
개요
-
데이터를 분석하면서 NaN값을 깔끔하게 보여주는 데이터프레임을 생성하거나, plot 개수에 맞추어 자동으로 사이즈가 조절되며 시각화 시켜주는 코드 등의 필요성을 느꼈다.
-
로컬에 py파일로 저장해서 혼자 사용할 수도 있지만 이왕 만든 모듈을 배포하면 나와 같은 고통을 겪는 사람들에게 도움이 될 것 같아 모듈을 제작, 배포하게 되었다.
라이브러리에 들어갈 코드파일
- 데이터를 분석할 때 불편하다고 생각했던 요소를 전부 넣기로 결정하였다.
- 상관분석 관련 함수 --> corr.py
- 시각화 관련 함수 --> plots.py
- 그 외의 함수 --> useful.py
-
이렇게 3분류로 나누어 파일을 생성하였다.
-
Tree 상태는 다음과 같다. (폴더명이 곧 import할 모듈의 이름이 된다)
__init__.py 설정

- lib (하위) 폴더의
__init__.py세팅으로 3개의 py파일을 불러온다.

- rock (상위) 폴더의
__init__.py세팅으로 lib 폴더를 불러온다.
- 사실 이 부분은 이해가 부족해 불러오는 객체와 불러온다는 표현이 맞는지 모호하다.
- class 등을 이용한 더 좋은 방식이 있다면 그걸 사용하는 것을 추천한다.
라이브러리로 만들기(1)
- 위의 py파일들을 라이브러리로 만들기 위해서는 setup.py 파일이 필요하다
import setuptools
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
setuptools.setup(
name="rock_pre_h", # 모듈 이름
version="0.1.5", # 버전
author="P444", # 제작자
author_email="laklak5000@gmail.com", # contact
description="rock-for-easy-preprocessing", # 모듈 설명
long_description=open('README.md').read(), # README.md에 보통 모듈 설명을 해놓는다.
long_description_content_type="text/markdown",
url="프로젝트 깃허브 주소",
install_requires=[ # 필수 라이브러리들을 포함하는 부분인 것 같음, 다른 방식으로 넣어줄 수 있는지는 알 수 없음
"matplotlib==3.5.2",
"numpy==1.21.5",
"pandas==1.4.4",
"scikit_learn==1.2.0",
"scipy==1.9.1",
"seaborn==0.11.2",
"setuptools==63.4.1",
],
package_data={'': ['LICENSE.txt', 'requirements.txt']}, # 원하는 파일 포함, 제대로 작동되지 않았음
include_package_data=True,
packages = setuptools.find_packages(), # 모듈을 자동으로 찾아줌
python_requires=">=3.9.13", # 파이썬 최소 요구 버전
)
-
위의 코드에서
packages = setuptools.find_packages()는__init__.py계층구조로 된 폴더를 알아서 찾아준다. -
LICENSE는 MIT LICENSE를 넣어주었다.
-
그리고 README.md에는 모듈에서 사용가능한 함수의 목록과 그에 대한 설명을 적어두었다.
라이브러리로 만들기(2) & 배포
-
터미널로 진입해 setup.py가 있는 경로로 이동한다.
cd setup.py의 경로 -
python setup.py sdist bdist_wheel<-- 터미널에 입력시 pypi에 배포가능한 whl 형태의 파일을 dist 폴더내에 생성해준다. -
pypi 홈페이지에 가입후
python -m twine upload dist/*명령어로 라이브러리를 배포한다. id와 password는 자신의 pypi 계정 정보를 입력하면 된다. -
python -m twine upload -u pypi아이디 -p pypi비밀번호 dist/*로 입력하면 바로 업로드 된다.
만든 모듈 확인 및 테스트
-
위의 링크는 내가 만든 파이썬 라이브러리이다. 내 이름과 data_preprocessing에서 pre를 넣어 만들었다.
-
h는 버전관리 방법을 제대로 알지못할때 맨뒤에 알파벳을 a부터 넣어 시도했어서 h까지 증가했다...
-
제대로 업로드가 되었다면 README.md의 설명내용이 보이고 라이브러리를 설치할 수 있는 pip 명령어가 보일 것이다. 입력해서 설치해주자

- 라이브러리가 다 설치되면 import를 이용해 불러오자, 불러오는 방법은
__init__.py의 세팅을 어떻게 했느냐에 따라 조금씩 다를 수 있다.
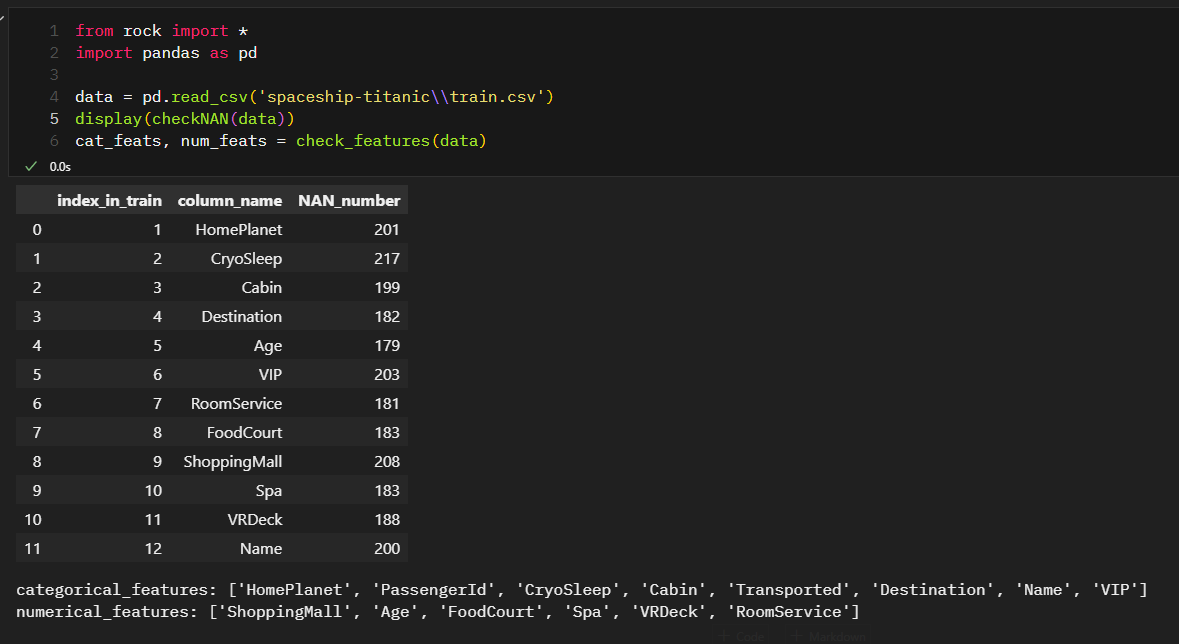
-
간단한 테스트로 checkNAN
(NAN값을 가진 컬럼명, NAN값의 개수, 각 컬럼의 인덱스)함수와 check_features범주형과 수치형 변수 자동검색함수를 사용해보았다. -
문제없이 작동하는 것을 보아 배포와 설치가 잘 수행된듯 보인다. 데이터를 다루다보면 직접만든 함수가 하나둘씩 쌓인다. 그때그때 파일에서 찾아서 사용하기보다 하나로 묶어서 라이브러리로 만든다면 휠씬 사용하기 편해질 것이다.
