문제
N개의 정수 A[1], A[2], …, A[N]이 주어져 있을 때, 이 안에 X라는 정수가 존재하는지 알아내는 프로그램을 작성하시오.
입력
첫째 줄에 자연수 N(1≤N≤100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], …, A[N]이 주어진다. 다음 줄에는 M(1≤M≤100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들이 A안에 존재하는지 알아내면 된다. 모든 정수의 범위는 -231 보다 크거나 같고 231보다 작다.
출력
M개의 줄에 답을 출력한다. 존재하면 1을, 존재하지 않으면 0을 출력한다.
예제 입력 1
5
4 1 5 2 3
5
1 3 7 9 5예제 출력 1
1
1
0
0
1내코드
import hashlib
N = int(input())
a = input().split()
M = int(input())
b = input().split()
hash_table = dict()
for i in a:
encoded_i = i.encode()
key = hashlib.sha256(encoded_i).hexdigest()
hash_table[key] = i
for i in b:
encoded_i = i.encode()
key = hashlib.sha256(encoded_i).hexdigest()
try:
if hash_table[key]:
print(1)
except:
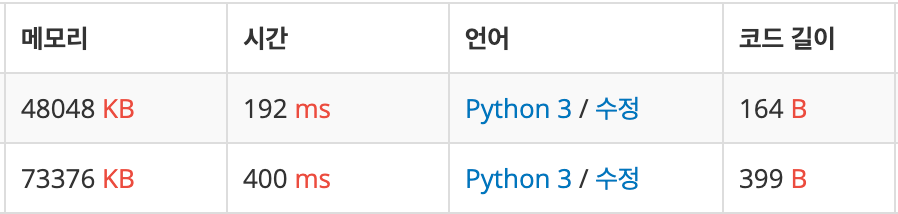
print(0)해시 문제래서 일단 해시를 썼고 테스트를 통과했다.
사실 처음에 문제를 보고 어 이거 파이썬은 너무 간단한데?하고 다음과 같이 코드를 제출했었다. 그리고 시간초과라는 결과가 나왔다.
N = int(input())
a = list(map(int, input().split()))
M = int(input())
b = list(map(int, input().split()))
for i in b:
if i in a:
print(1)
else:
print(0)이 문제에서는 N과 M이 모두 100,000까지 가능하고 보기에는 시간복잡도가 O(N)으로 보였기 때문이다. 하지만 결과가 시간 초과로 나오길래 그냥 해시 테이블을 직접 만들어서 통과를 했다.
다른 답안
나동빈님의 패캠 알고리즘 강의에서 나온 답안이다.
N = int(input())
a = set(map(int, input().split()))
M = int(input())
b = list(map(int, input().split()))
for i in b:
if i in a:
print(1)
else:
print(0)위의 답안과 아주 비슷하지만 a가 list가 아니라 set이다. set은 list보다 메모리를 덜 차지한다고 알고 있었는데 처리 속도에도 확연히 차이가 나는걸까?
찾아보았더니 이유는 다음과 같았다.
set에서 in, not in의 시간 복잡도는 O(1)이고
list에서 in, not in의 시간 복잡도는 O(N)이라고 한다.
그렇기 때문에 for문 안에 있을때 O(N^2)이므로 시간 초과가 발생했던 것이었고 set으로 바꾸면 O(N)으로 시간 내로 처리가 가능한 것이다.
해시를 직접 구현했을 때보다도 더 처리 속도가 빠르고 메모리도 적게 사용한다.
[참고]
