
머신러닝 심화
라고 쓰고 사실상 간단하게 하는 EDA 실습이라 읽는다...
예측모델링 프로세스
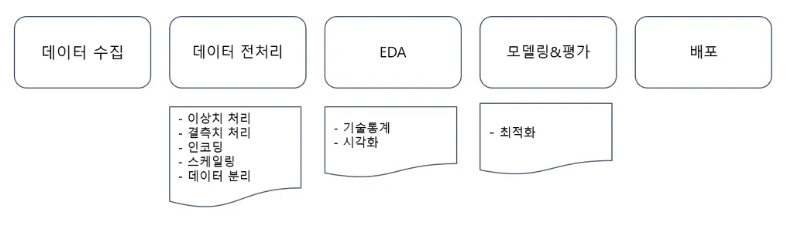
전체적인 프로세스 개요
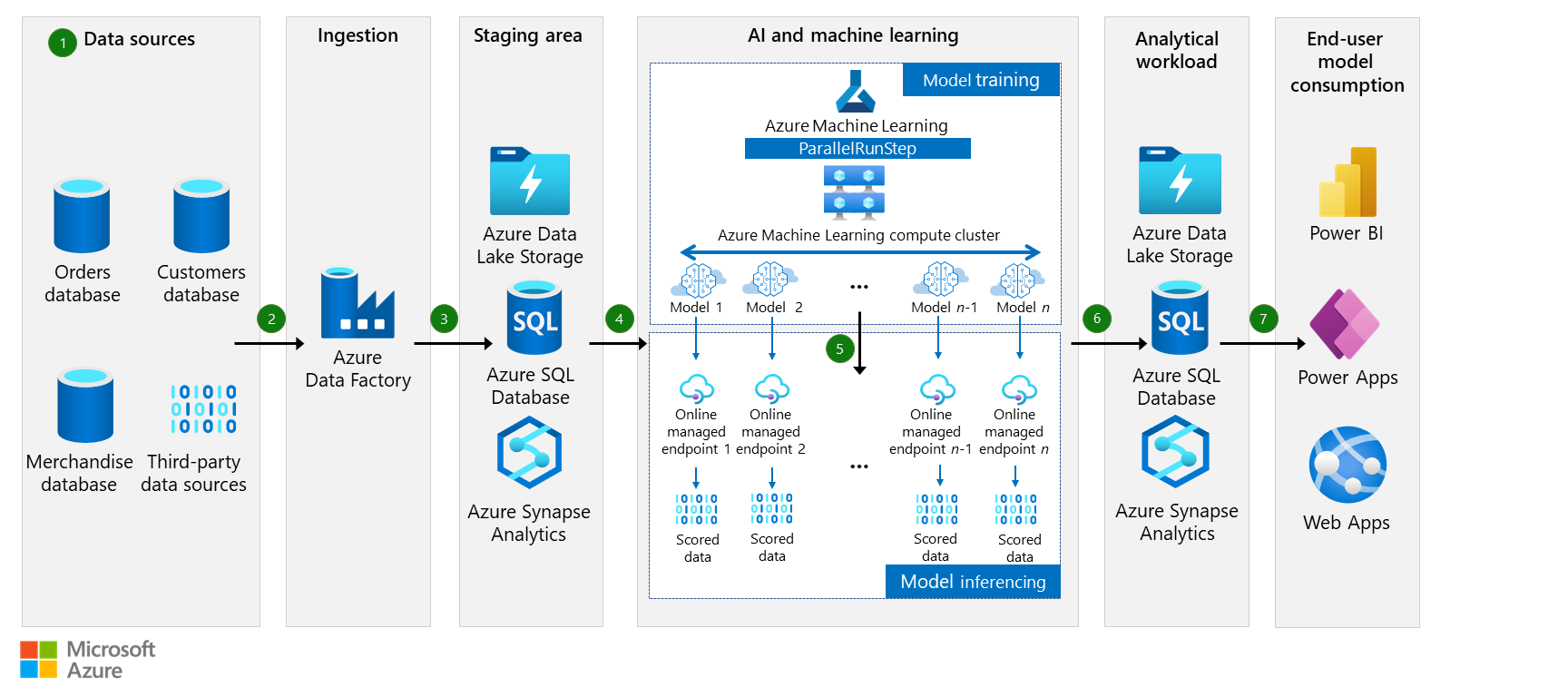
출처: Microsoft
조금 더 상세히 보자면 이런 너낌?
⭐️0. 문제 정의
데이터 수집 전 선행되어야 하는 가장 중요한 단계이다.
- 목적 설정
예측하려는 목표 변수와 문제의 범위를 명확히 정의 - 비즈니스 목표와 연결
예측 결과가 비즈니스에 어떤 영향을 미칠지 결정 - 출력 형태 정의
출력 형태(예측 -> 단일 값, 확률 값, 시간 단위별 등)
1. 데이터 수집
🤔데이터는 어디서 수집하나요
수집은 사실상 데이터 엔지니어의 일이긴하지만,
어쩔 수 없이 데이터 분석가가 해야하기도 하다....
- 데이터 원천
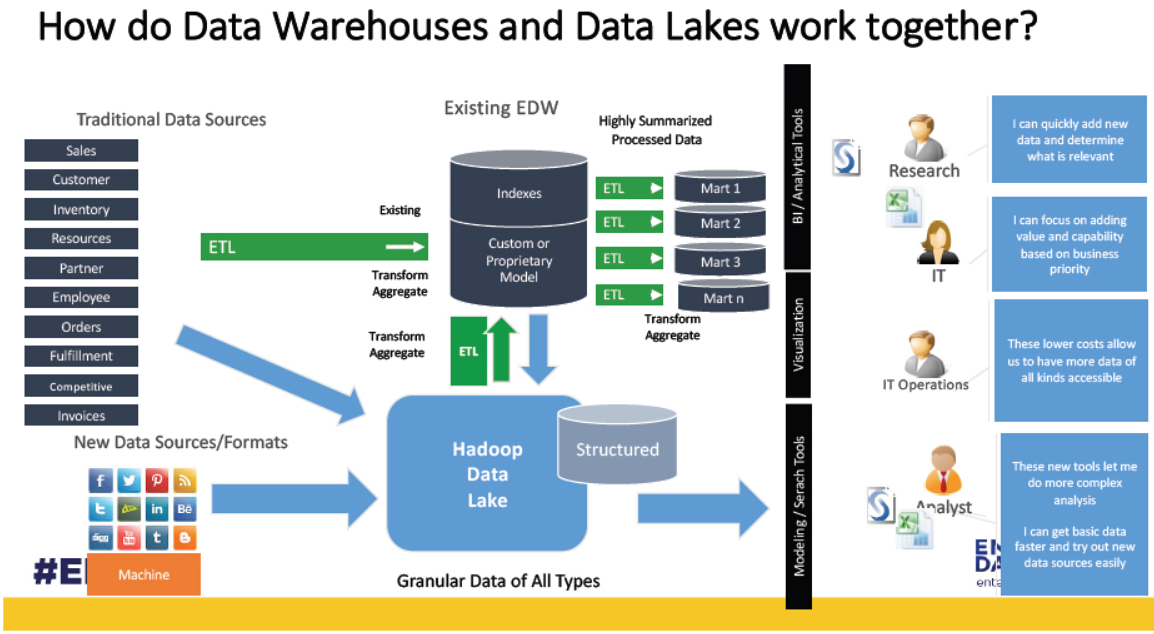
출처: 블로그
1) 내부 시스템: 데이터베이스, 로그 파일 등
2) 외부 데이터: API, Crawling, 제3자 데이터 등
- 데이터 종류
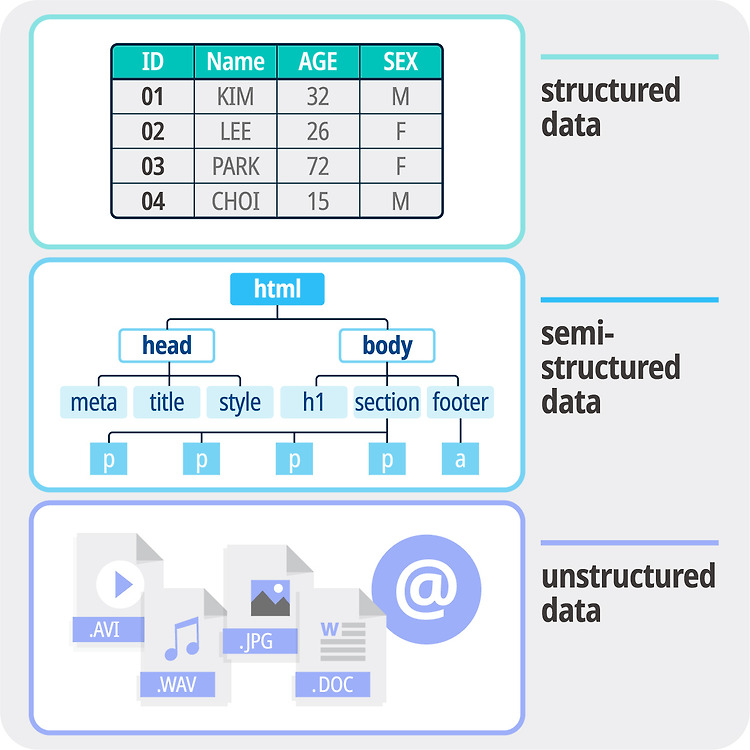
출처: 블로그
1) 구조화된 데이터 (스프레드시트 형태)
정형 데이터와 같은 말로 흔히 우리가 알고있는 테이블 형식(행/열)로 이루어진 데이터
2) 비구조화된 데이터(이미지, 텍스트, 비디오 등)
비정형 데이터와 같은 말로 테이블 형식으로 담을 수 없는 텍스트, 이미지, 동영상 등
2. 데이터 전처리
가장 시간이 오래 걸리는 단계
데이터를 분석하기 위해 보기 좋게/ 원하는 형태로 가공하는 단계
- 이상치, 결측치 처리, 인코딩, 스케일링, 데이터 분리
3. EDA
탐색적 데이터 분석이라는 뜻으로 기술통계, 시각화를 통해 데이터를 이해하고 탐구하는 단계
데이터 분석을 하기 전 구조, 분포 등 파악
- 기술통계(추론 통계), 시각화(그래프, 플롯 등 활용)
4. 모델링 & 평가
- 모델 선택
예측 문제의 특성에 맞는 모델을 선택 (선형, 신경망 등) - 모델 학습
훈련 데이터를 사용하여 모델 학습(지도, 비지도, 강화 학습) - 성능 지표
문제 유형에 따라 적절한 지표 사용(회귀: MSE, , 분류: 정확도, F1-Score etc.) - 테스트 데이터 평가
훈련된 모델을 테스트 세트로 평가(예시로 평가) - 오류 분석
모델의 예측 오류 사례 분석 -> 원인 파악 - 모델 최적화
모델 성능(러닝타임 단축, CPU,GPU이용 최소화)을 위해 매개변서 최적화
5. 배포
- 배포
모델 -> 실제 환경에 적용 - 운영 및 모니터링
모델 성능을 지속적으로 추적
SQL, Python, Code Kata