92번. Average Selling Price
Write a solution to find the average selling price for each product. average_price should be rounded to 2 decimal places. If a product does not have any sold units, its average selling price is assumed to be 0.
(링크)
데이터 이해
Price 테이블
(product_id, start_date, end_date)의 복합 PK
start_date부터 end_date까지 product_id의 price를 나타냄
product_id들의 periods에 중복overlapping은 없음
UnitsSold 테이블
product가 팔린 데이터
중복값 존재함
풀이 구상
평균 판매가니까, price * units(=quantity)들의 합산을 구하고 이를 total_untis로 나눠주면 될 듯
하지만 먼저 팔린 적이 없는 제품들의 ID가 필요할 것 => prices LEFT JOIN unitssold를 진행해서, unitssold의 product_id가 null인 애들을 먼저 찾아야겠다
이 ID들은 0을 주고, 나머지는 위에서 구상한 평균 판매가로 구하면 될 듯
- Prices와 UnitsSold를 LEFT JOIN해서 팔린 기록이 없는 product_id를 반환 (WITH문 사용), 추후 이 product_id들은 tot_sales = 0로 넣을 예정
- Prices와 UnitsSold를 INNER JOIN하여 p.price * u.units = tot_sales를 계산 (WITH문 사용)
- 계산된 tot_sales를 product_id로 그룹핑해서 average를 계산 (as ‘average_price’)
- 1과 3를 UNION해서 결론 도출 (위 1~3동안 컬럼은 product_id, average_price만 남겨놓기)
코드 작성
- 팔린 기록이 없는 제품들의 product_id를 반환하고, 이들의 average_price = 0으로 반환
WITH not_sold AS ( SELECT p.product_id , 0 as 'average_price ' FROM prices p LEFT JOIN unitssold u ON p.product_id = u.product_id WHERE u.product_id IS NULL ), #미완료 코드. 조회하려면 메인쿼리 작성 필요 - 판매기록이 있는 제품들의 tot_sales를 계산하기
WITH not_sold AS (
SELECT
p.product_id
, 0 as 'average_price '
FROM
prices p
LEFT JOIN unitssold u
ON p.product_id = u.product_id
WHERE
u.product_id IS NULL
),
tot_sales AS (
SELECT
p.product_id
, p.price * u.units as 'tot_sales'
FROM
prices p
INNER JOIN unitssold u
ON p.product_id = u.product_id
)
SELECT
*
FROM
tot_sales
;문제 발생.
UnitsSold 테이블에는 동일 product_id에 대해 여러 판매 기록이 존재하다보니, 결과값이 내 의도보다 늘어나서 추출됨
pruchase_date가 start_date와 end_date 사이에 있도록 조건을 걸어줄 필요가 있음
WITH not_sold AS (
SELECT
p.product_id
, 0 as 'average_price '
FROM
prices p
LEFT JOIN unitssold u
ON p.product_id = u.product_id
WHERE
u.product_id IS NULL
),
tot_sales AS (
SELECT
p.product_id
, p.price * u.units as 'tot_sales'
FROM
prices p
INNER JOIN unitssold u
ON p.product_id = u.product_id
WHERE 1=1
AND (start_date <= purchase_date)
AND (purchase_date <= end_date)
)
SELECT
*
FROM
tot_sales
;- tot_sales를 product_id로 그룹핑해서 avg 계산하기
방금 2번에서 계산했던 코드를 그대로 활용해서 group by가 되는 지 테스트
WITH not_sold AS (
SELECT
p.product_id
, 0 as 'average_price '
FROM
prices p
LEFT JOIN unitssold u
ON p.product_id = u.product_id
WHERE
u.product_id IS NULL
),
tot_sales AS (
SELECT
p.product_id
, sum(p.price * u.units) as 'tot_sales'
, sum(u.units) as 'sum_units'
, round(sum(p.price * u.units) / sum(u.units), 2) as 'average_price '
FROM
prices p
INNER JOIN unitssold u
ON p.product_id = u.product_id
WHERE 1=1
AND (start_date <= purchase_date)
AND (purchase_date <= end_date)
GROUP BY
p.product_id
)
SELECT
*
FROM
tot_sales
;- 이왕이면 UNION 말고 JOIN으로 합해보자
SELECT
p.product_id
, CASE
WHEN u.product_id IS NULL THEN 0
ELSE round(sum(p.price * u.units) / sum(u.units), 2)
END as 'average_price'
FROM
prices p
LEFT JOIN unitssold u
ON p.product_id = u.product_id
WHERE 1=1
AND (start_date <= purchase_date)
AND (purchase_date <= end_date)
GROUP BY
p.product_id
;하지만 정답이 아니었다
일부러 LEFT JOIN을 했는데, 어째서인지 Output에는 이게 적용되지 않았다
- 판매 기록이 없는 제품들을 표시하기 (UNION 회귀)
결국 UNION밖에 답이 없는걸까?
최종안
(
SELECT
p.product_id
, CASE
WHEN u.units IS NULL THEN 0
ELSE round(sum(p.price * u.units) / sum(u.units), 2)
END as 'average_price'
FROM
prices p
LEFT JOIN unitssold u
ON p.product_id = u.product_id
WHERE 1=1
AND (start_date <= purchase_date)
AND (purchase_date <= end_date)
GROUP BY
p.product_id
)
UNION
(
SELECT
p.product_id
, 0 as 'average_price '
FROM
prices p
LEFT JOIN unitssold u
ON p.product_id = u.product_id
WHERE
u.product_id IS NULL
)
;93번. Project Employees I
Write an SQL query that reports the average experience years of all the employees for each project, rounded to 2 digits.
(링크)
구상
두 테이블을 employeeid로 조인
Group by project_id
Select는 project_id, avg(experience_year)
코드 작성
SELECT
p.project_id
, round(avg(e.experience_years),2) as 'average_years'
FROM
project p
INNER JOIN employee e
ON p.employee_id = e.employee_id
GROUP BY
p.project_id
;대장균 Lv1: 특정 형질을 가지는 대장균 찾기
2번 형질이 보유하지 않으면서 1번이나 3번 형질을 보유하고 있는 대장균 개체의 수(COUNT)를 출력하는 SQL 문을 작성해주세요. 1번과 3번 형질을 모두 보유하고 있는 경우도 1번이나 3번 형질을 보유하고 있는 경우에 포함합니다.
(링크)
데이터 이해 및 분석
문제에서 요구하는 건 ‘2번 형질을 보유하지 않을 것’과 ‘적어도 1번과 3번 형질 중 하나 이상을 보유할 것’
이 형질은 GENOTYPE 컬럼에 들어있는데,
문제는 이걸 2진수로 기록하고 있다는 점이다.
SQL에서 2진수는 conv() 함수로 표현할 수 있다 (구글링은 신이야)
conv(컬럼명, 본래표현법, 변경한표현법)
SELECT
id
, conv(genotype, 10, 2) as 'geno'
FROM
ecoli_data
;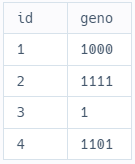
위의 예시에서, id=1인 경우는 True-False-False-False, 즉 4번 형질만 갖고 나머지 형질은 없는 경우이다.
코드 작성
가장 먼저 떠오른 방법은 substr로 각각의 자리수를 떼어내 True-False로 따지는 것
id 3 같이 0001이 아닌 1로 표시되는 값들 때문에 이게 어렵다고 생각하고 포기하려던 찰나
python에선 슬라이싱을 할 때 음수를 넣으면 뒤에서부터 자를 수 있었다
그렇다면 substr() 함수도 뒤에서부터 잘라올 수 있지 않을까?
SELECT
substr(geno, -1, 1) as 'str1'
, substr(geno, -2, 1) as 'str2'
, substr(geno, -3, 1) as 'str3'
, substr(geno, -4, 1) as 'str4'
FROM (
SELECT
id
, conv(genotype, 10, 2) as 'geno'
FROM
ecoli_data
) aa
;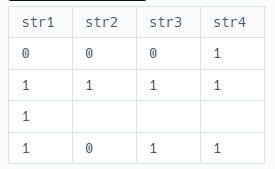
여기까지 왔으면 정답은 다 도출했다고 봐도 될 것 같다.
지금까지 작성한 코드를 WITH문으로 묶어주고,
조건문으로 (str2=0) and ((str1=1) or (str3=1))를 걸어주면 끝
최종안
WITH geno_binary AS (
SELECT
id
, substr(geno, -1, 1) as 'str1'
, substr(geno, -2, 1) as 'str2'
, substr(geno, -3, 1) as 'str3'
, substr(geno, -4, 1) as 'str4'
FROM (
SELECT
id
, conv(genotype, 10, 2) as 'geno'
FROM
ecoli_data
) aa
)
SELECT
count(id) as 'count'
FROM geno_binary
WHERE
(str2 = 0)
AND ((str1 = 1)
OR(str3 = 1))
;