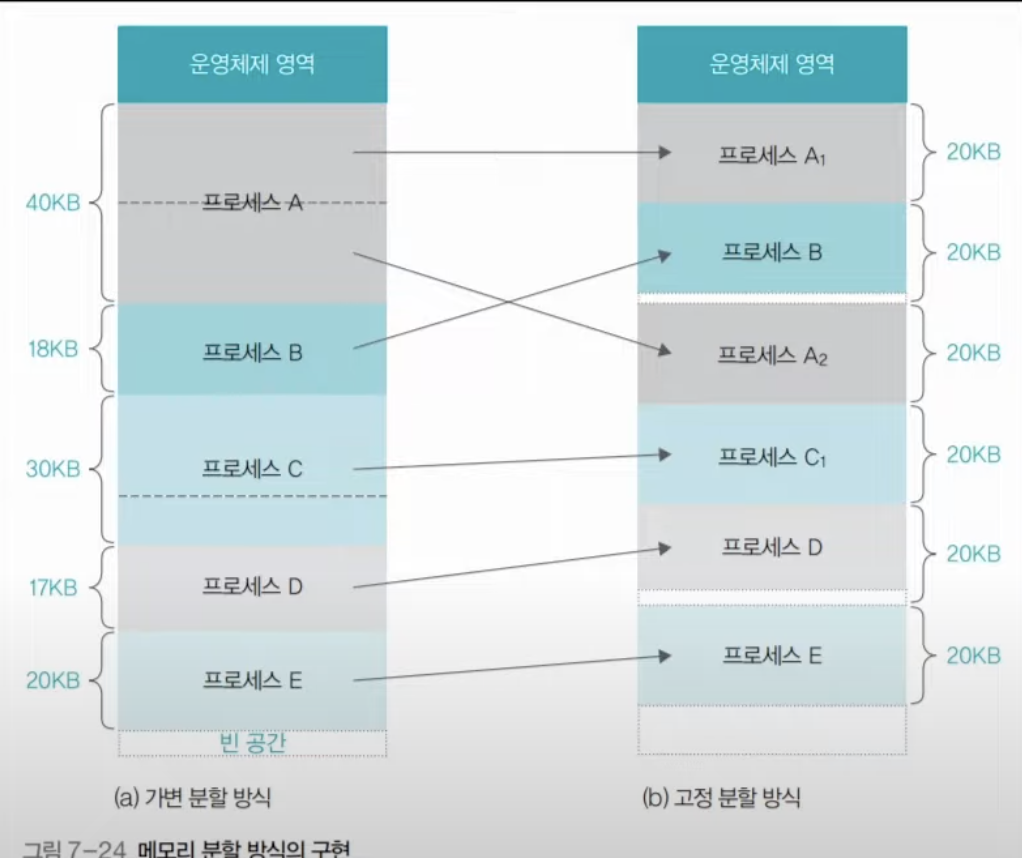
- 가변 분할 방식: 프로세스의 크기에 맞게 메모리를 분할하는 방식이다. 메모리 관리 측면에서 복잡하다는 단점이 있다. 예를 들어 위의 그림의 오른쪽 그림 처럼 18KB의 프로세스와 17KB의 프로세스가 종료된 후 25KB의 프로세스가 들어오면 적당한 공간이 없어서 배정하지 못하게 되는 문제가 생긴다. 이러한 문제를 외부 단편화 문제라고 하며, 이를 해결하기 위해서는 실행중인 프로세스들을 다른 메모리 공간으로 복사하고, 빈 공간들을 모으는 조각모음을 수행해야하기 때문에 자원이 소모된다는 한계가 존재한다.
- 고정 분할 방식: 프로세스의 크기에 상관없이 메모리를 같은 크기로 나누고, 큰 프로세스가 메모리에 올라오면 여러 조각으로 나누어 배치하는 방식이다. 관리적인 측면에서 가변 분할 방식보다는 유리하다는 장점이 있으나 위의 그림처럼 20KB로 메모리 공간을 나눈다고 했을 때, 18KB와 같은 프로세스가 올라오면 2KB와 같은 공간이 남는 내부 단편화 문제가 발생한다는 한계가 존재한다.
따라서 현대 운영체제는 기본적으로 고정 분할 방식을 사용하면서 일부분은 가변 분할 방식을 혼합한다고 한다.
