Ceph
출처: https://wcc8088.tistory.com/127
1. Ceph 개요
Ceph란 분산 클러스터 위에서 object storage를 구현해 object, block, file level의 storage 인터페이스를 제공한다. 하나로 object, block storage, file system 모두를 제공한다는 것이 장점. SPOF(Single Point Of Failure) 없는 완전한 분산처리와 exabyte 단위까지 확장 가능하다.
Ceph Storage Cluster는 다수의 서버 Ceph Node 로 구성되며 Ceph Object Storage, Ceph Block Device, Ceph File System을 서비스합니다. Ceph Storage Cluster는 최소한 하나의 Ceph Monitor, Ceph Manager, Ceph OSD(Object Storage Daemon)이 필요합니다. Ceph File System을 운영하기 위해서는 Ceph Metadata Server 도 필요합니다. 모든 서비스는 RADOS (Reliable Autonomic Distributed Object Store) 기반위에서 동작합니다.
1.1 시스템 요구사항
1.1.1 Hardware 최소 / 권장 사항
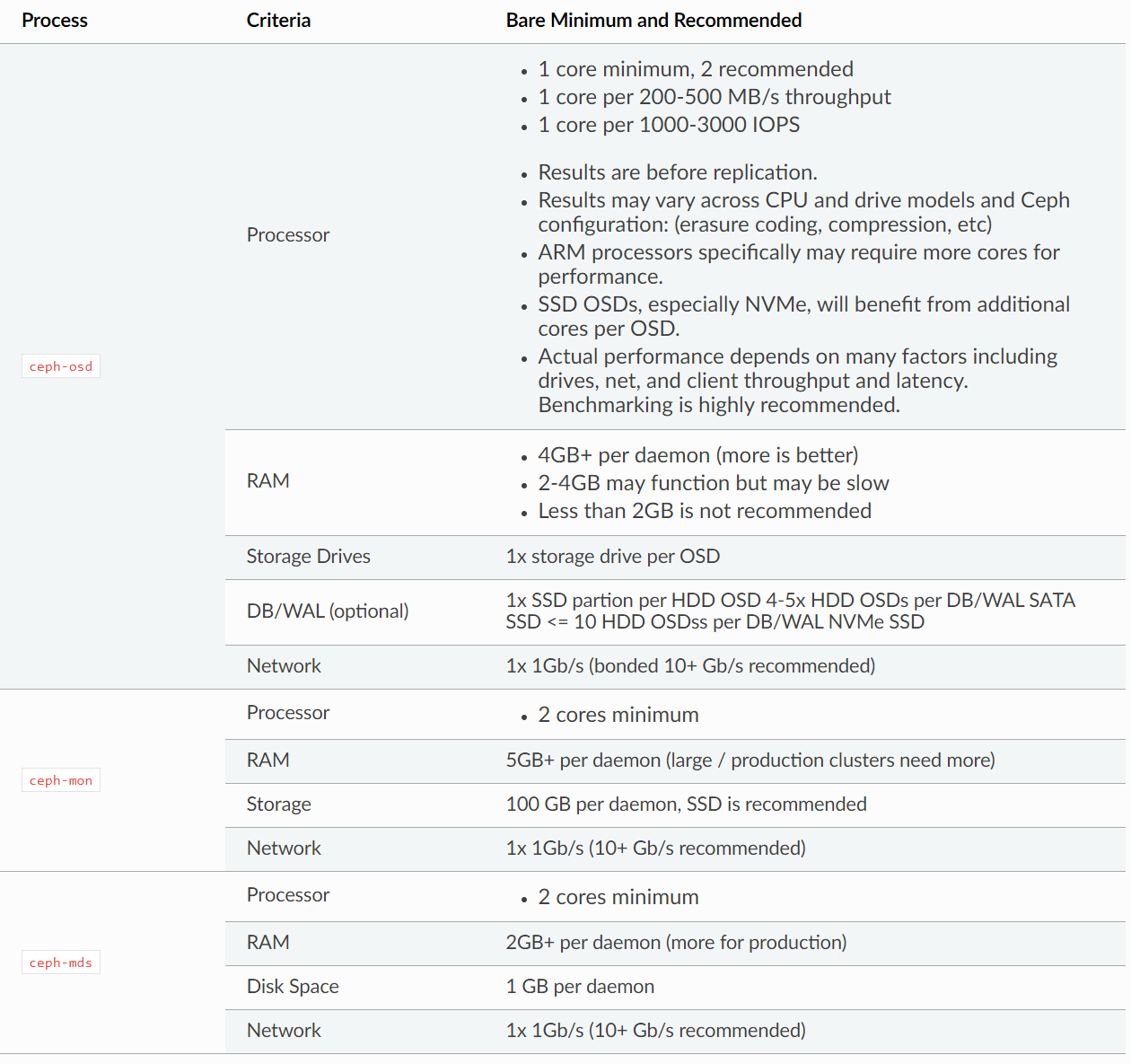
| 항목 | 요구사항 |
|---|---|
| CPU | CephFS metadata servers는 상대적으로 높은 CPU 요구. 가벼운/저장용 경우 OSD 당 1 core, VM에 할당된 RBD 볼륨의 경우 OSD당 2 core 필요. CPU 요구사항 충족을 위해 다수의 노드에 구성 권장. |
| Memory | Monitor/manager nodes는 일반적으로 64GB, 수백 개의 OSD가 있는 경우 128GB 이상 필요. BlueStore OSD는 4 ~ 8GB 권장. osd_memory_target을 2GB 이하로 설정하지 않음 권장. |
| Disk Drive | 용량당 가격을 고려하여 1TB 디스크 권장. 하나의 SAS/SATA 드라이브에 여러 개의 OSD 운영 비권장. NVMe 드라이브는 저장 성능을 위해 두 개 이상의 OSD로 나누어 사용 권장. 하나의 드라이브에서 OSD, 모니터, Metadata 서버를 동시에 운영 비권장. SSD 선택 시 용량에 따른 성능 테스트 권장. |
| Networks | 랙 당 10GB 이상의 네트워크 환경 권장. 스위치는 40GB 이상의 네트워크 환경 권장. |
2. Ceph 설치
2.1 설치 방법
- cephadm : 권장 설치 방법. CLI와 Dashboard 지원. Python3와 Docker 또는 Podman 필요.
- rook : Kubernetes 환경에서 권장. CLI와 Dashboard 지원.
- ceph-ansible : Ansible 을 통한 설치. 향후 Dashboard 지원 안됨.
- ceph-deploy : Ceph Cluster 빠른 설치 지원. 향후 지원 안됨.
- ceph-salt installs Ceph using Salt and cephadm.
- jaas.ai/ceph-mon installs Ceph using Juju. (https://jaas.ai/ceph-mon)
- github.com/openstack/puppet-ceph installs Ceph via Puppet. (https://github.com/openstack/puppet-ceph)
2.2 cephadm 을 통한 설치 절차 (Rocky Linux 기준)
2.2.1 DISTRIBUTION-SPECIFIC INSTALLATIONS
배포판 기준으로 간단히
dnf search release-ceph
dnf install --assumeyes centos-release-ceph-reef
dnf install --assumeyes cephadm2.2.2 RUNNING THE BOOTSTRAP COMMAND
cephadm bootstrap --mon-ip *<mon-ip>*이것을 실행하면
- Create a monitor and manager daemon for the new cluster on the local host.
- Generate a new SSH key for the Ceph cluster and add it to the root user’s /root/.ssh/authorized_keys file.
- Write a copy of the public key to /etc/ceph/ceph.pub.
- Write a minimal configuration file to /etc/ceph/ceph.conf. This file is needed to communicate with the new cluster.
- Write a copy of the client.admin administrative (privileged!) secret key to /etc/ceph/ceph.client.admin.keyring.
- Add the _admin label to the bootstrap host. By default, any host with this label will (also) get a copy of /etc/ceph/ceph.conf and /etc/ceph/ceph.client.admin.keyring .
2.2.3 CLI, ceph-common 패키지 설치
cephadm shell
cephadm shell -- ceph -s
cephadm add-repo --release pacific
cephadm install ceph-common2.2.4 설치 확인
ceph -v
ceph status
2.2.5 Host 추가
ceph orch host label add *<host>* _admin2.2.6 Storage 추가
ceph orch apply osd --all-available-devices
인프라 엔지니어