문제
https://school.programmers.co.kr/learn/courses/30/lessons/59413
보호소에서는 몇 시에 입양이 가장 활발하게 일어나는지 알아보려 합니다. 0시부터 23시까지, 각 시간대별로 입양이 몇 건이나 발생했는지 조회하는 SQL문을 작성해주세요. 이때 결과는 시간대 순으로 정렬해야 합니다.
풀이
존재하지 않는 값의 집계
일단 이 문제의 큰 틀은 쉽다
GROUP BY로 HOUR(datetime)을 잡고 count(*)를 해주는 것
하지만 이와 같이 문제를 풀게 되면 1가지 치명적인 문제가 생기는 데,
집계되지 않은 행이 존재할 수 있다는 것이다
SELECT
hour(datetime) as "HOUR"
, count(*) as "COUNT"
FROM
animal_outs
GROUP BY
1
ORDER BY
1
;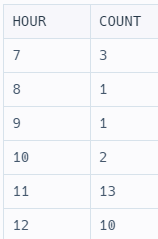
"0시: 0건"과 같이 데이터 상에 존재하지 않는 경우도 출력을 해야하지만, 단순 GROUP BY로는 이를 수행할 수 없다
dim_table() 만들기
이 문제를 해결하기 위해서는 0시 ~ 23시를 표시할 수 있는 dim_table을 만드는 과정이 필요하다
가장 간단한 방법은 직접 모든 값을 입력하는 것
SELECT
0 as "HOUR"
UNION
SELECT
1 as "HOUR"
UNION
SELECT
2 as "HOUR"
...
...
...이 과정을 0부터 23까지 반복하면 된다
물론 이는 비효율적이며, dim_table이 커지게 된다면 실질적으로 사용하기 어려운 방법이다
변수 할당하기: SET
SQL에는 변수를 할당하는 방법으로 SET을 사용할 수 있다
SET @HOUR = -1;위처럼 SET을 활용해서 변수를 할당할 수 있다
여담으로 @를 사용하는 이유는 세션 변수로 초기화, 할당했기 때문이다
변수에는 지역 변수, 세션 변수, 시스템 변수의 3종류가 있으며 각각 @를 0개, 1개, 2개 사용해야 한다
자세한 내용은 아래 링크 참고
[MySQL] 변수의 종류
이를 활용해 아래와 같이 반복적으로 계산을 진행한 결과를 얻어낼 수 있다
(Python에서 for문을 통해 n += 1을 수행한 것과 동일한 결과)
SET @HOUR = -1;
SELECT
@HOUR := @HOUR +1 as "HOUR"
FROM
animal_outs
WHERE
@HOUR < 23
;이 때, WHERE절에서는 HOUR가 아니라 @HOUR를 사용해야 한다는 점을 주의하자
HOUR은 SELECT에서 만들어진 컬럼인데, SQL은 작동 순서 상 WHERE절이 SELECT에 우선하기에 HOUR로 지정하면 Unknown column 오류가 발생하게 된다.
또한 @HOUR을 초기화할 때 '='가 아닌 ':='을 사용해야 한다는 점도 유의.
'='는 SET절을 이외에서는 비교연산자로 취급되므로, SELECT 절에서 변수를 초기화할 경우 ':='를 사용해야 한다.
(Python에서 '='과 '=='의 차이를 떠올리면 비슷하다)
LEFT JOIN
dim_table이 만들어졌다면, 가장 직관적으로는 LEFT JOIN을 통해 문제를 풀 수 있다.
dim_table을 LEFT에 놓고, animal_outs를 RIGHT에 두어 JOIN을 하면 된다
SET @HOUR = -1;
WITH dim_hour AS (
SELECT
@HOUR := @HOUR +1 as "HOUR"
FROM
animal_outs
WHERE
@HOUR < 23
)
SELECT
d.hour
, count(hour(ao.datetime)) as "COUNT"
FROM
dim_hour d
LEFT JOIN animal_outs ao ON d.hour = hour(ao.datetime)
GROUP BY
d.hour
ORDER BY
d.hour
;서브쿼리 중 집계
혹은 SELECT문에서 바로 COUNT(*)를 구하도록 할 수도 있다
SET
@HOUR = -1;
SELECT
@HOUR := @HOUR + 1 as "HOUR",
(
SELECT
count(*)
FROM
animal_outs
WHERE
@HOUR = hour(datetime)
) as "cnt"
FROM
animal_outs
WHERE
@HOUR < 23
;두 쿼리의 차이는... gpt 피셜로는 아래와 같다

사실 나는 LEFT JOIN이 더 직관적으로 느껴지기에 이 요약에는 동의할 수 없다만.
재귀 CTE (RECURSIVE CTE)
[SQL] RECURSIVE CTE 이해하기
다음으로 SET을 통한 변수 할당 외에도 재귀 CTE를 사용하여 dim_table을 만드는 방법도 있다
현재 필요한 값은 0부터 23까지 1씩 증가하는 등차수열 형태이고,
이는 결국
for i in range(0, 23+1):
print(i)
i +=1이다.
SQL에서도 재귀 CTE를 통해 이와 같은 형태를 구현할 수 있다.
참고 링크에 따르면, 재귀 CTE의 구조는 아래와 같다. 자세한 내용은 해당 링크 참고
WITH RECURSIVE CTE_이름 AS (
-- Anchor Member: 재귀의 시작점
SELECT ...
UNION ALL
-- Recursive Member: 재귀적으로 추가할 데이터
SELECT ...
FROM CTE_이름
JOIN ...
WHERE ...
)
SELECT * FROM CTE_이름;
해당 문제에 대입시켜보면,
Anchor Member에서 n = 0을 출력하고
그 뒤로 Recursive Member에서 n += 1을 출력하는 과정을 반복하면 된다
WHERE절을 통해 n < 23을 지정하면 n이 23일때 까지만 출력하게 할 수 있다
WITH RECURSIVE dim_hour(n) AS (
SELECT
0
UNION ALL
SELECT
n + 1
FROM
dim_hour
WHERE
n < 23
)
SELECT
n as "HOUR"
FROM
dim_hour
;그 후 LEFT JOIN을 하느냐, 서브 쿼리 중에서 집계를 하느냐는 개인의 선택
WITH RECURSIVE dim_hour(n) AS (
SELECT
0
UNION ALL
SELECT
n + 1
FROM
dim_hour
WHERE
n < 23
)
SELECT
d.n as "HOUR"
, (
SELECT
count(*)
FROM
animal_outs
WHERE
HOUR(datetime) = n
-- 여기서 n 대신 HOUR도 가능
) as "cnt"
FROM
dim_hour d
;