서론
8월 1주차 회고 (21주차) - (8/4 - 8/8)
07/18 ~ 09/10 : 기업 참여 프로젝트(파이널 프로젝트)
08/04 : 산출물 작성
08/05 : 강사님 멘토링
08/06 : AI요약 기능 개발
08/07 : 현직 개발자 멘토링
08/08 : 중간발표 PPT 제작
이번 주차도 기획 단게 산출물들을 마무리하고 요구사항과 ERD를 확실히 정하는 한 주였습니다.
프로젝트에서 각 역할 분담하여 개발을 진행하며, 잦은 회의를 통해 서로의 업무를 파악하며 개발 진행하고 있습니다.
개발하고, 팀원들과 의논하며 알고 있던 지식을 좀 더 깊게 이해하게 되었습니다.
특징으로 유사도 분석과 중복제거도 자연어를 이용하는 것처럼 텍스트를 토큰으로 변환 후 벡터화하여 벡터 간 거리를 계산하여 비교 분석하는 기능의 유사도 계산 방식이였습니다.
1. 파이널 프로젝트
프로젝트 진행사항
AI요약기능 (내 역할)
프롬프트 엔지니어링 설계서 작성 - 완료
타입별 프롬프트 매니저로 요약기능 활용 준비 - 완료
(추가) AI요약기능 DB에 저장 및 제한된 재생성 기능 추가
타입별 프롬프트 매니저
# app/prompt_manager.py
class PromptManager:
PROMPTS = {
"AIBOT": "기사의 핵심 내용만 3줄로 간결하게 요약해줘",
"NEWSLETTER": "카카오톡 뉴스레터용으로 핵심만 1줄로 요약해줘"
}
@classmethod
def get(cls, prompt=None, type_=None) -> str:
if prompt: return prompt
if type_ and type_.upper() in cls.PROMPTS:
return cls.PROMPTS[type_.upper()]
return cls.PROMPTS["AIBOT"]
생성형AI API 불러오기
# app/services/summarizer.py
from openai import OpenAI
from ..config import Config
_client = OpenAI(api_key=Config.OPENAI_API_KEY)
def summarize(text: str, prompt: str) -> str:
resp = _client.chat.completions.create(
model=Config.OPENAI_MODEL,
messages=[
{"role": "system", "content": "당신은 뉴스 요약 전문가입니다."},
{"role": "user", "content": f"{prompt}\n\n{text}"},
],
temperature=0.2,
)
return resp.choices[0].message.content.strip()프런트엔드
팀원 C가 프런트엔드는 카드형 웹페이지 부분이 크롤링한 뉴스가 적용 돼 나타나는 것까지 구현됐고, 다양한 UI/UX로 마무리 단계까지 진행되었습니다.
SPA사이트(vercel)도 완료,,
백엔드
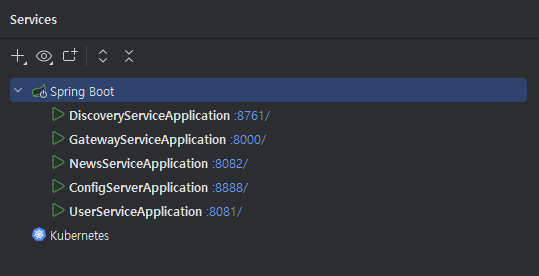
백엔드는 팀원 A가 Config 서버, Eureka(Discovery) 서버, News 서비스, User 서비스, FlaskAPI 서비스, Frontend 서비스로 나누어 총 6개의 서비스로 분리하여 포트를 설정하고 작동하는 것까지 설계하였고 정상 작동 중입니다.
크롤링
팀원이 맡은 크롤링 업무에 대해 관심을 가지며 추가적으로 공부하게 되었습니다.
강사님이 정리해주신 크롤링 코드를 통해서 팀원 B가 작성한 크롤러 기능 코드입니다.
깃허브: https://github.com/backend20250319/BE09_FINAL_1team_CRAWLER
구현 로직: Selenium(목록·URL 수집) → Jsoup(본문 파싱) → Python 중복제거 → DB 저장
2. 크롤링 (java기반 Selenium + Jsoup 혼합)
Java 기반 크롤링
Selenium
원래는 웹 애플리케이션 UI 테스트 자동화 도구였지만, 현재는 브라우저를 실제로 띄워서 동작을 흉내 내는 크롤링 도구로도 널리 사용된다고 합니다.
로직 및 특징
실제 브라우저를 띄워서 동작 -> 자바스크립트 렌더링 -> 버튼 클릭 -> 렌더링 완료 후, DOM 요소를 찾아 데이터 추출
- 스크롤 등 동적 페이지 처리 가능
- 속도는 Jsoup보다 느림
Jsoup
HTML을 파싱하고 DOM을 탐색 및 수정할 수 있는 Java 기반 라이브러리로, 웹 페이지의 정적 HTML 소스를 가져와 원하는 데이터를 추출하는 데 널리 사용된다고 합니다.
로직 및 특징
HTML 소스 요청 → HTML 파싱 → DOM 요소 탐색(CSS Selector) → 원하는 데이터 추출
- 자바스크립트 실행 불가(정적 페이지에 적합)
- 브라우저 없이 동작하므로 Selenium보다 빠름
- CSS Selector, DOM 탐색이 간단하고 직관적
Crawling 핵심코드
// Selenium으로 카테고리별 기사 수집
String url = "https://news.naver.com/section/" + categoryCode;
driver.get(url);
while (collectedLinks.size() < targetCount) {
if (!clickMoreButton(wait)) break; // 더보기 클릭
}
// Jsoup으로 파싱
Document doc = Jsoup.parse(driver.getPageSource());
Elements articles = doc.select("#newsct div.section_latest_article ul li");
// 필터링 후 수집
for (Element article : articles) {
NewsItem newsItem = extractNewsItem(article); // 제목, 링크, 언론사 추출
if (newsItem != null && collectedLinks.add(newsItem.link)) batch.add(newsItem);
}
// CSV 저장
saveToCsv(batch, categoryCode);
Python 활용 유사도 분석
기본 유사도분석 및 중복제거 로직
각 카테고리별로 뉴스 제목에 대해 유사도 분석을 수행한 뒤, 동일 기사로 의심되는 후보군에 대해서는 본문 유사도를 추가 분석
토큰화 및 전처리
import re
import pandas as pd
from preprocess_config import okt, STOPWORDS, IMPORTANT_KEYWORDS
def preprocess_titles(text):
if pd.isna(text):
return ''
text = str(text)
text = re.sub(r'[^\w\s]', ' ', text) # 특수문자 제거
text = re.sub(r'\d+', '', text) # 숫자 제거
text = re.sub(r'\s+', ' ', text).strip() # 공백 정리
# 형태소 분석
tokens = okt.nouns(text) # 명사 추출
tokens = [
t for t in tokens
if (len(t) > 1 or t in IMPORTANT_KEYWORDS) and t not in STOPWORDS # 불용어 제거 + 1글자 필터링
]
return ' '.join(tokens)유사도 분석
# ----- 제목 전처리 -----
df['clean_title'] = df['title'].apply(preprocess_titles)
# ----- 제목 기반 유사 그룹 생성 -----
groups, title_similar_pairs = build_title_similarity_groups(df, threshold=THRESHOLD_TITLE)
print(f"\n🔗 유사 그룹 수: {len(groups)}")
# 제목 유사도 출력
print("\n📌 제목 유사도:")
for i, j, sim in title_similar_pairs:
index_i = df.index[i] + 1
index_j = df.index[j] + 1
title_i = df.iloc[i]["title"]
title_j = df.iloc[j]["title"]
print(f" - (index {index_i}, {index_j}) 제목 유사도: {sim:.4f}")
print(f" ① {title_i}")
print(f" ② {title_j}")
print ("\n")본문 유사도 분석
- 본문 유사도 분석은 SBERT 임베딩을 사용해 동의어·어순 변형까지 인식
- 각 후보군에서 평균 유사도가 가장 높은 기사를 대표로 선정
- 대표 기사와의 코사인 유사도에 따라 분류 : 0.4 이상 0.8 미만 연관 기사로 처리
(0.8 이상은 중복기사로 삭제 / 0.4 미만은 무관 기사로 삭제)
from sentence_transformers import SentenceTransformer, util
import numpy as np
from config import THRESHOLD_CONTENT, THRESHOLD_RELATED_MIN
from preprocessing_content import preprocess_content
model = SentenceTransformer("snunlp/KR-SBERT-V40K-klueNLI-augSTS")
def filter_and_pick_representative_by_content(
group, df, threshold=THRESHOLD_CONTENT, threshold_related_min=THRESHOLD_RELATED_MIN
):
log_lines = []
indices = list(group)
docs = [preprocess_content(df.loc[i, 'content']) for i in indices]
# 단일 문서는 그대로 반환
if len(indices) == 1:
return indices[0], False, "", [], []
# 임베딩 → 유사도 행렬
embeddings = model.encode(docs, convert_to_tensor=True)
sim_matrix = util.pytorch_cos_sim(embeddings, embeddings).cpu().numpy()
# 대표(중심) 선택: 행 평균 최대
row_avg = sim_matrix.mean(axis=1)
rep_pos = int(row_avg.argmax())
rep_idx = indices[rep_pos]
removed_ids = [] # 중복(삭제 대상)
related_articles = [] # (rep_idx, idx, sim)
log_lines.append(f"\n➡️ 본문 유사도 그룹: {[i + 1 for i in sorted(indices)]}")
for pos, idx in enumerate(indices):
if idx == rep_idx:
continue
sim = float(sim_matrix[pos, rep_pos])
if sim >= threshold:
removed_ids.append(idx)
elif sim >= threshold_related_min:
related_articles.append((rep_idx, idx, round(sim, 4)))
is_dup_group = len(removed_ids) > 0
return rep_idx, is_dup_group, "\n".join(log_lines), removed_ids, related_articles
TF-IDF vs SBERT 임베딩 차이점
| 구분 | TF-IDF | SBERT(문장 임베딩) |
|---|---|---|
| 방식 | 단어 등장 빈도 기반 | 사전 학습된 딥러닝 모델 기반 |
| 장점 | 구현 간단, 빠름 | 의미 이해(동의어·어순 변화) 가능 |
| 단점 | 의미 파악 불가, 단어 그대로 비교 | 모델이 무거워 속도 느릴 수 있음 |
| 결과 | 단어 중심 벡터 | 의미 중심 벡터 |
3. 마무리
> 좋았던 점과 아쉬웠던 점
팀원들과 소통이 원활하게 되면서 트러블슈팅도 보다 빠르게 해결이 되서 좋았습니다.
그리고 관련된 일들을 묶어서 처리하니 빠르게 마무리 할 수 있었습니다.
> 개선할 점
기존처럼 팀원들과의 소통에 신경쓰고, 시간을 잘 조율할 필요가 있어보입니다.
> 다음주 계획
- SQLD 하루 30분 개념 공부 (1.5주 남음)
08/13 : 중간 발표
08/23 : SQLD 자격증 시험
