
Classification(분류) 알고리즘
자세한 참고는 블로그
분류 알고리즘이란?
머신러닝의 지도학습에 대표적인 유형 중 하나로 Classification = 분류 라고 불린다.
분류는 주어진 데이터를 클래스 별로 구별해 내는 과정으로 다양한 분류 알고리즘을 통해 데이터와 데이터의 레이블 값을 학습시키고 모델을 생성한다. 입력 데이터(X)와 정답(y)를 먼저 알려주고 학습 시킨다.
새로운 데이터가 주어졌을 때 학습된 모델을 통해 어느 범주에 속한 데이터인지 판단하고 예측하게 된다.
📍데이터가 어떤 범주에 속하는지 알고리즘이 학습된 모델을 가지고 분류 하는 것
분류 알고리즘 종류
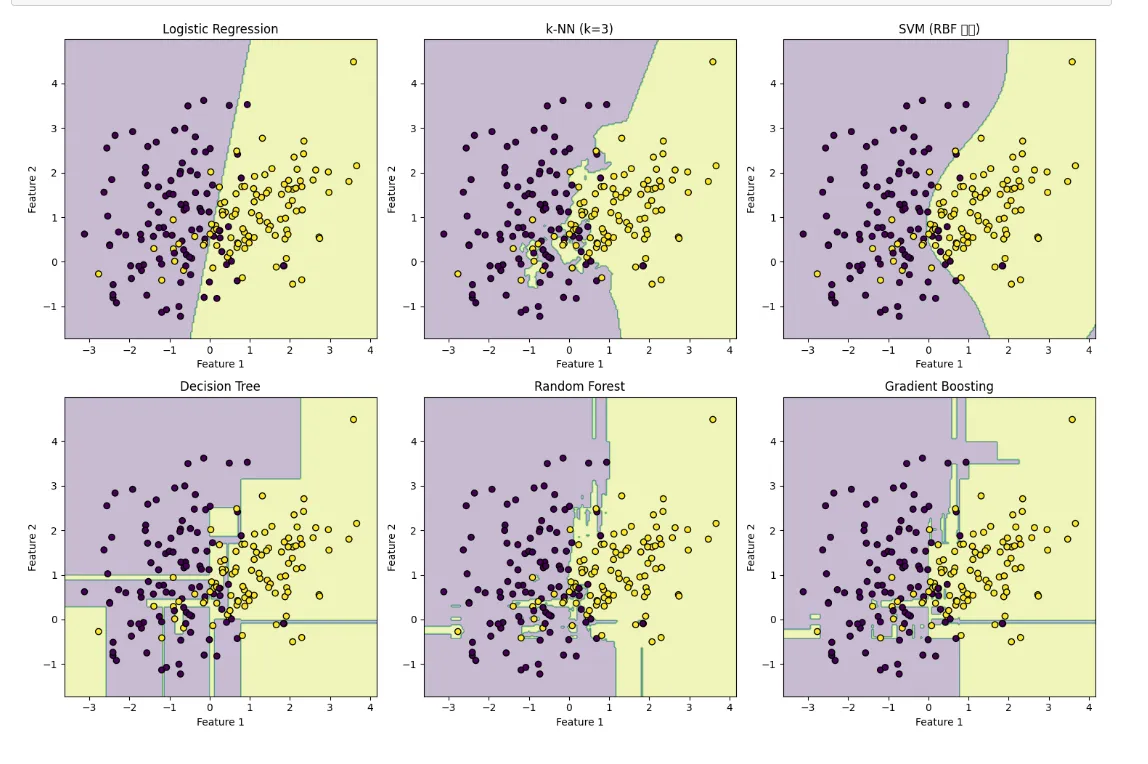
간략히 보는 6개의 다양한 분류 알고리즘!!
1. Logistic Regression (로지스틱 회귀)
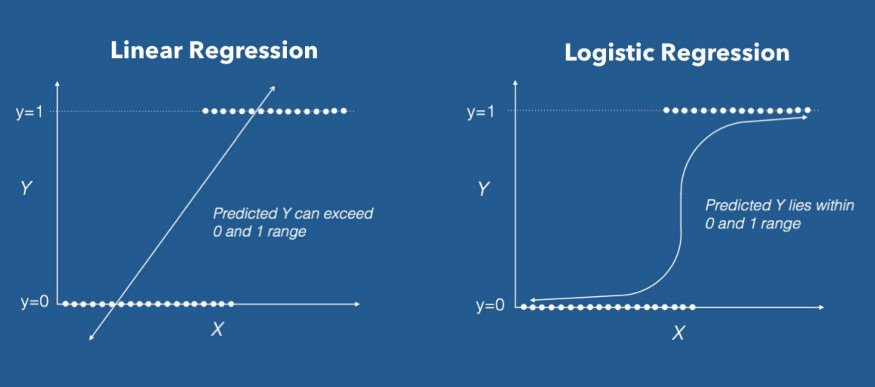
출처: 블로그
- 선형 모델의 일종으로, 시그모이드 함수를 통해 출력값(0~1 사이 확률)을 계산
- 데이터가 선형적으로 구분 가능할 때 빠르고 해석이 쉬움
- 이름에 회귀라는 단어가 종종 회귀 분석에만 사용될 것처럼 헷갈리곤 하지만 범주형 자료를 분류하는데 매우 강력한 알고리즘
- 독립변수와 종속변수의 선형 관계성을 기반으로 만들어짐
2. k-Nearest Neighbors (k-NN)
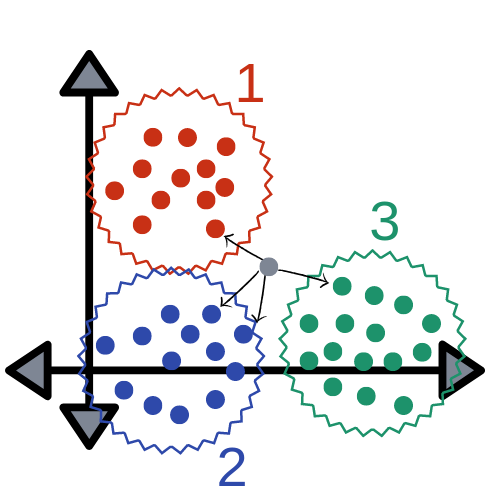
출처: 블로그
- 거리(유클리드 거리 등)에 기반하여 가장 가까운
k개의 이웃의 클래스를 보고 다수결로 분류 - 단순하지만, 데이터가 많거나 차원이 높은 경우 느릴 수 있음
- K가 짝수일 경우 범주 내의 데이터가 같아져서 분류가 불가능한 상황이 올 수 있기 때문에 K는 홀수로 정하는것이 좋음
3. Support Vector Machine (SVM)
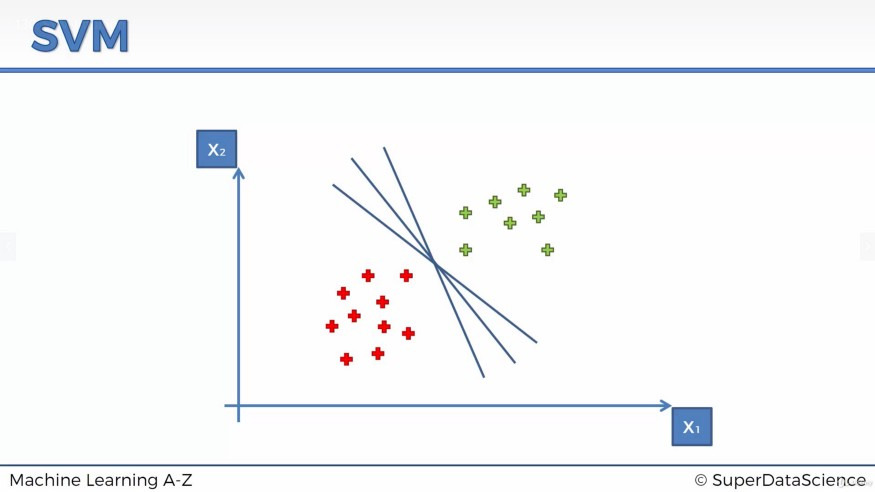
출처: 블로그
- 마진을 최대로 하는 결정 경계를 찾아 분류
- 고차원, 복잡한 데이터에도 잘 작동하지만, 파라미터(C, 커널 등) 튜닝이 중요
- 주어진 데이터들을 분류하는 최적의 결정경계(Decision Boundary)를 찾는것
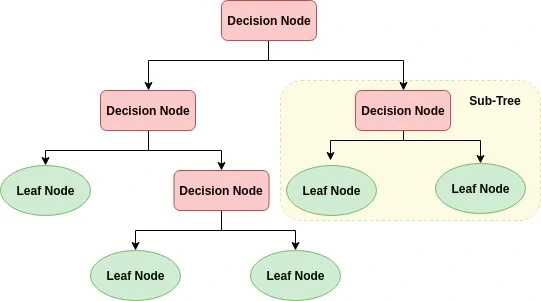
4. Decision Tree / Random Forest
출처: 블로그
- 결정 트리는 데이터의 특성(컬럼)을 기준으로 분할하며 분류
- 랜덤 포레스트는 여러 결정 트리를 앙상블(보팅)하여 과적합을 방지하고 성능을 높임
- Decision Tree 모델은 이해와 해석이 용이하여 알아보기가 쉽고 예측속도와 성능이 좋음
- 하지만 주어진 데이터의 특성에만 치중하면 Overfitting이 발생하기 쉽기 때문에 그에 대한 대처가 필요합니다.
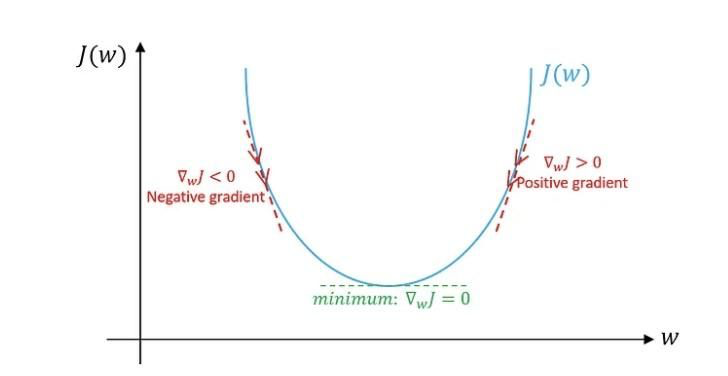
5. Gradient Boosting (XGBoost, LightGBM 등)
출처: 블로그
- Decision Tree를 약한 학습기로 사용해 에러를 점진적으로 줄여나가는 부스팅 방법
- 해커톤 등에서 강력한 성능을 자주 보여 인기 많음
- 그라디언트(Gradient) + 부스팅 (Boosting) : "잔차를 줄여간다 = 그라디언트(기울기)를 줄여간다"
6. Naive Bayes (나이브 베이즈)
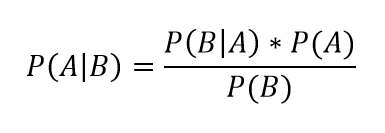
출처: 블로그
- 독립 변수 간의 독립성을 가정한 확률 기반 알고리즘
- 텍스트 분류와 같은 특정 도메인에서 효과적임
- 각 클래스에 속할 특징 확률을 계산하는 조건부 확률을 기반으로한 분류 방법
SQL, Python, Code Kata