최종 프로젝트를 위해 레딧의 글을 크롤링할 필요가 있었다.
셀레니움으로 동적 크롤링을 실행할까 하다가, 레딧 api로 크롤링을 할 수 있다는 것을 알게 되어 이를 위한 코드를 작성해보았다.
참고: praw로 레딧 크롤링하기
감사합니다감사합니다감사합니다감사합니다감사합니다
레딧 개발자 계정 등록
우선 레딧 API에 앱을 등록하고 개발자 계정을 만들어야 한다.
위 글 또는 아래 글들을 참고해서 진행하자.
Reddit API로 게시글 가져오기
Reddit 데이터 수집하기 using API (PYTHON)
필요 라이브러리 가져오기
import pandas as pd
from dotenv import load_dotenv
import os
import requests
from requests.auth import HTTPBasicAuth
import json
import praw
import time
from datetime import datetime, timezone
from tqdm import tqdm필요 정보 가져오기: .env
그냥 코드에 바로 입력하기에는, 내 레딧 id와 비밀번호 등 개인정보가 입력되어 부담스러울 수 있다.
.env를 사용하면 별도의 파일을 만들고 거기에 개인정보를 입력하여 받아올 수 있다.
def get_dotenv():
load_dotenv(verbose=True)
client_id = os.environ.get("client_id")
client_secret = os.environ.get("client_secret")
reddit_username = os.environ.get("REDDIT_ID")
reddit_password = os.environ.get("REDDIT_PW")
my_appname = os.environ.get("APP_NAME")
return client_id, client_secret, reddit_username, reddit_password, my_appname
client_id, client_secret, reddit_username, reddit_password, my_appname = get_dotenv() 레딧 정보 받아오기
def get_reddit(client_id, client_secret, user_agent, username, password):
reddit = praw.Reddit(
client_id = client_id
, client_secret = client_secret
, user_agent = user_agent
, username = username
, password = password
)
return reddit
reddit = get_reddit(client_id, client_secret, my_appname, reddit_username, reddit_password)원하는 서브레딧 글 받아오기
앞서 받아놓은 reddit에 원하는 서브레딧 이름을 넣어서 글을 긁어올 수 있다
우리 프로젝트는 통신사 데이터를 다루므로 'telecom' 서브레딧의 글을 가져오기로 했다.
def craw_subreddit(reddit, subreddit_name):
reddit_list = []
subreddit = reddit.subreddit(subreddit_name)
# tqdm으로 서브미션 진행 상황 표시
for submission in tqdm(subreddit.new(limit=None), desc="Crawling submissions"):
submission.comments.replace_more(limit=None)
comments = submission.comments.list()
# tqdm으로 댓글 진행 상황 표시
for comment in tqdm(comments, desc="Processing comments", leave=False):
reddit_list.append([comment.created_utc, comment.body])
time.sleep(0.001)
return reddit_list
subreddit_name = 'telecom' # Input name of subreddit you want to crawl
subreddit_list = craw_subreddit(reddit, subreddit_name)이렇게 받아온 데이터는 아래와 같다.
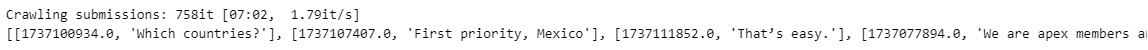
리스트에 리스트가 들어있는 형태이고, 각각 [[시간, 글]] 형태로 들어있다.
우선 시간 데이터가 timestamp 형태라 변환이 필요하다
또한 리스트에 담겨있기 때문에 이후 분석에 용이하도록 df로 변환할 필요가 있다
pd.DataFrame 형태로 변환
def list_to_df(to_be_list):
reddit_df = pd.DataFrame(to_be_list)
reddit_df = reddit_df.rename({
0 : 'UTC'
, 1 : 'reddit'
}, axis=1)
return reddit_df
reddit_df = list_to_df(subreddit_list)
def timestamp_to_utc(unix_utc):
readable_time = datetime.fromtimestamp(unix_utc, tz=timezone.utc) # atetime.datetime.utcfromtimestamp()
return readable_time
reddit_df['UTC'] = reddit_df['UTC'].apply(timestamp_to_utc)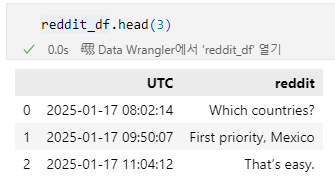
드디어 익숙한 형태로 데이터가 정제되었다.
저장
이제 추후 자연어 처리에 쓰든 어디에 쓰든 csv 파일을 불러와 사용할 수 있도록
준비된 DataFrame을 저장하도록 하자.
def save_to_csv(df):
today = datetime.now().strftime('%y%m%d')
reddit_df.to_csv(f'subreddit_df_{today}.csv')
save_to_csv(reddit_df)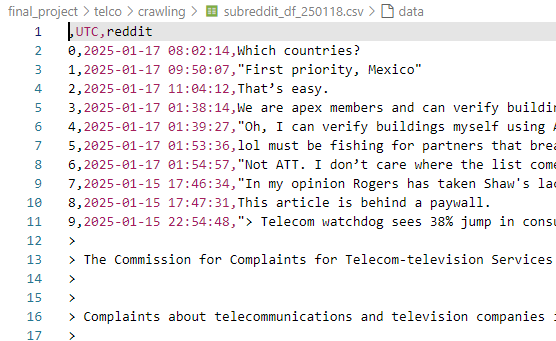
번외
token 발급 받기
앞서 가져온 계정 정보를 통해 api token을 발급 받을 수 있다.
def get_access_token(user_name, password, user_agent, client_id, client_secret):
# response_auth용 파라미터
params = {
'grant_type' : 'password'
, 'username' : user_name
, 'password' : password
}
# POST 요청 헤더
headers_auth = {
'User-Agent' : user_agent
}
# HTTP Basic 인증 (client의 name과 password 사용)
auth = HTTPBasicAuth(client_id, client_secret)
response_auth = requests.post(
'https://www.reddit.com/api/v1/access_token'
, headers = headers_auth
, data= params
, auth= auth
)
if response_auth.status_code == 200:
token_data = response_auth.json()
print(f"Access token : {token_data}")
access_token = token_data['access_token']
else:
print(f"Error! {response_auth.status_code}\n{response_auth.text}")
exit()
return access_token
access_token = get_access_token(reddit_username, reddit_password, my_appname, client_id, client_secret)헤더 설정
이하 2개의 코드에서 사용할 헤더를 미리 입력 해주겠다
# API 요청 헤더
headers_api = {
'Authorization' : f'Bearer {access_token}'
, 'User-Agent' : my_appname
}내 정보 확인
.env에서 가져온 user 정보를 통해 해당 user의 info를 받아볼 수 있다
def check_user_info(url, headers):
# 내 정보 보기
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(f"User info: {response.json()}")
else:
print(f"Error! {response.status_code}\n{response.text}")
url_me = 'https://oauth.reddit.com/api/v1/me'
check_user_info(url_me, headers_api)Best 글 확인
내 계정에서 JOIN 되어있는 서브레딧 기준으로 best 글을 가져오는 것으로 보인다
def best_reddits(url, headers):
# Best 글 보기
response = requests.get(url, headers=headers)
if response.status_code == 200:
best_json = response.json()
print("Best posts:")
print(json.dumps(best_json, indent=4))
else:
print(f"Error! {response.status_code}\n{response.text}")
return best_json
url_best = 'https://oauth.reddit.com/best'
response_best = best_reddits(url_best, headers_api)