주제 선정
이번 프로젝트는 머신러닝과 통계학을 이용한 프로젝트로, 주로 머신러닝 학습 모델을 만들어 최적화된 모델을 만드는 것이 목적이다.
그래서 머신러닝의 가장 큰 지도학습, 비지도학습, 강화학습이 있지만, 학습 방법 말고도 주제를 나누어 보자면 총 3가지의 주제로 나누어진다.
- 분류, 군집, 회귀
분류는 말 그대로 학습한 데이터를 가지고 1과 2 또는 10개 중 1,2개를 찾아내서 분리하는 것이다.
군집은 비슷한 특성을 가진 그룹끼리 묶는 것을 얘기하는데, 몇개의 집단(클러스터)으로 어떤 기준으로 그룹을 묶을 것인지가 중요하다.
회귀는 예측을 하는 모델인데, 그동안의 수집된 데이터를 바탕으로 패턴을 학습하여 앞으로의 일이나 어떤 특정 케이스에 대한 결과를 예측하는 것이다.

그래서 분류, 군집, 회귀 이렇게 총 3가지의 큰 주제로 나누고 각각 2개의 주제가 있어 총 6가지의 주제가 주어졌다.
우리는 각자 데이터를 조금씩 본다음 회의를 하기로 했고, 그 후 회의했는데 비슷하게 스포티파이가 재미있어 보인다고 했지만.. 근데 군집에 대한건 다들 꺼려하는 분위기 였기 때문에 고민을 많이 했다.
그래서 결국 2가지까지 추렸는데 분류에서 2가지 중 한가지를 선택하는 것이었다.
은행도 컬럼도 괜찮고 수치형 데이터가 정말 많아서 분석을 해보기는 쉽겠지만, 그 후 나올 수 있는 인사이트가 비즈니스나 액션 플랜 보다는 너무 마케팅에 치중되어있는 느낌이었다. 확실히 내가 생각해도 비즈니스캔버스를 새로 짜는것이 아니라면 나올 수 있는 인사이트의 한계가 분명하다고 생각했다.
다시 그 두가지를 고민해보고 선택한 결과 부동산을 해보기로 했다. 다들 쉽지 않을 것이라 생각했지만 허위매물을 판별하는 부분과 데이콘의 대회에 직접 참여해서 우리도 제출한다는 그 부분을 마음에 들어해서 골랐다고 했다.
결론: [분류] 부동산 허위매물 분류로 결정 🤗
기획안 선정
기획안은 우리가 간략하게 짜고 튜터님께 찾아갔는데 기획안이니까 그렇게 제출해도 괜찮다고 해주셔서
우리가 계획한 대로 일단 진행해보기로 했다.
그래서 우리의 기획안은
- 제목 : 랜덤포레스트 모델을 통한 부동산 허위매물 예측
- 프로젝트 목표 : 부동산 허위 매물로 인한 피해를 막기 위해 여러가지 머신러닝 분류 알고리즘 (Logistic Regression ,Random Forest, XGBoost 등) 익히고 적용하여 허위 매물을 예측하는 최적의 모델을 만든다.
- 프로젝트 핵심내용 : 데이터 전처리를 통해 데이터 클렌징을 수행한 후 먼저 기본적인 예측 모델을 만들고, 다양한 머신러닝 분류 알고리즘을 적용해본 후 기본 모델과 성능을 비교해서 더 나은 모델을 찾아본다. 이 과정에서 각 알고리즘을 특성에 따라 하이퍼파라미터를 조정해서 최적화 작업을 진행한다. 그리고 특징 중요도 분석을 통해 허위 매물 여부를 판단하는데 결정적인 역할을 하는 변수들을 파악해서 이에 대한 인사이트를 내고 허위 매물을 판별할 수 있는 가이드라인을 제시해본다.
이렇게 하기로 결정했다.
의외로 쉽게 결정되어서 살짝 놀랬다..ㅎ 하지만 그만큼 짜임새 있게 잘 짰다고 생각한다 :)
기타 일정
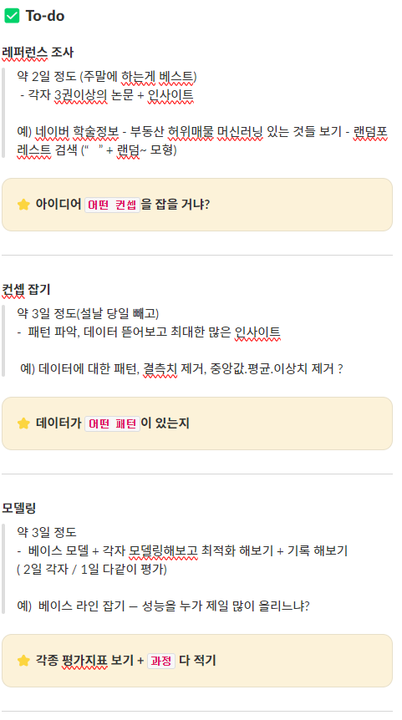
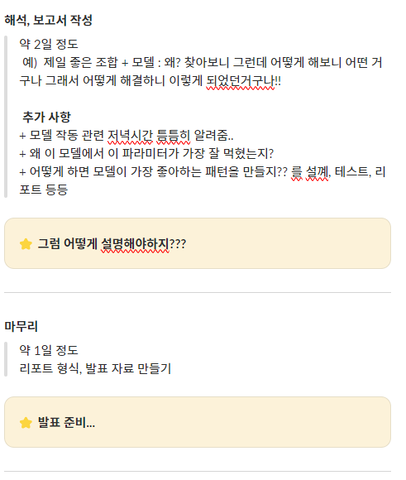
살려주세요🫠🫠🫠🫠🫠🫠
오늘치 끝!