데이터를 보다보면 결측치 외에도 중복값이 나타날 때가 있다
이를 확인할 때는 nunique() 등을 사용할 수 있는데, 때로는 그 중복값에 어떤 내용이 들어있는 지 확인할 필요가 있다.
duplicated는 중복값을 제거할 때는 물론, 옵션을 통해 중복값의 내용을 확인할 때도 확인할 수 있다.
duplicated의 작동 방식
duplicated는 입력된 기준을 통해 이와 중복되는지 여부를 판단하고 boolean 데이터의 series를 반환한다
특정 데이터가 전체 데이터 내에서 중복한다면 True, 고유하다면 False를 반환하는 것이다
duplicated의 파라미터
DataFrame.duplicated(subset, keep)
duplicated 메서드는 위와 같이 subset과 keep이라는 옵션을 같는다

subset
subset은 중복을 판단하는 기준 컬럼을 지정해주는 옵션이다
1개는 물론 여러 컬럼을 기준으로 정해주면, 이들 컬럼에 대해서만 중복 여부를 판단한다
default는 None으로, 입력하지 않는다면 전체 컬럼에 대해서 중복을 확인한다
keep
keep은 중복된 값을 어떻게 처리할 지 지정해주는 옵션이다.
그 내용으로 'first', 'last', False를 갖는다
keep='first'
해당 옵션의 default값으로, 중복값 중 첫번째로 나온 값을 반환한다
keep='last'
중복값 중 마지막으로 나온 값을 반환한다
keep=False
위 케이스들과 다르게, 중복되는 값들 전체에 대해 무조건 True를 반환한다
중복값 확인하기
keep=False 옵션을 사용하면 전체 데이터 중 '중복이 존재하는 데이터'만을 조회할 수 있다
# 중복된 ('Artist Name', 'Track Name') 조합을 모두 포함하는 필터링
duplicated_songs = song_df[song_df.duplicated(subset=['Artist Name', 'Track Name'], keep=False)]
# 그 후 정렬
duplicated_songs_sorted = duplicated_songs.sort_values(by=['Artist Name', 'Track Name'])
# 결과 확인
duplicated_songs_sorted.head(10)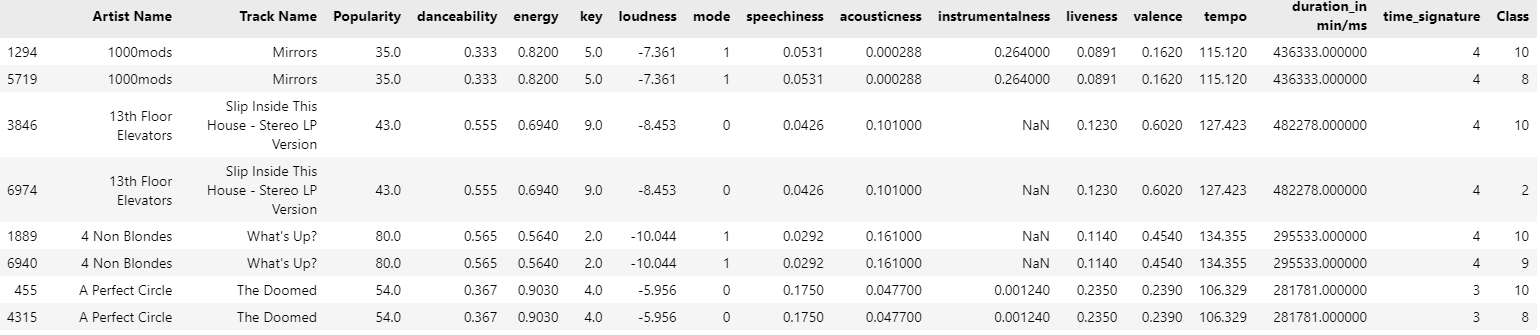
해당 케이스의 경우 중복되는 row들을 찾은 뒤 그 class를 비교해야 하는 경우였는데,
duplicated와 sort_values를 통해서 중복값들을 모아놓고 어떤 Class에 들어있는 지 확인할 수 있게 해준다
참고 링크
[Python pandas] 중복값 확인 및 처리 : DataFrame.duplicated(), DataFrame.drop_duplicates(), keep='first', 'last', False
[Python] 데이터 정렬 (sort, arrange) : DataFrame.sort_values(), sorted(), list.sort()
