아직 많이 부족하지만 실전을 통해 체득한 지식과 노하우를 기록해보려고 합니다. 잘못된 내용이 있다면 지적도 부탁드립니다! 🤚
✍ 이번 포스팅의 목적
요즘 시계열 예측을 LSTM으로 시도해보고 있습니다. 늘 하면서 느끼지만 하나의 모듈로 만들어 놓지 않으면 직성이 안 풀리는 성격인지라(대체 왜 그런 걸까?🤔) 만들어 놓은 기능을 이번 기회에 정리해 보려고 합니다. LSTM(RNN)의 개념은 이미 많은 자료에서 소개되고 있으므로 생략하고, 단변량(univariate)뿐만 아니라 다변량(multivariate)에서도 활용할 수 있는 LSTM Neural Network 시계열 예측 모듈 구현 과정을 공유해 보겠습니다.
🕰 LSTM 시계열 예측
딥러닝으로 시계열 예측을 한다면 LSTM이 뼈대가 되는 게 일반적이고 여기에 CNN을 추가하여 CNN-LSTM 등으로 확장된 네트워크 구조로 여러 실험을 진행하는 초석이 된다고 보면 될 것 같습니다. 물론 딥러닝 기반의 시계열 예측이라고 해서 일반적인 모델링 과정과 크게 다르지 않습니다.
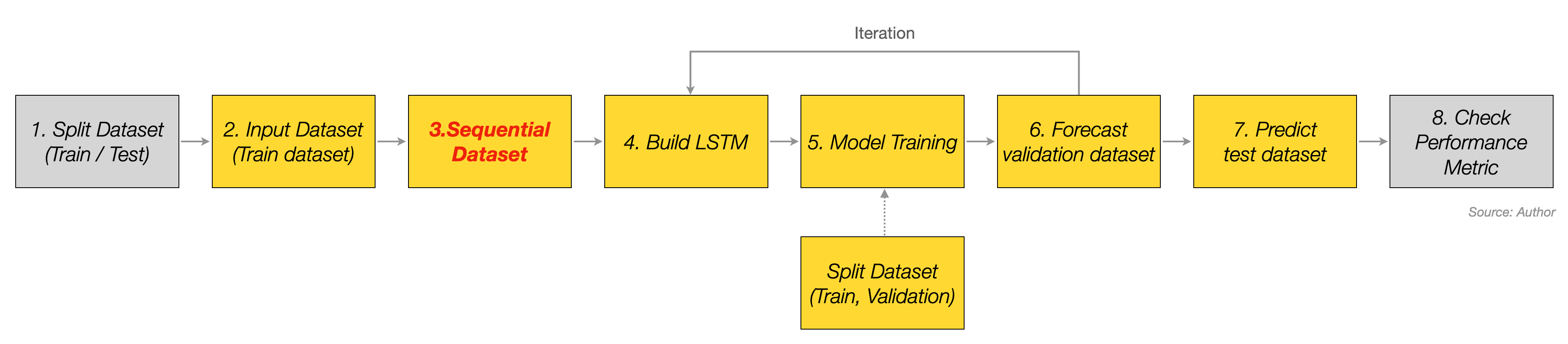
사진의 3번에 해당하는 Sequential Dataset으로 모델을 학습시킨다는 것이 핵심인데, 이 Sequence Data 모양에 따라 학습 결과가 상당히 달라질 수 있습니다. 이처럼 Sequence Data 형태에 따라 모델 성능을 확인해야 하므로 Sequence 길이가 하나의 하이퍼파라미터인 셈이며 이것 말고도 노란색 박스로 표시된 부분을 모두 진행해야 제대로된 모델링을 했다고 볼 수 있습니다.
이 과정을 수행할 수 있는 코드를 소개할 거라 아마도 글이 길어질 것 같습니다. 그래서 두 편으로 나누어 포스팅할 것인데, 여기서는 6번까지만 설명하고 나머지는 다음 게시글에서 이어서 써보려고 합니다.
⛓ Sequential Dataset
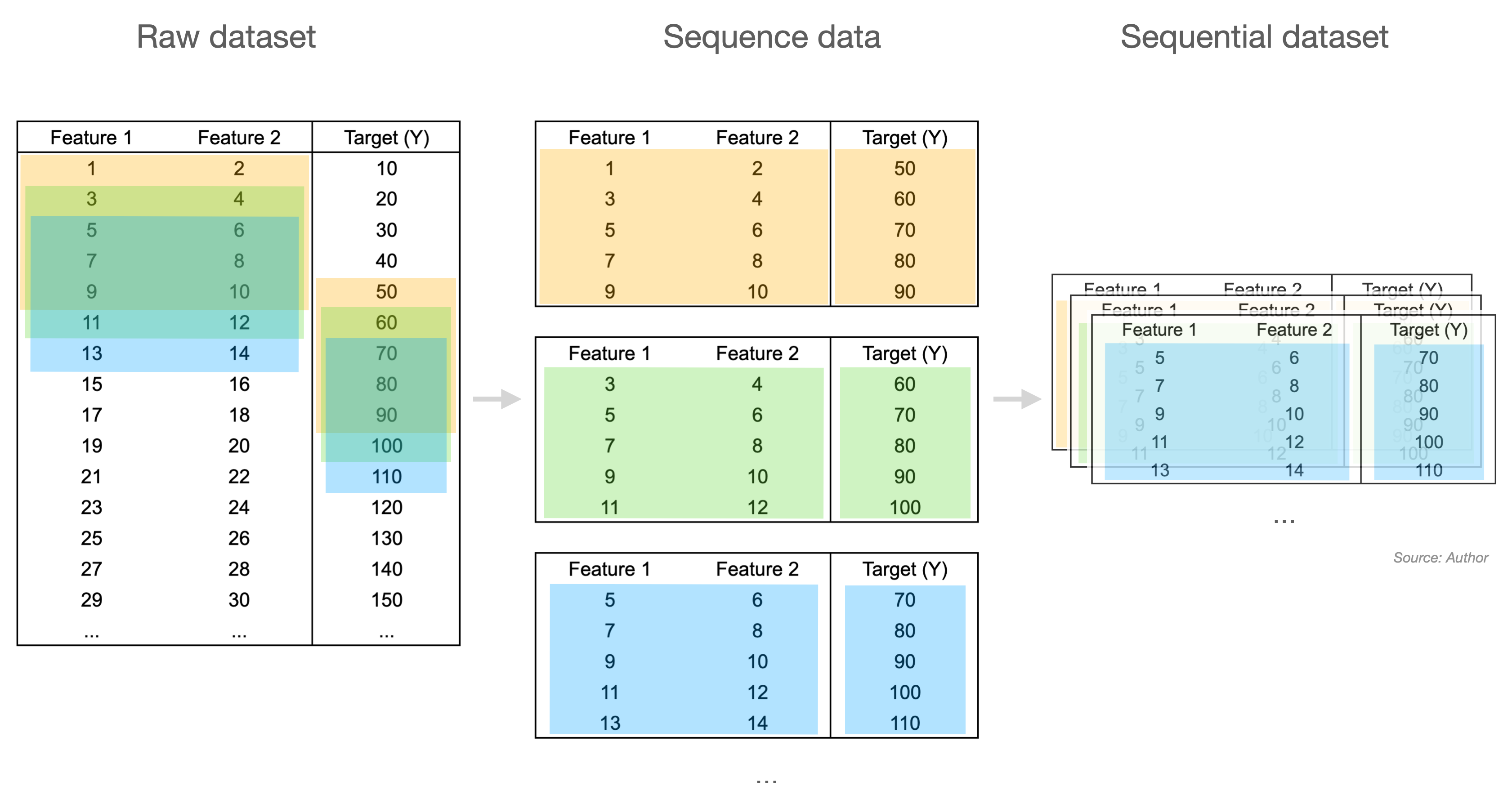
Sequential Dataset을 부연 설명하자면, 예측에 사용할 Feature의 길이(Sequence Length)와 예측할 길이(Step)에 따라 연속된 Sequence Data를 만들어내고 이것을 합친 Dataset을 생성하는 것입니다. 사진의 예시에서 Sequence Length는 5, Step도 5가 되는 것이죠. 보통 Sequence Length보다는 Window Size라는 표현을 많이 사용하지만 여기에서는 직관적인 단어로 사용하겠습니다. 😅
💻 모듈 소개
전체 코드를 한 블록에 붙여 넣으면 가독성이 떨어질 것 같아서 각 기능을 하나의 클래스에 담아내는 방식으로 작성했습니다. 그래서 위에서 설명한 모델링 순서대로 적어봤는데, 혹시 보시는 분 중 댓글로 의견 남겨주시면 적극 반영하여 수정하겠습니다! 🙆♂️
클래스 생성
먼저 필요한 라이브러리를 호출하고 클래스를 하나 만들어 줍니다. 생성자에는 굳이 다른 attribute를 미리 선언해 놓진 않았고 보기 좋게(?) random_seed만 선언 해봤습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Activation
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MSE
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import ReduceLROnPlateau
class ForecastLSTM:
def __init__(self, random_seed: int = 1234):
self.random_seed = random_seedInput Dataset
해당 모듈에서는 Raw Dataset이 Pandas DataFrame인 경우를 가정했는데, 많은 데이터 분석가와 데이터 과학자가 이것으로 데이터를 핸들링하는 것에 기반하여 만들었습니다. 저 역시도 그렇고요!
또, 예측할 값의 컬럼의 이름을 y로 고정했는데요, 시계열에서 예측할 값을 일반적으로 y로 사용하는 것에 기반한 것입니다. 필요하다면 DataFrame의 컬럼명을 검사하는 Validator 함수를 넣으려고 했으니 굳이 추가하진 않았습니다. 이 함수를 통해 Sequential Dataset 생성에 필요한 Numpy Array로 변환합니다.
def reshape_dataset(self, df: pd.DataFrame) -> np.array:
# y 컬럼을 데이터프레임의 맨 마지막 위치로 이동
if "y" in df.columns:
df = df.drop(columns=["y"]).assign(y=df["y"])
else:
raise KeyError("Not found target column 'y' in dataset.")
# shape 변경
dataset = df.values.reshape(df.shape)
return dataset
ForecastLSTM.reshape_dataset = reshape_datasetSequential Dataset
변환된 데이터셋으로 Sequence Length와 Step에 따라 Sequence Data를 만든 후 이것을 합친 Dataset을 생성하여 반환하는 함수입니다.
def split_sequences(
self, dataset: np.array, seq_len: int, steps: int, single_output: bool
) -> tuple:
# feature와 y 각각 sequential dataset을 반환할 리스트 생성
X, y = list(), list()
# sequence length와 step에 따라 sequential dataset 생성
for i, _ in enumerate(dataset):
idx_in = i + seq_len
idx_out = idx_in + steps
if idx_out > len(dataset):
break
seq_x = dataset[i:idx_in, :-1]
if single_output:
seq_y = dataset[idx_out - 1 : idx_out, -1]
else:
seq_y = dataset[idx_in:idx_out, -1]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
ForecastLSTM.split_sequences = split_sequences여기서 single_output=True은 예측할 값이 한개인 경우를 의미합니다. 만약 step=5이면서 single_output=True라면 아래의 Sequential Dataset이 만들어지는 것입니다.
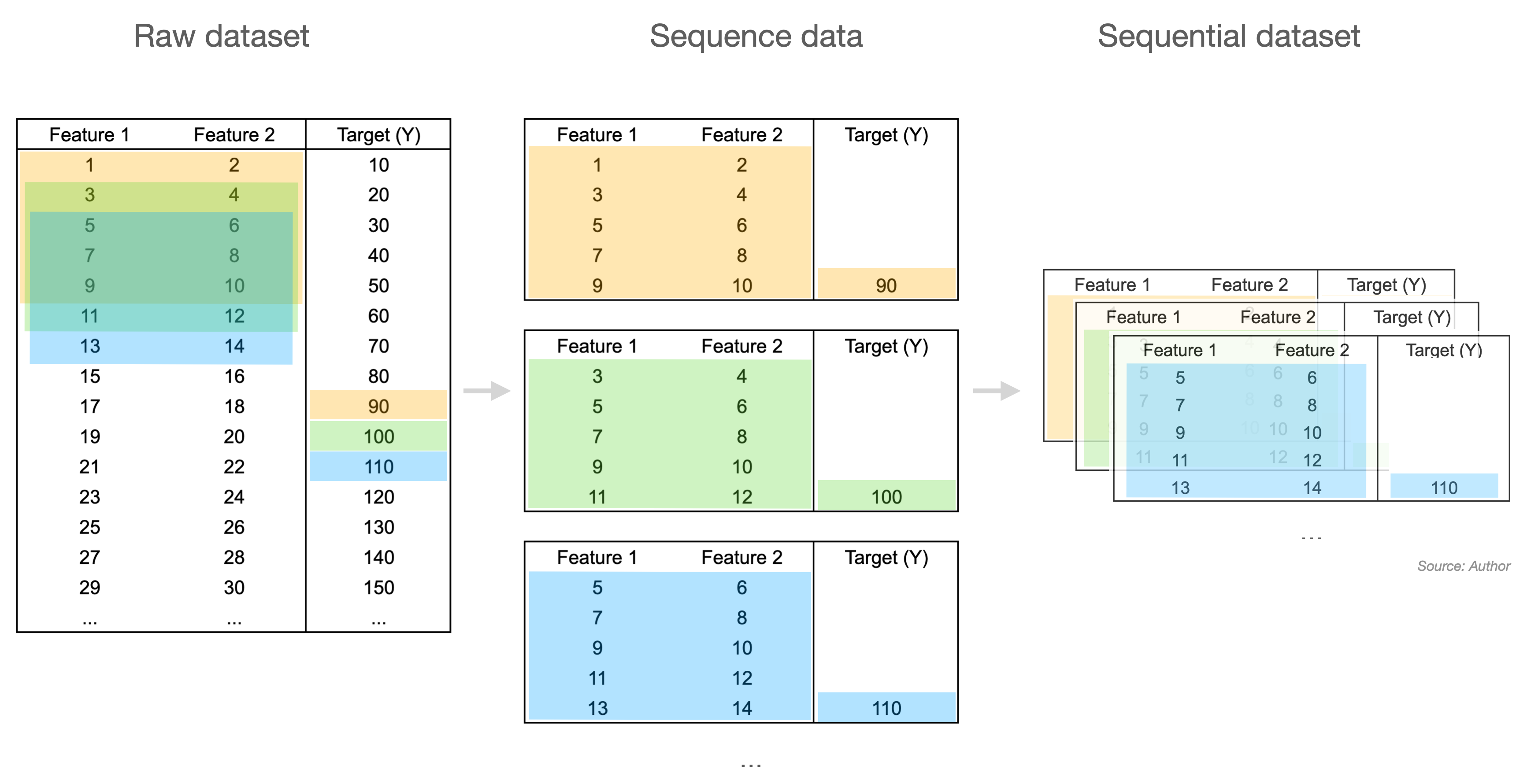
Split Dataset
시퀀스 데이터셋으로부터 모델 훈련에 사용할 Train dataset, Validation dataset을 분리하는 함수를 따로 추가해 줍니다.
def split_train_valid_dataset(
self,
df: pd.DataFrame,
seq_len: int,
steps: int,
single_output: bool,
validation_split: float = 0.3,
verbose: bool = True,
) -> tuple:
# dataframe을 numpy array로 reshape
dataset = self.reshape_dataset(df=df)
# feature와 y를 sequential dataset으로 분리
X, y = self.split_sequences(
dataset=dataset,
seq_len=seq_len,
steps=steps,
single_output=single_output,
)
# X, y에서 validation dataset 분리
dataset_size = len(X)
train_size = int(dataset_size * (1 - validation_split))
X_train, y_train = X[:train_size, :], y[:train_size, :]
X_val, y_val = X[train_size:, :], y[train_size:, :]
if verbose:
print(f" >>> X_train: {X_train.shape}")
print(f" >>> y_train: {y_train.shape}")
print(f" >>> X_val: {X_val.shape}")
print(f" >>> y_val: {y_val.shape}")
return X_train, y_train, X_val, y_val
ForecastLSTM.split_train_valid_dataset = split_train_valid_datasetBuild LSTM
LSTM 모델을 생성하고 Dense layer의 Unit과 Dropout을 원하는만큼 이어붙일 수 있도록 설계했습니다. 또한, LSTM()에서 return_sequences=True 혹은 return_sequences=False 파라미터를 선택할 수 있도록 변경하면 더욱 좋습니다.
문제 정의에 따라 다르지만, 예측 기간이 길면서 Multi Output을 산출해야 하는 모델이라면 many-to-many 방식으로 가중치를 갱신하는 return_sequences=True를 지정하는 것도 좋은 방법입니다.
(return_sequences의 자세한 이해는 이 게시글을 추천합니다!)
def build_and_compile_lstm_model(
self,
seq_len: int,
n_features: int,
lstm_units: list,
learning_rate: float,
dropout: float,
steps: int,
metrics: str,
single_output: bool,
last_lstm_return_sequences: bool = False,
dense_units: list = None,
activation: str = None,
):
"""
LSTM 네트워크를 생성한 결과를 반환한다.
:param seq_len: Length of sequences. (Look back window size)
:param n_features: Number of features. It requires for model input shape.
:param lstm_units: Number of cells each LSTM layers.
:param learning_rate: Learning rate.
:param dropout: Dropout rate.
:param steps: Length to predict.
:param metrics: Model loss function metric.
:param single_output: Whether 'yhat' is a multiple value or a single value.
:param last_lstm_return_sequences: Last LSTM's `return_sequences`. Allow when `single_output=False` only.
:param dense_units: Number of cells each Dense layers. It adds after LSTM layers.
:param activation: Activation function of Layers.
"""
tf.random.set_seed(self.random_seed)
model = Sequential()
if len(lstm_units) > 1:
# LSTM -> ... -> LSTM -> Dense(steps)
model.add(
LSTM(
units=lstm_units[0],
activation=activation,
return_sequences=True,
input_shape=(seq_len, n_features),
)
)
lstm_layers = lstm_units[1:]
for i, n_units in enumerate(lstm_layers, start=1):
if i == len(lstm_layers):
if single_output:
return_sequences = False
else:
return_sequences = last_lstm_return_sequences
model.add(
LSTM(
units=n_units,
activation=activation,
return_sequences=return_sequences,
)
)
else:
model.add(
LSTM(
units=n_units,
activation=activation,
return_sequences=True,
)
)
else:
# LSTM -> Dense(steps)
if single_output:
return_sequences = False
else:
return_sequences = last_lstm_return_sequences
model.add(
LSTM(
units=lstm_units[0],
activation=activation,
return_sequences=return_sequences,
input_shape=(seq_len, n_features),
)
)
if single_output: # Single Step, Direct Multi Step
if dense_units:
for n_units in dense_units:
model.add(Dense(units=n_units, activation=activation))
if dropout > 0:
model.add(Dropout(rate=dropout))
model.add(Dense(1))
else: # Multiple Output Step
if last_lstm_return_sequences:
model.add(Flatten())
if dense_units:
for n_units in dense_units:
model.add(Dense(units=n_units, activation=activation))
if dropout > 0:
model.add(Dropout(rate=dropout))
model.add(Dense(units=steps))
# Compile the model
optimizer = Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss=MSE, metrics=metrics)
return model
ForecastLSTM.build_and_compile_lstm_model = build_and_compile_lstm_modelModel Training
이제 위에서 추가한 함수들을 호출하여 모델을 훈련하는 기능입니다. 이 부분이 사실상 메인에 해당하다 보니 함수에 파라미터가 많습니다 😅. 조금 복잡해 보이지만 구분해보면 딱 필요한 것(?)만 들어있습니다.
- LSTM 모델 하이퍼라라미터
- 훈련 데이터셋
- Sequence Data 길이 (
Sequence Length) - 예측 기간 (
Step)
def fit_lstm(
self,
df: pd.DataFrame,
steps: int,
lstm_units: list,
activation: str,
dropout: float = 0,
seq_len: int = 16,
single_output: bool = False,
epochs: int = 200,
batch_size: int = None,
steps_per_epoch: int = None,
learning_rate: float = 0.001,
patience: int = 10,
validation_split: float = 0.3,
last_lstm_return_sequences: bool = False,
dense_units: list = None,
metrics: str = "mse",
check_point_path: str = None,
verbose: bool = False,
plot: bool = True,
):
"""
LSTM 기반 모델 훈련을 진행한다.
:param df: DataFrame for model train.
:param steps: Length to predict.
:param lstm_units: LSTM, Dense Layers
:param activation: Activation function for LSTM, Dense Layers.
:param dropout: Dropout ratio between Layers.
:param seq_len: Length of sequences. (Look back window size)
:param single_output: Select whether 'y' is a continuous value or a single value.
"""
np.random.seed(self.random_seed)
tf.random.set_seed(self.random_seed)
# 훈련, 검증 데이터셋 생성
(
self.X_train,
self.y_train,
self.X_val,
self.y_val,
) = self.split_train_valid_dataset(
df=df,
seq_len=seq_len,
steps=steps,
validation_split=validation_split,
single_output=single_output,
verbose=verbose,
)
# LSTM 모델 생성
n_features = df.shape[1] - 1
self.model = self.build_and_compile_lstm_model(
seq_len=seq_len,
n_features=n_features,
lstm_units=lstm_units,
activation=activation,
learning_rate=learning_rate,
dropout=dropout,
steps=steps,
last_lstm_return_sequences=last_lstm_return_sequences,
dense_units=dense_units,
metrics=metrics,
single_output=single_output,
)
# 모델 적합 과정에서 best model 저장
if check_point_path is not None:
# create checkpoint
checkpoint_path = f"checkpoint/lstm_{check_point_path}.h5"
checkpoint = ModelCheckpoint(
filepath=checkpoint_path,
save_weights_only=False,
save_best_only=True,
monitor="val_loss",
verbose=verbose,
)
rlr = ReduceLROnPlateau(
monitor="val_loss", factor=0.5, patience=patience, verbose=verbose
)
callbacks = [checkpoint, EarlyStopping(patience=patience), rlr]
else:
rlr = ReduceLROnPlateau(
monitor="val_loss", factor=0.5, patience=patience, verbose=verbose
)
callbacks = [EarlyStopping(patience=patience), rlr]
# 모델 훈련
self.history = self.model.fit(
self.X_train,
self.y_train,
batch_size=batch_size,
steps_per_epoch=steps_per_epoch,
validation_data=(self.X_val, self.y_val),
epochs=epochs,
use_multiprocessing=True,
workers=8,
verbose=verbose,
callbacks=callbacks,
shuffle=False,
)
# 훈련 종료 후 best model 로드
if check_point_path is not None:
self.model.load_weights(f"checkpoint/lstm_{check_point_path}.h5")
# 모델링 과정 시각화
if plot:
plt.figure(figsize=(12, 6))
plt.plot(self.history.history[f"{metrics}"])
plt.plot(self.history.history[f"val_{metrics}"])
plt.title("Performance Metric")
plt.xlabel("Epoch")
plt.ylabel(f"{metrics}")
if metrics == "mape":
plt.axhline(y=10, xmin=0, xmax=1, color="grey", ls="--", alpha=0.5)
plt.legend(["Train", "Validation"], loc="upper right")
plt.show()
ForecastLSTM.fit_lstm = fit_lstmForecast validation dataset
훈련 종료 이후 검증 데이터셋에 대한 예측 결과를 반환하는 함수도 필요합니다. Epochs에 따라 Validation Dataset의 Loss를 확인할 수 있지만, 검증 데이터셋에 대한 실제 값과 예측값으로부터 오차를 확인할 필요가 있기 때문입니다. 이 오차(Performance Metric)에 의해 최적의 하이퍼파라미터를 찾을 수 있게 되고, 최적의 모델로부터 Test Dataset 예측을 통해 최종 성능을 기록하는 과정을 수행해야 합니다.
def forecast_validation_dataset(self) -> pd.DataFrame:
# 검증 데이터셋의 실제 값(y)과, 예측 값(yhat)을 저장할 리스트 생성
y_pred_list, y_val_list = list(), list()
# 훈련된 모델로 validation dataset에 대한 예측값 생성
for x_val, y_val in zip(self.X_val, self.y_val):
x_val = np.expand_dims(
x_val, axis=0
) # (seq_len, n_features) -> (1, seq_len, n_features)
y_pred = self.model.predict(x_val)[0]
y_pred_list.extend(y_pred.tolist())
y_val_list.extend(y_val.tolist())
return pd.DataFrame({"y": y_val_list, "yhat": y_pred_list})
ForecastLSTM.forecast_validation_dataset = forecast_validation_datasetPerformance Metric
예측 결과로부터 오차를 확인할 수 있는 함수를 하나 만들어 두면 좋습니다. 이것까지 클래스에 넣기 보다는 evaluation 용도로 따로 분리하는 게 적절한 것 같습니다. 아주 간단하게 만든 버전이고, mase, coverage, winkler score 등을 계산하는 것도 추가하면 좋습니다.
def calculate_metrics(df_fcst: pd.DataFrame) -> dict:
true = df_fcst["y"]
pred = df_fcst["yhat"]
mae = (true - pred).abs().mean()
mape = (true - pred).abs().div(true).mean() * 100
mse = ((true - pred) ** 2).mean()
return {
"mae": mae,
"mape": mape,
"mse": mse,
}🤔 활용 예시
주(week) 단위의 시계열 데이터셋이 있다고 가정하고, 여기까지 소개한 코드를 사용한다면 아래와 같은 느낌입니다.
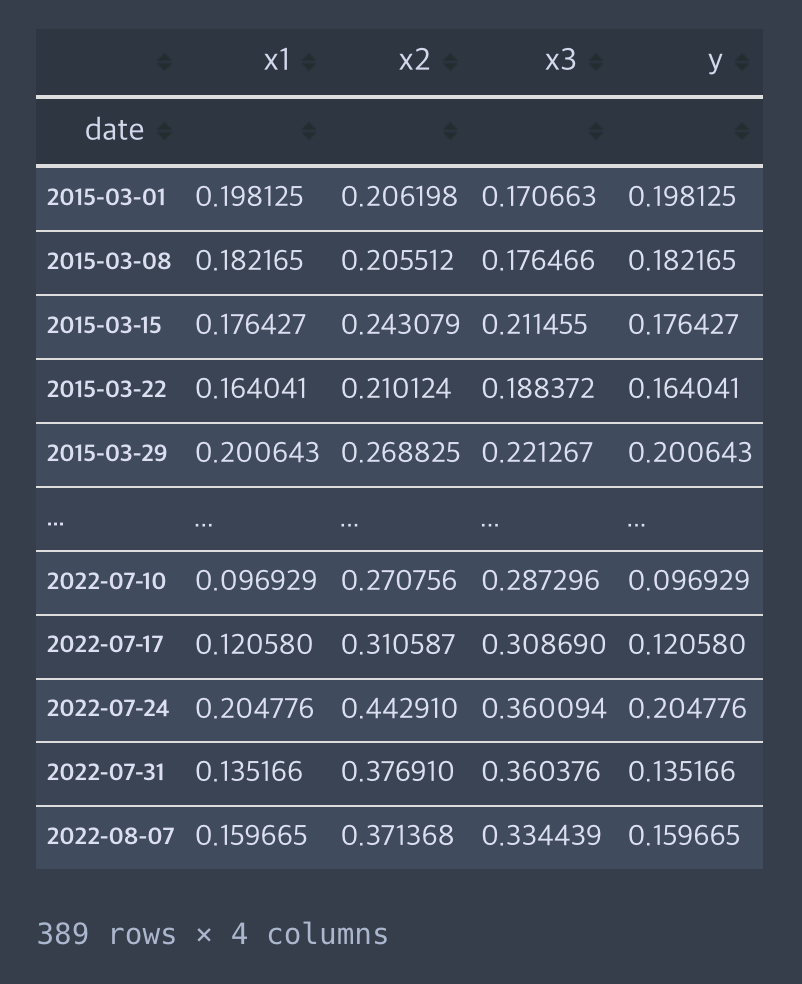
## 1) Train, Test 데이터 분리
cutoff = "2022-01-01"
df_train = df[df.index < cutoff]
df_test = df[df.index >= cutoff]
## 2) Sequence Length, 예측 기간(Step), Single Output 여부 등 정의
seq_len = 5 # 과거 5주의 데이터를 feature로 사용
steps = 5 # 향후 5주의 y를 예측
single_output = False # 향후 5주차의 시점만이 아닌, 1~5주 모두 예측
metrics = "mse" # 모델 성능 지표
## 3) LSTM 하이퍼파라미터 정의
lstm_params = {
"seq_len": seq_len,
"epochs": 300, # epochs 반복 횟수
"patience": 30, # early stopping 조건
"steps_per_epoch": 5, # 1 epochs 시 dataset을 5개로 분할하여 학습
"learning_rate": 0.01,
"lstm_units": [64, 32], # Dense Layer: 2, Unit: (64, 32)
"activation": "relu",
"dropout": 0,
"validation_split": 0.3, # 검증 데이터셋 30%
}
## 4) 모델 훈련
fl = ForecastLSTM()
fl.fit_lstm(
df=df_train,
steps=steps,
single_output=single_output,
metrics=metrics,
**lstm_params,
)
## 5) Validation dataset 예측 성능
df_fcst_val = fl.forecast_validation_dataset()
val_loss = calculate_metrics(df_fcst=df_fcst_val)[metrics]
print(f"{metrics} of validation dataset: {val_loss.round(3)}")이 코드를 실행하면 아래와 같이 모델 성능을 바로 확인할 수 있으며, 이러한 구조를 토대로 하이퍼파라미터 튜닝 코드까지 개발하여 진행한다면 LSTM 시계열 모델링은 어렵지 않게 할 수 있습니다. (참 쉽죠?)
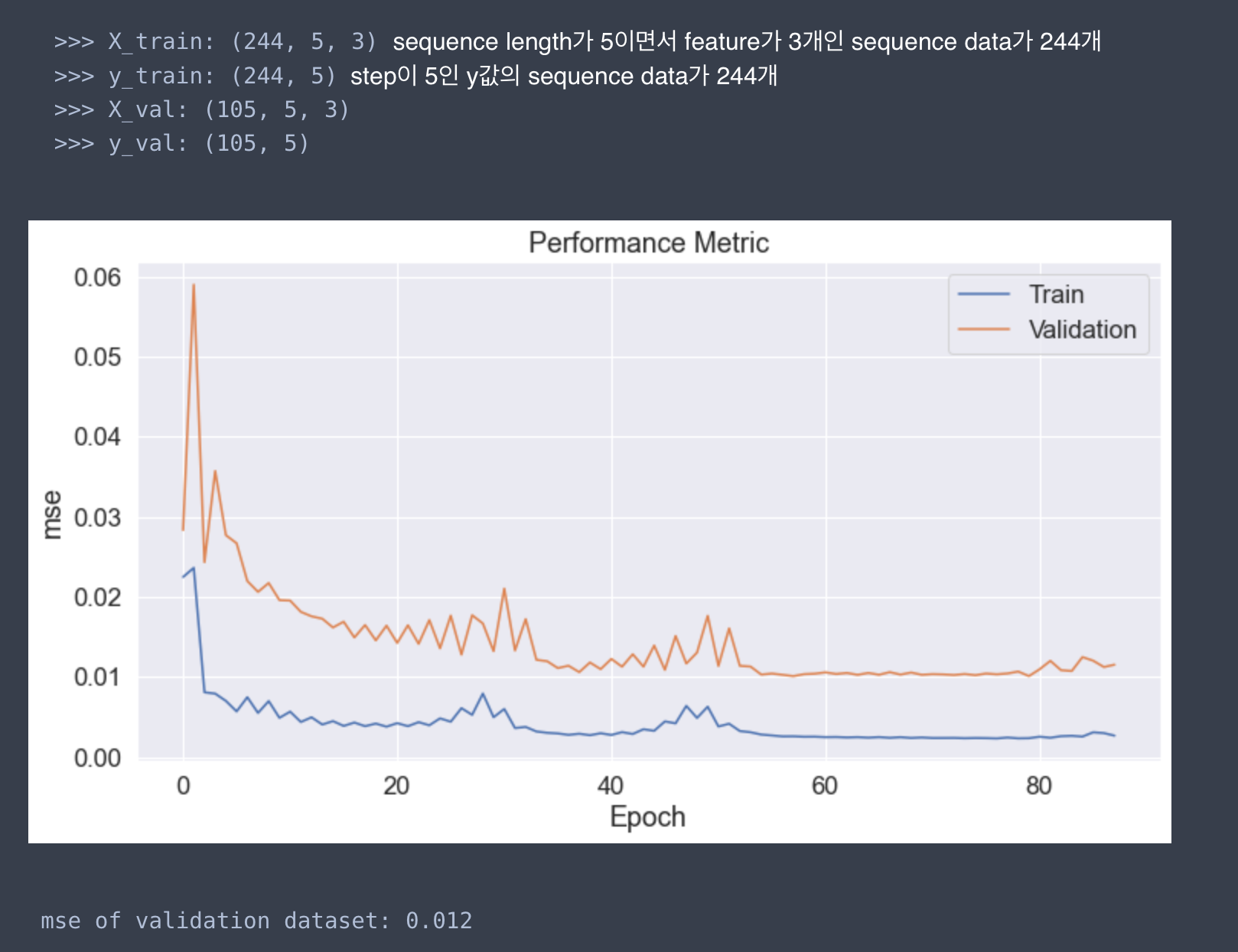
여기까지가 모델 훈련을 위한 코드입니다. 이후엔 Test Dataset로 예측값과 실제값을 비교하여 모델의 최종 성능을 일반화할 수 있습니다. 다음 편에서 최종 성능 측정 과정을 소개하여 매듭을 지어보겠습니다.
⌛ 1편 마무리
LSTM을 사용한 시계열 예측 활용 사례를 찾아보면 Quick Start 수준에 머물러있는 느낌을 많이 받았습니다. 그래서 이번 글을 통해 LSTM 모델링을 추상화된 함수로 구현하여 용이하게 사용할 수 있는 사례를 공유해 보고자 작성해 봤습니다. (물론 이것도 거의 vanilla version에 해당하는 수준이긴 하지만..😇)
1편은 코드 기반의 설명이 주를 이었는데, 2편에서는 모델링 시 유의해야 할 점과 알면 좋을 것들에 대한 내용도 추가로 작성할 예정입니다!

13개의 댓글

안녕하세요! 덕분에 LSTM 모델을 이해, 설계, 학습하는 부분까지 많은 도움을 받았습니다!
해당 모델을 활용하는 방안에서 다변량으로 구성된 test_data 셋의 features 를 가지고 값을 예측하고 예측값과 test_data에 존재하는 실측값을 바탕으로 모델 성능 측정까지 모두 완료 해봤습니다.
그런데 해당 학습 모델로 제가 하고 싶었던 부분은 향후 미래의 (test_data 셋 이상의 미래) 값을 예측하고자 했던 것인데, 모델의 input값을 맞춰주기 위해 sequence를 만드는 과정에서 n_feature이 필수로 들어가게 됩니다.
미래의 x1,x2,x3와 같은 특성값을 갖고 있지 못할 때, 예를 들어 향후 3개월의 특성 값들을 갖고 있지 못할 때 이를 예측하는 방법이 전혀 없는 걸까요?



fit_lstm
self.model = self.build_and_compile_lstm_model(
이 부분에서
The added layer must be an instance of class Layer. Found: 혹시 이런 에러가 뜨는데 조치방법을 알수 있을까요 ?
안녕하세요. LSTM 모델과 관련하여 정리를 잘 해주셔서 참고자료로 활용하여 현재 데이터 모델링 진행 중입니다. Test set으로 모델 평가를 하고 싶은데 혹시 평가 부분에 대한 알 수 없을까요? 감사합니다.