웹 기반 스크래핑 시스템 구축 프로젝트라는 글을 통해 스크래핑 시스템을 구축한 경험을 공유한 바 있습니다. 이번에 소개할 RPA 프로젝트는 해당 시스템 구축의 연장선상에서 출발했습니다.
현재 회사에서 업무적으로 가장 큰 병목 현상은 바로 글로벌 시스템에 데이터를 입력하는 과정이었습니다. 대부분의 데이터 입력이 수작업으로 이루어져 있어, 업무 효율성이 떨어지고 직원들의 과도한 업무 부담과 잦은 휴먼 에러가 발생하는 문제점이 지속적으로 제기되었습니다.
이에 따라 업무 효율성을 높이고 직원들의 업무 부담을 덜기 위해, RPA(로봇 프로세스 자동화)를 도입하기로 결정했습니다.
하지만 글로벌 시스템에서는 공식적으로 데이터 연동 API나 자동화 도구를 제공하지 않았기 때문에, 처음부터 데이터를 자동화하는 과정이 쉽지 않았습니다. 저희는 브라우저 개발자 도구(Chrome DevTools 등)를 활용해 글로벌 시스템이 내부적으로 사용하고 있는 API 호출 방식을 직접 분석했습니다. 이 과정에서 요청 URL, Request 헤더, Payload 등 필요한 정보를 모두 DB화하여 자동화가 가능하도록 작업 환경을 구축했습니다.
RPA 시스템 구축 과정
RPA 프로젝트는 글로벌 시스템에서 공식적으로 데이터 연동을 지원하지 않았기 때문에, 브라우저의 개발자 도구를 통해 직접 API를 분석하는 작업에서 시작되었습니다.
1. Request와 Response 분석 및 정리
가장 먼저 진행한 작업은 자동화를 원하는 기능별로 브라우저 개발자 도구를 활용하여 API 호출 내용을 확인하는 것이었습니다.
아래는 실제 분석했던 예시입니다.
- Request 예시
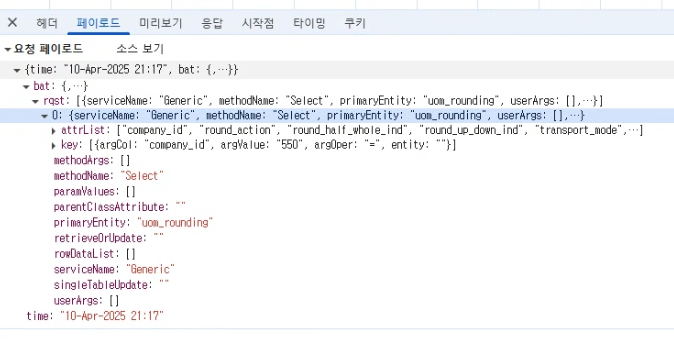
- Response 예시
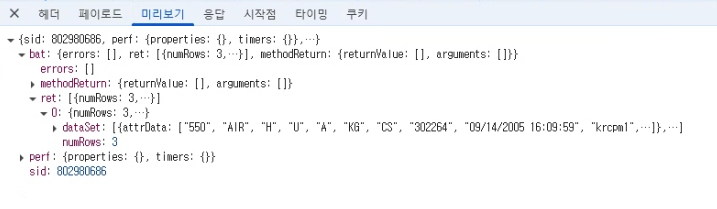
이렇게 각 기능의 요청과 응답 데이터를 명확하게 정리한 후, 필요한 데이터 구조를 파악할 수 있었습니다.
2. 응답 데이터를 기반으로 테이블 설계
정리된 API의 Response 데이터를 기반으로 총 23종의 테이블을 설계했습니다.
3. Node.js 기반 스크래핑 시스템 구현
실제 RPA 기능은 이전에 구축했던 웹 기반 스크래핑 시스템의 연장선으로, Node.js 환경에서 구현되었습니다. Axios와 같은 간단한 HTTP 요청 라이브러리만으로 구현하는 것도 가능했지만, 향후 CORS 정책 강화나 JavaScript 기반의 동적 콘텐츠 처리 등 예상하지 못한 환경 변화에 효과적으로 대비하기 위해 Puppeteer를 도입하였습니다.
4. 다양한 데이터 포맷 및 예외 처리
구현 과정에서 날짜 형식(예: yyyy/mm/dd, dd/mm/yyyy, yyyy-mm-dd)의 불일치, 숫자의 소수점 표현 차이 등 수많은 예외 상황이 발생했습니다.
이러한 이슈들을 해결하기 위해 정규 표현식과 포맷 변환 로직을 추가로 적용했으며, 다양한 예외 상황에 대비한 철저한 데이터 검증 로직을 추가했습니다.
이번 RPA 구축 경험을 통해 자동화의 중요성과 실제 적용 시 고려해야 할 다양한 문제점들을 깊이 이해할 수 있었습니다. 앞으로도 자동화 범위를 점차 확대해 나가며 업무 효율성을 지속적으로 높여갈 계획입니다.
이렇게 구축한 자동화 시스템은 부서별로 구체적인 기능을 구현하여 빠르게 업무에 적용했습니다. 주요 성과는 아래와 같습니다.
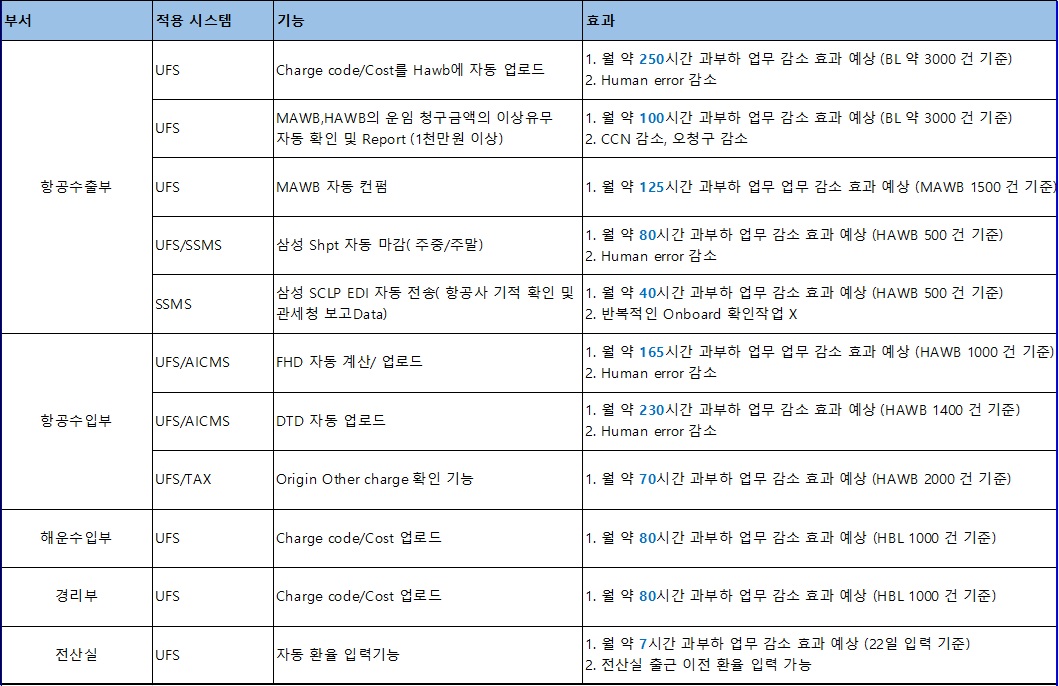
이와 같은 업무 자동화를 통해 저희 회사는 전체적으로 매월 약 1200시간의 업무 부담 감소 효과를 체감하고 있습니다. 이는 단순히 시간을 절약한 것에 그치지 않고, 반복적이고 지루한 작업에서 벗어나 직원들이 보다 창의적이고 중요한 업무에 집중할 수 있도록 환경을 마련한 데 큰 의미가 있습니다.
앞으로도 지속적인 업무 프로세스 분석을 통해 더욱 다양한 업무를 자동화하여 업무 효율성과 직원 만족도를 높여갈 계획입니다.
