나동빈님의 책과 유튜브 강의인 '이것이 코딩 테스트다'를 바탕으로 스스로 공부한 내용을 정리한 글입니다.
참고한 영상의 링크는 아래와 같습니다.
이것이 코딩테스트다 - DFS / BFS
Preliminary
탐색이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정을 의미한다.
탐색에서 많이 쓰이는 자료구조는 다음과 같다.
- Stack: LIFO (Last In First Out)의 형태로 데이터가 유통되는 자료구조 > python에서 list & append() & pop()로 구현할 수 있음
- Queue: FIFO (First In First Out)의 형태로 데이터가 유통되는 자료구조 > python에서 from collections import deque를 사용 & append() '오른쪽으로 들어와서' & popleft() '왼쪽으로 나감' 로 구현 가능
Recursive Function
재귀함수란 자기 자신을 다시 호출하는 함수를 의미한다.
def recursive_function():
print('재귀 함수를 호출합니다.')
recursive_function()위같은 함수를 호출하면 max recursion depth에 도달해서 오류메세지를 호출한다.
따라서 재귀함수를 문제 풀이에서 사용할 때는 재귀 함수의 종료 조건을 반드시 명시해야 한다.
종료 조건을 포함한 재귀 함수 예제
def recursive_function(i):
# 100 번째 호출을 했을 때 종료되도록 종료 조건 명시
if i == 100:
return
print(i, '번째 재귀함수에서', i+1, '번째 재귀함수를 호출합니다.')
recursive_function(i+1)
print(i, '번째 재귀 함수를 호출을 종료합니다.')
recursive_function(1)유클리드 호제법이 재귀함수를 활용하는 대표적인 예시이다.
- 두 자연수 A,B에 관하여 (A>B) A를 B로 나눈 나머지를 R이라고 합니다.
- 이때 A와 B의 최대공약수는 B와 R의 최대공약수와 같습니다.
def gcd(a,b):
if a % b == 0:
return b
else:
return gcd(b, a%b)
print(gcd(192,162))DFS (Depth First Search)
- DFS는 깊이 우선 탐색이라고도 부르며 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
- DFS는 스택 자료구조 (혹은 재귀 함수)를 이용하며, 구체적인 동작 과정은 다음과 같다.
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접한 노드(직전에 방문한 노드에 아래 방향으로 간선이 뻗은 노드)가 하나라도 있으면 그 노드를 스택에 넣고 방문처리합니다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냅니다.
- 더 이상 2번의 과정을 수행할 수 없을 때까지 반복합니다.
예제 01
아래와 같은 그래프가 있을 때, 시작 노드 1을 기준으로 번호가 낮은 인접 노드를 기준으로 DFS를 수행하시오.
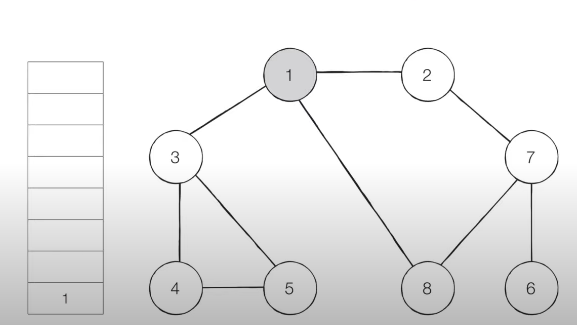
gragh = [
[],
[2,3,8],
[1,7],
[1,4,5],
[3,5],
[3,4],
[7],
[2,6,8],
[1,7]
]
visited = [False]*9
def dfs(gragh, i, visited):
# 현재 노드를 방문처리
visited[i] = True
# 방문한 노드를 print
print(i, end=' ')
for v in gragh[i]:
# 인접한 노드 중에서 방문하지 않았으면 재귀호출로 방문진행
if not visited[v]:
dfs(gragh, v, visited)
dfs(gragh, 1, visited)위의 코드를 공부하면서 가장 중요하다고 느낀 2가지는 다음과 같다.
- 그래프구조를 표현할때, 인점노드를 기준으로 표현하며 그래프 상에서 첫번째 노드는 index=0을 기준으로 표현하는 것이다. (이렇게 하면 문제상황에서 표현하고자 하는 index와 동일하게 표현할 수 있게 된다.)
- 재귀호출을 할 때, 깊은 노드에서 이미 인접노드들을 다 방문하면 if not visted[v] == false임으로 자연스럽게 본인의 dfs(graph,i,visted)가 return 없이 마무리 되고 본인을 호출했던 dfs(graph,i,visted)으로 다시 돌아가게 된다.
BFS (Breadth First Search)
- BFS는 넓이 우선 탐색이라고도 부르며 그래프에서 가까운 부분을 우선적으로 탐색하는 알고리즘이다.
- BFS는 큐 자료구조 이용하며, 구체적인 동작 과정은 다음과 같다.
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 더 이상 2번의 과정을 수행할 수 없을 때까지 반복합니다.
from collections import deque
gragh = [[], [2, 3, 8], [1, 7], [1, 4, 5], [3, 5], [3, 4], [7], [2, 6, 8],
[1, 7]]
visited = [False] * 9
def bfs(gragh, i, visited):
# 탐색 시작 노드를 큐에 삽입하고 방문처리
queue = deque([i])
visited[i] = True
# 방문한 노드를 print
print(i, end=' ')
while queue:
# 큐에서 노드를 꺼냄
v = queue.popleft()
for i in gragh[v]:
# 인접노드가 방문하지 않은 노드면 전부다 방문처리
if not visited[i]:
queue.append(i)
visited[i] = True
print(i, end=' ')
bfs(gragh, 1, visited)마찬가지로 BFS를 공부하면서 느꼈던 점은 2가지이다.
- 첫번째 노드에 대한 처리 : 첫번째 노드도 바로 큐에 삽입하고 '꺼낸 다음 인접한 이웃 노드의 방문여부를 탐색'한다. ''의 부분은 일반적인 노드들에 있어서 적용되는 함수인데 이게 예외적인 첫번째 노드에도 어떻게 잘 적용되도록 코드를 짜는게 관건으로 보인다.
- BFS는 해당 노드에 도착했을때 인접한 노드를 모두 방문처리하면서 search하는 알고리즘이다. (vs DFS는 해당 노드에 도착했을때 한 노드씩 타고 들어가면서 search하는 알고리즘이다.)
문제 01 - 음료수 얼려 먹기
- 첫번째 줄에 얼음 틀의 세로 길이 Nrhk 가로 길이 M이 주어진다. (1<=N,M<=1000)
- 두번째 줄부터 N+1 번째 줄까지 얼음 틀의 형태가 주어진다.
- 이때 구멍이 뚫려있는 부분은 0, 그렇지 않은 부분은 1이다.
- 한번에 만들 수 있는 아이스크림의 개수를 출력한다.
N, M = map(int, input().split())
graph = []
for _ in range(N):
graph.append(list(map(int, input())))
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
count = 0
def dfs(x, y):
if 0 > x or N <= x or 0 > y or M <= y:
return False
if graph[x][y] == 0:
graph[x][y] = 1
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
'''
재귀 호출된 함수가 반환하는
True/False에 너무 집착하지 말자
'''
dfs(nx, ny)
return True
else:
return False
for i in range(N):
for j in range(M):
if dfs(i, j) == True:
count += 1
print(count)
이 문제의 접근법은 다음과 같다.
전체 노드를 방문하는 것은 기본적인 전제이다. 특정 노드의 인접 노드가 아직 방문하지 않았다면 DFS로 연결된 모든 방문 지점을 방문하고 (도착하면 > 방문표시 > 재귀함수 호출) count를 추가하는 것이다.
-
이 문제나 위의 재귀함수 문제를 풀면서 느꼈던 것중에 제일 헷갈렸던 부분은 (1) 처음으로 호출했던 함수의 반환값이랑 (2) 그 이후에 재귀적으로 호출하는 함수의 반환값이랑 다르게 처리 로직을 두고 생각해도 된다는 점이다.
-
위의 문제의 경우 첫번째 호출하는 함수는 True/False를 반환하고 이것 받아서 for문에 있는 어떤 처리를 하지만 재귀적으로 호출하는 함수는 굳이 반환된 True/False를 가지고 무엇을 하지 않는다 (호출되고 그래프 안에 숫자 표기만 바꿔줄뿐). 내가 재귀적으로 호출한 함수들도 이 반환된 True/False로 무엇을 해야하도록 함수를 짜야한다는 강박때문에 시간이 좀 오래걸린 문제이다.
문제 02 - 미로 탈출
- 첫째 줄에 두 정수 N, M (4<=N ,M <=200)이 주어집니다. 다음 N개의 줄에는 각각 M개의 정수 (0 혹은 1)로 미로의 정보가 주어진다. 각각의 수들은 공백 없이 불어서 입력으로 제시된다. 또한 시작 칸과 마지막 칸은 항상 1이다.
- 첫째 줄에 최소 이동 칸의 개수를 출력한다.
from collections import deque
N, M = map(int, input().split())
graph = []
for _ in range(N):
graph.append(list(map(int, input())))
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
[나의 풀이]
def bfs(x, y):
count = 0
queue = deque()
queue.append((x,y))
graph[x][y] = 0
while queue:
x, y = queue.popleft()
count +=1
for i in range(0, 4, 2):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < N and 0 <= ny < M and graph[nx][ny] == 1:
graph[nx][ny] = graph[nx][ny] - 1
queue.append((nx,ny))
assert x == (N-1) and y == (M-1)
return count
[공식 풀이]
def bfs(x, y):
queue = deque()
queue.append((x, y))
while queue:
x, y = queue.popleft()
for i in range(0, 4):
nx = x + dx[i]
ny = y + dy[i]
if nx < 0 or nx >= N or ny < 0 or ny >= M:
continue
if graph[nx][ny] == 0:
continue
if graph[nx][ny] == 1:
# 인접 노드에 대한 값을 queue에 넣기 전에 값을 업데이트
graph[nx][ny] = graph[x][y] + 1
queue.append((nx, ny))
print(graph)
return graph[N - 1][M - 1]
print(bfs(0, 0))
-
위의 문제의 정석적인 접근법은 다음과 같다.
(노든 간선간의 가중치가 같다는 가정 하에) BFS를 활용하여 시작 시점에서부터 가까운 노드부터 차례대로 그래프의 모든 노드를 탐색한다.
특정한 노드(이전 노드에 의해서 인접해 있기 때문에 밤문하게 된 노드)를 방문하면 그 이전 노드의 거리에 1(문제 상황마다 다름)을 더한 값을 큐에 넣는다.
-
이전 DFS 문제도 그렇고 가능한 모든 경로를 모두 탐색하고 ((1,1) > (1,2)로 가서 다시 (1,1)을 큐에 넣는 상황도 발생함), 그 중 최적의 값을 찾는다는 가정을 하지 않았다. 하지만 문제 풀이를 보면 그렇게 풀도록 설계가 되어있다. (앞으로 이렇게 푸는 사고가 필요할 듯 하다.)
